本文主要是介绍[Paddle2.0学习之第四步](上)词向量之skip-gram,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[Paddle2.0学习之第四步]词向量之skip-gram
项目在aistudio:
[Paddle2.0学习之第四步](上)词向量之skip-gram
文章目录
- [Paddle2.0学习之第四步]词向量之skip-gram
- 2. 使用paddle2.0实现skip-gram
- 2.1 数据处理
- 2.2 定义skip-gram网络
- 2.3 网络训练
- 总结
如 图 所示,Skip-gram是一个具有3层结构的神经网络,分别是:
1. Skip-gram的算法实现
我们以这句话:“Pineapples are spiked and yellow”为例介绍Skip-gram的算法实现。
- 输入层: 一个形状为C×V的one-hot张量,其中C代表上线文中词的个数,通常是一个偶数,我们假设为4;V表示词表大小,我们假设为5000,该张量的每一行都是一个上下文词的one-hot向量表示,比如“Pineapples, are, and, yellow”。
- 隐藏层: 一个形状为V×N的参数张量W1,一般称为word-embedding,N表示每个词的词向量长度,我们假设为128。输入张量和word embedding W1进行矩阵乘法,就会得到一个形状为C×N的张量。综合考虑上下文中所有词的信息去推理中心词,因此将上下文中C个词相加得一个1×N的向量,是整个上下文的一个隐含表示。
- 输出层: 创建另一个形状为N×V的参数张量,将隐藏层得到的1×N的向量乘以该N×V的参数张量,得到了一个形状为1×V的向量。最终,1×V的向量代表了使用上下文去推理中心词,每个候选词的打分,再经过softmax函数的归一化,即得到了对中心词的推理概率:
𝑠𝑜𝑓𝑡𝑚𝑎𝑥(Oi)=exp(Oi)∑jexp(Oj)𝑠𝑜𝑓𝑡𝑚𝑎𝑥({O_i})= \frac{exp({O_i})}{\sum_jexp({O_j})} softmax(Oi)=∑jexp(Oj)exp(Oi)
如 图 所示,Skip-gram是一个具有3层结构的神经网络,分别是:
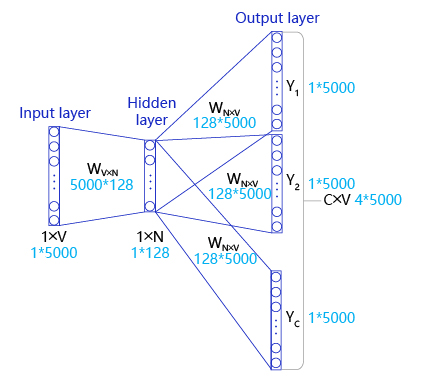
Skip-gram算法实现
- Input Layer(输入层):接收一个one-hot张量 V∈R1×vocab_sizeV \in R^{1 \times \text{vocab\_size}}V∈R1×vocab_size 作为网络的输入,里面存储着当前句子中心词的one-hot表示。
- Hidden Layer(隐藏层):将张量VVV乘以一个word embedding张量W1∈Rvocab_size×embed_sizeW_1 \in R^{\text{vocab\_size} \times \text{embed\_size}}W1∈Rvocab_size×embed_size,并把结果作为隐藏层的输出,得到一个形状为R1×embed_sizeR^{1 \times \text{embed\_size}}R1×embed_size的张量,里面存储着当前句子中心词的词向量。
- Output Layer(输出层):将隐藏层的结果乘以另一个word embedding张量W2∈Rembed_size×vocab_sizeW_2 \in R^{\text{embed\_size} \times \text{vocab\_size}}W2∈Rembed_size×vocab_size,得到一个形状为R1×vocab_sizeR^{1 \times \text{vocab\_size}}R1×vocab_size的张量。这个张量经过softmax变换后,就得到了使用当前中心词对上下文的预测结果。根据这个softmax的结果,我们就可以去训练词向量模型。
在实际操作中,使用一个滑动窗口(一般情况下,长度是奇数),从左到右开始扫描当前句子。每个扫描出来的片段被当成一个小句子,每个小句子中间的词被认为是中心词,其余的词被认为是这个中心词的上下文。
1.1 Skip-gram的理想实现
使用神经网络实现Skip-gram中,模型接收的输入应该有2个不同的tensor:
-
代表中心词的tensor:假设我们称之为center_words VVV,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中,每个中心词的ID,对应位置为1,其余为0。
-
代表目标词的tensor:目标词是指需要推理出来的上下文词,假设我们称之为target_words TTT,一般来说,这个tensor是一个形状为[batch_size, 1]的整型tensor,这个tensor中的每个元素是一个[0, vocab_size-1]的值,代表目标词的ID。
在理想情况下,我们可以使用一个简单的方式实现skip-gram。即把需要推理的每个目标词都当成一个标签,把skip-gram当成一个大规模分类任务进行网络构建,过程如下:
- 声明一个形状为[vocab_size, embedding_size]的张量,作为需要学习的词向量,记为W0W_0W0。对于给定的输入VVV,使用向量乘法,将VVV乘以W0W_0W0,这样就得到了一个形状为[batch_size, embedding_size]的张量,记为H=V×W0H=V×W_0H=V×W0。这个张量HHH就可以看成是经过词向量查表后的结果。
- 声明另外一个需要学习的参数W1W_1W1,这个参数的形状为[embedding_size, vocab_size]。将上一步得到的HHH去乘以W1W_1W1,得到一个新的tensor O=H×W1O=H×W_1O=H×W1,此时的OOO是一个形状为[batch_size, vocab_size]的tensor,表示当前这个mini-batch中的每个中心词预测出的目标词的概率。
- 使用softmax函数对mini-batch中每个中心词的预测结果做归一化,即可完成网络构建。
1.2 Skip-gram的实际实现
