本文主要是介绍DSP_TMS320F28377D_算法加速方法3_使用TMU库加速,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
继上两篇方法
DSP_TMS320F28377D_算法加速方法1_拷贝程序到RAM运行_江湖上都叫我秋博的博客-CSDN博客
DSP_TMS320F28377D_算法加速方法2_添加浮点运算快速补充库rts2800_fpu32_fast_supplement.lib_江湖上都叫我秋博的博客-CSDN博客
之后,本文继续讨论第三种DSP算法加速的方法——TMU库。
TMU库在28377D的项目中,一般是自动