然而在实际情况中,vocab_size通常很大(几十万甚至几百万),导致W0W_0W0和W1W_1W1也会非常大。对于W0W_0W0而言,所参与的矩阵运算并不是通过一个矩阵乘法实现,而是通过指定ID,对参数W0W_0W0进行访存的方式获取。然而对W1W_1W1而言,仍要处理一个非常大的矩阵运算(计算过程非常缓慢,需要消耗大量的内存/显存)。为了缓解这个问题,通常采取负采样(negative_sampling)的方式来近似模拟多分类任务。此时新定义的W0W_0W0和W1W_1W1均为形状为[vocab_size, embedding_size]的张量。
假设有一个中心词ccc和一个上下文词正样本tpt_ptp。在Skip-gram的理想实现里,需要最大化使用ccc推理tpt_ptp的概率。在使用softmax学习时,需要最大化tpt_ptp的推理概率,同时最小化其他词表中词的推理概率。之所以计算缓慢,是因为需要对词表中的所有词都计算一遍。然而我们还可以使用另一种方法,就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。比如,先指定一个中心词(如“人工”)和一个目标词正样本(如“智能”),再随机在词表中采样几个目标词负样本(如“日本”,“喝茶”等)。有了这些内容,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为负采样。
在实现的过程中,通常会让模型接收3个tensor输入:
-
代表中心词的tensor:假设我们称之为center_words VVV,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
-
代表目标词的tensor:假设我们称之为target_words TTT,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
-
代表目标词标签的tensor:假设我们称之为labels LLL,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
模型训练过程如下:
- 用VVV去查询W0W_0W0,用TTT去查询W1W_1W1,分别得到两个形状为[batch_size, embedding_size]的tensor,记为H1H_1H1和H2H_2H2。
- 点乘这两个tensor,最终得到一个形状为[batch_size]的tensor O=[Oi=∑jH0[i,j]×H1[i,j]]i=1batch_sizeO = [O_i = \sum_j H_0[i,j] × H_1[i,j]]_{i=1}^{batch\_size}O=[Oi=∑jH0[i,j]×H1[i,j]]i=1batch_size。
- 使用sigmoid函数作用在OOO上,将上述点乘的结果归一化为一个0-1的概率值,作为预测概率,根据标签信息LLL训练这个模型即可。
在结束模型训练之后,一般使用W0W_0W0作为最终要使用的词向量,可以用W0W_0W0提供的向量表示。通过向量点乘的方式,计算两个不同词之间的相似度。
2. 使用paddle2.0实现skip-gram
接下来我们将学习使用飞桨实现Skip-gram模型的方法。在飞桨中,不同深度学习模型的训练过程基本一致,流程如下:
-
数据处理:选择需要使用的数据,并做好必要的预处理工作。
-
网络定义:使用飞桨定义好网络结构,包括输入层,中间层,输出层,损失函数和优化算法。
-
网络训练:将准备好的数据送入神经网络进行学习,并观察学习的过程是否正常,如损失函数值是否在降低,也可以打印一些中间步骤的结果出来等。
-
网络评估:使用测试集合测试训练好的神经网络,看看训练效果如何。
# encoding=utf8
# 首先导入后续会用到的飞桨包
import io
import os
import sys
import requests
from collections import OrderedDict
import math
import random
import numpy as np
import paddle
from paddle.nn import Embedding
import paddle.nn.functional as F
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecationsdef convert_to_list(value, n, name, dtype=np.int):
2.1 数据处理
首先,找到一个合适的语料用于训练word2vec模型。使用text8数据集,这个数据集里包含了大量从维基百科收集到的英文语料,我们可以通过如下代码下载数据集,下载后的文件被保存在当前目录的“text8.txt”文件内。
# 读取语料用来训练word2vec
def readdata():corpus_url = "data/data98805/text8.txt"with open(corpus_url, "r") as f: # 打开文件corpus = f.read().strip("\n") # 读取文件print(corpus)f.close()return corpus
corpus = readdata()
IOPub data rate exceeded.
The notebook server will temporarily stop sending output
to the client in order to avoid crashing it.
To change this limit, set the config variable
`--NotebookApp.iopub_data_rate_limit`.Current values:
NotebookApp.iopub_data_rate_limit=1000000.0 (bytes/sec)
NotebookApp.rate_limit_window=3.0 (secs)
# 打印前500个字符查看语料的格式
corpus[:250]
' anarchism originated as a term of abuse first used against early working class radicals including the diggers of the english revolution and the sans culottes of the french revolution whilst the term is still used in a pejorative way to describe any '
一般来说,在自然语言处理中,需要先对语料进行切词。对于英文来说,可以比较简单地直接使用空格进行切词,代码如下:
# 对语料进行预处理(分词)
def data_preprocess(corpus):# 由于英文单词出现在句首的时候经常要大写,所以我们把所有英文字符都转换为小写,# 以便对语料进行归一化处理(Apple vs apple等)corpus = corpus.strip().lower()corpus = corpus.split(" ")return corpuscorpus = data_preprocess(corpus)
corpus[:10]
['anarchism','originated','as','a','term','of','abuse','first','used','against']
在经过切词后,需要对语料进行统计,为每个词构造ID。一般来说,可以根据每个词在语料中出现的频次构造ID,频次越高,ID越小,便于对词典进行管理。代码如下:
# 构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数id
def build_dict(corpus):# 首先统计每个不同词的频率(出现的次数),使用一个词典记录word_freq_dict = dict()for word in corpus:if word not in word_freq_dict:word_freq_dict[word] = 0word_freq_dict[word] += 1# 将这个词典中的词,按照出现次数排序,出现次数越高,排序越靠前# 一般来说,出现频率高的高频词往往是:I,the,you这种代词,而出现频率低的词,往往是一些名词,如:nlpword_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)# 构造3个不同的词典,分别存储,# 每个词到id的映射关系:word2id_dict# 每个id出现的频率:word2id_freq# 每个id到词的映射关系:id2word_dictword2id_dict = dict()word2id_freq = dict()id2word_dict = dict()# 按照频率,从高到低,开始遍历每个单词,并为这个单词构造一个独一无二的idfor word, freq in word_freq_dict:curr_id = len(word2id_dict)word2id_dict[word] = curr_idword2id_freq[word2id_dict[word]] = freqid2word_dict[curr_id] = wordreturn word2id_freq, word2id_dict, id2word_dictword2id_freq, word2id_dict, id2word_dict = build_dict(corpus)
vocab_size = len(word2id_freq)
# 总共有多少的词 按照频率打印前十个进行查看
print("there are totoally %d different words in the corpus" % vocab_size)
for _, (word, word_id) in zip(range(10), word2id_dict.items()):print("word %s, its id %d, its word freq %d" % (word, word_id, word2id_freq[word_id]))
there are totoally 253854 different words in the corpus
word the, its id 0, its word freq 1061396
word of, its id 1, its word freq 593677
word and, its id 2, its word freq 416629
word one, its id 3, its word freq 411764
word in, its id 4, its word freq 372201
word a, its id 5, its word freq 325873
word to, its id 6, its word freq 316376
word zero, its id 7, its word freq 264975
word nine, its id 8, its word freq 250430
word two, its id 9, its word freq 192644
得到word2id词典后,还需要进一步处理原始语料,把每个词替换成对应的ID,便于神经网络进行处理,代码如下:
# 把语料转换为id序列
def convert_corpus_to_id(corpus, word2id_dict):# 使用一个循环,将语料中的每个词替换成对应的id,以便于神经网络进行处理corpus = [word2id_dict[word] for word in corpus]return corpuscorpus = convert_corpus_to_id(corpus, word2id_dict)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:20])
17005207 tokens in the corpus
[5233, 3080, 11, 5, 194, 1, 3133, 45, 58, 155, 127, 741, 476, 10571, 133, 0, 27349, 1, 0, 102]
接下来,需要使用二次采样法处理原始文本。二次采样法的主要思想是降低高频词在语料中出现的频次。方法是随机将高频的词抛弃,频率越高,被抛弃的概率就越大;频率越低,被抛弃的概率就越小。标点符号或冠词这样的高频词就会被抛弃,从而优化整个词表的词向量训练效果,代码如下:
# 使用二次采样算法(subsampling)处理语料,强化训练效果
def subsampling(corpus, word2id_freq):# 这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同# 如果一个词的频率很大,那么它被遗弃的概率就很大def discard(word_id):return random.uniform(0, 1) < 1 - math.sqrt(1e-4 / word2id_freq[word_id] * len(corpus))corpus = [word for word in corpus if not discard(word)]return corpuscorpus = subsampling(corpus, word2id_freq)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:20])
8743210 tokens in the corpus
[5233, 3080, 194, 3133, 58, 127, 741, 476, 10571, 133, 27349, 854, 15067, 58112, 854, 3580, 194, 190, 58, 10712]
在完成语料数据预处理之后,需要构造训练数据。根据上面的描述,我们需要使用一个滑动窗口对语料从左到右扫描,在每个窗口内,中心词需要预测它的上下文,并形成训练数据。
在实际操作中,由于词表往往很大(50000,100000等),对大词表的一些矩阵运算(如softmax)需要消耗巨大的资源,因此可以通过负采样的方式模拟softmax的结果。
- 给定一个中心词和一个需要预测的上下文词,把这个上下文词作为正样本。
- 通过词表随机采样的方式,选择若干个负样本。
- 把一个大规模分类问题转化为一个2分类问题,通过这种方式优化计算速度。
# 构造数据,准备模型训练
# max_window_size代表了最大的window_size的大小,程序会根据max_window_size从左到右扫描整个语料
# negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,
# 一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
def build_data(corpus, word2id_dict, word2id_freq, max_window_size = 3, negative_sample_num = 4):# 使用一个list存储处理好的数据dataset = []# 从左到右,开始枚举每个中心点的位置for center_word_idx in range(len(corpus)):# 以max_window_size为上限,随机采样一个window_size,这样会使得训练更加稳定window_size = random.randint(1, max_window_size)# 当前的中心词就是center_word_idx所指向的词center_word = corpus[center_word_idx]# 以当前中心词为中心,左右两侧在window_size内的词都可以看成是正样本positive_word_range = (max(0, center_word_idx - window_size), min(len(corpus) - 1, center_word_idx + window_size))positive_word_candidates = [corpus[idx] for idx in range(positive_word_range[0], positive_word_range[1]+1) if idx != center_word_idx]# 对于每个正样本来说,随机采样negative_sample_num个负样本,用于训练for positive_word in positive_word_candidates:# 首先把(中心词,正样本,label=1)的三元组数据放入dataset中,# 这里label=1表示这个样本是个正样本dataset.append((center_word, positive_word, 1))# 开始负采样i = 0while i < negative_sample_num:negative_word_candidate = random.randint(0, vocab_size-1)if negative_word_candidate not in positive_word_candidates:# 把(中心词,正样本,label=0)的三元组数据放入dataset中,# 这里label=0表示这个样本是个负样本dataset.append((center_word, negative_word_candidate, 0))i += 1return dataset
corpus_light = corpus[:int(len(corpus)*0.2)]
dataset = build_data(corpus_light, word2id_dict, word2id_freq)
for _, (center_word, target_word, label) in zip(range(25), dataset):print("center_word %s, target %s, label %d" % (id2word_dict[center_word],id2word_dict[target_word], label))
center_word anarchism, target originated, label 1
center_word anarchism, target fleetfahrt, label 0
center_word anarchism, target aoral, label 0
center_word anarchism, target chiles, label 0
center_word anarchism, target hiero, label 0
center_word originated, target anarchism, label 1
center_word originated, target picene, label 0
center_word originated, target reichenberger, label 0
center_word originated, target sch, label 0
center_word originated, target merezhkovsky, label 0
center_word originated, target term, label 1
center_word originated, target wada, label 0
center_word originated, target atresia, label 0
center_word originated, target alportian, label 0
center_word originated, target superordinate, label 0
center_word originated, target abuse, label 1
center_word originated, target druon, label 0
center_word originated, target conservacion, label 0
center_word originated, target sialkot, label 0
center_word originated, target prophase, label 0
center_word originated, target used, label 1
center_word originated, target etching, label 0
center_word originated, target quoting, label 0
center_word originated, target paludan, label 0
center_word originated, target entanti, label 0
训练数据准备好后,把训练数据都组装成mini-batch,并准备输入到网络中进行训练,代码如下:
# 构造mini-batch,准备对模型进行训练
# 我们将不同类型的数据放到不同的tensor里,便于神经网络进行处理
# 并通过numpy的array函数,构造出不同的tensor来,并把这些tensor送入神经网络中进行训练
def build_batch(dataset, batch_size, epoch_num):# center_word_batch缓存batch_size个中心词center_word_batch = []# target_word_batch缓存batch_size个目标词(可以是正样本或者负样本)target_word_batch = []# label_batch缓存了batch_size个0或1的标签,用于模型训练label_batch = []for epoch in range(epoch_num):# 每次开启一个新epoch之前,都对数据进行一次随机打乱,提高训练效果random.shuffle(dataset)for center_word, target_word, label in dataset:# 遍历dataset中的每个样本,并将这些数据送到不同的tensor里center_word_batch.append([center_word])target_word_batch.append([target_word])label_batch.append(label)# 当样本积攒到一个batch_size后,我们把数据都返回回来# 在这里我们使用numpy的array函数把list封装成tensor# 并使用python的迭代器机制,将数据yield出来# 使用迭代器的好处是可以节省内存if len(center_word_batch) == batch_size:yield np.array(center_word_batch).astype("int64"), \np.array(target_word_batch).astype("int64"), \np.array(label_batch).astype("float32")center_word_batch = []target_word_batch = []label_batch = []if len(center_word_batch) > 0:yield np.array(center_word_batch).astype("int64"), \np.array(target_word_batch).astype("int64"), \np.array(label_batch).astype("float32")
for _, batch in zip(range(10), build_batch(dataset, 128, 3)):print(batch)
2.2 定义skip-gram网络
定义skip-gram的网络结构,用于模型训练。在飞桨动态图中,对于任意网络,都需要定义一个继承自paddle.nn.layer的类来搭建网络结构、参数等数据的声明。同时需要在forward函数中定义网络的计算逻辑。值得注意的是,我们仅需要定义网络的前向计算逻辑,飞桨会自动完成神经网络的后向计算。
在skip-gram的网络结构中,使用的最关键的APi是paddle.nn.Embedding函数,可以用其实现Embedding的网络层。通过查询飞桨的API文档,可以得到如下更详细的说明:
paddle.nn.Embedding(numembeddings, embeddingdim, paddingidx=None, sparse=False, weightattr=None, name=None)
该接口用于构建 Embedding 的一个可调用对象,其根据input中的id信息从embedding矩阵中查询对应embedding信息,并会根据输入的size (numembeddings, embeddingdim)自动构造一个二维embedding矩阵。 输出Tensor的shape是在输入Tensor shape的最后一维后面添加了emb_size的维度。注:input中的id必须满足 0 =< id < size[0],否则程序会抛异常退出。
#定义skip-gram训练网络结构
#使用paddlepaddle的2.0.0版本
#一般来说,在使用paddle训练的时候,我们需要通过一个类来定义网络结构,这个类继承了paddle.nn.layer
class SkipGram(paddle.nn.Layer):def __init__(self, vocab_size, embedding_size, init_scale=0.1):# vocab_size定义了这个skipgram这个模型的词表大小# embedding_size定义了词向量的维度是多少# init_scale定义了词向量初始化的范围,一般来说,比较小的初始化范围有助于模型训练super(SkipGram, self).__init__()self.vocab_size = vocab_sizeself.embedding_size = embedding_size# 使用Embedding函数构造一个词向量参数# 这个参数的大小为:[self.vocab_size, self.embedding_size]# 数据类型为:float32# 这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样self.embedding = Embedding( num_embeddings = self.vocab_size,embedding_dim = self.embedding_size,weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Uniform( low=-init_scale, high=init_scale)))# 使用Embedding函数构造另外一个词向量参数# 这个参数的大小为:[self.vocab_size, self.embedding_size]# 这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样self.embedding_out = Embedding(num_embeddings = self.vocab_size,embedding_dim = self.embedding_size,weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Uniform(low=-init_scale, high=init_scale)))# 定义网络的前向计算逻辑# center_words是一个tensor(mini-batch),表示中心词# target_words是一个tensor(mini-batch),表示目标词# label是一个tensor(mini-batch),表示这个词是正样本还是负样本(用0或1表示)# 用于在训练中计算这个tensor中对应词的同义词,用于观察模型的训练效果def forward(self, center_words, target_words, label):# 首先,通过self.embedding参数,将mini-batch中的词转换为词向量# 这里center_words和eval_words_emb查询的是一个相同的参数# 而target_words_emb查询的是另一个参数center_words_emb = self.embedding(center_words)target_words_emb = self.embedding_out(target_words)# 我们通过点乘的方式计算中心词到目标词的输出概率,并通过sigmoid函数估计这个词是正样本还是负样本的概率。word_sim = paddle.multiply(center_words_emb, target_words_emb)word_sim = paddle.sum(word_sim, axis=-1)word_sim = paddle.reshape(word_sim, shape=[-1])pred = F.sigmoid(word_sim)# 通过估计的输出概率定义损失函数,注意我们使用的是binary_cross_entropy_with_logits函数# 将sigmoid计算和cross entropy合并成一步计算可以更好的优化,所以输入的是word_sim,而不是predloss = F.binary_cross_entropy_with_logits(word_sim, label)loss = paddle.mean(loss)# 返回前向计算的结果,飞桨会通过backward函数自动计算出反向结果。return pred, loss
2.3 网络训练
完成网络定义后,就可以启动模型训练。我们定义每隔100步打印一次Loss,以确保当前的网络是正常收敛的。
同时,我们每隔10000步观察一下skip-gram计算出来的同义词(使用 embedding的乘积),可视化网络训练效果,代码如下:
运行时长: 4小时15分钟8秒301毫秒
# 开始训练,定义一些训练过程中需要使用的超参数
batch_size = 512
epoch_num = 10
embedding_size = 200
step = 0
learning_rate = 2e-4#定义一个使用word-embedding查询同义词的函数
#这个函数query_token是要查询的词,k表示要返回多少个最相似的词,embed是我们学习到的word-embedding参数
#我们通过计算不同词之间的cosine距离,来衡量词和词的相似度
#具体实现如下,x代表要查询词的Embedding,Embedding参数矩阵W代表所有词的Embedding
#两者计算Cos得出所有词对查询词的相似度得分向量,排序取top_k放入indices列表
def get_similar_tokens(query_token, k, embed):W = embed.numpy()x = W[word2id_dict[query_token]]cos = np.dot(W, x) / np.sqrt(np.sum(W * W, axis=1) * np.sum(x * x) + 1e-9)flat = cos.flatten()indices = np.argpartition(flat, -k)[-k:]indices = indices[np.argsort(-flat[indices])]for i in indices:print('for word %s, the similar word is %s' % (query_token, str(id2word_dict[i])))# 将模型放到GPU上训练
paddle.set_device('gpu:0')# 通过我们定义的SkipGram类,来构造一个Skip-gram模型网络
skip_gram_model = SkipGram(vocab_size, embedding_size)# 构造训练这个网络的优化器
adam = paddle.optimizer.Adam(learning_rate=learning_rate, parameters = skip_gram_model.parameters())# 使用build_batch函数,以mini-batch为单位,遍历训练数据,并训练网络
for center_words, target_words, label in build_batch(dataset, batch_size, epoch_num):# 使用paddle.to_tensor,将一个numpy的tensor,转换为飞桨可计算的tensorcenter_words_var = paddle.to_tensor(center_words)target_words_var = paddle.to_tensor(target_words)label_var = paddle.to_tensor(label)# 将转换后的tensor送入飞桨中,进行一次前向计算,并得到计算结果pred, loss = skip_gram_model(center_words_var, target_words_var, label_var)# 程序自动完成反向计算loss.backward()# 程序根据loss,完成一步对参数的优化更新adam.step()# 清空模型中的梯度,以便于下一个mini-batch进行更新adam.clear_grad()# 每经过1000个mini-batch,打印一次当前的loss,看看loss是否在稳定下降step += 1if step % 1000 == 0:print("step %d, loss %.3f" % (step, loss.numpy()[0]))# 每隔10000步,打印一次模型对以下查询词的相似词,这里我们使用词和词之间的向量点积作为衡量相似度的方法,只打印了5个最相似的词if step % 10000 ==0:get_similar_tokens('movie', 5, skip_gram_model.embedding.weight)get_similar_tokens('one', 5, skip_gram_model.embedding.weight)get_similar_tokens('chip', 5, skip_gram_model.embedding.weight)
step 674000, loss 0.121
step 675000, loss 0.102
step 676000, loss 0.119
step 677000, loss 0.054
step 678000, loss 0.037
step 679000, loss 0.077
step 680000, loss 0.071
for word movie, the similar word is movie
for word movie, the similar word is animated
for word movie, the similar word is mask
for word movie, the similar word is beavis
for word movie, the similar word is parody
for word one, the similar word is one
for word one, the similar word is mortcha
for word one, the similar word is sanshiro
for word one, the similar word is evaluand
for word one, the similar word is rao
for word chip, the similar word is chip
for word chip, the similar word is graphics
for word chip, the similar word is api
for word chip, the similar word is blowfish
for word chip, the similar word is usb
从打印结果可以看到,经过一定步骤的训练,Loss逐渐下降并趋于稳定。
同时也可以发现skip-gram模型可以学习到一些有趣的语言现象。
总结
skip-gram提供了一种根据中心词推理上下文的思路。
比如在多数情况下,“香蕉”和“橘子”更加相似,而“香蕉”和“句子”就没有那么相似;同时,“香蕉”和“食物”、“水果”的相似程度可能介于“橘子”和“句子”之间。那么如何让存储的词向量具备这样的语义信息呢?
我们先学习自然语言处理领域的一个小技巧。在自然语言处理研究中,科研人员通常有一个共识:使用一个单词的上下文来了解这个单词的语义,比如:
“苹果手机质量不错,就是价格有点贵。”
“这个苹果很好吃,非常脆。”
“菠萝质量也还行,但是不如苹果支持的APP多。”
在上面的句子中,我们通过上下文可以推断出第一个“苹果”指的是苹果手机,第二个“苹果”指的是水果苹果,而第三个“菠萝”指的应该也是一个手机。事实上,在自然语言处理领域,使用上下文描述一个词语或者元素的语义是一个常见且有效的做法。我们可以使用同样的方式训练词向量,让这些词向量具备表示语义信息的能力。
全网同名: iterhui
我在AI Studio上获得钻石等级,点亮9个徽章,来互关呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/643467
这篇关于[Paddle2.0学习之第四步](上)词向量之skip-gram的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








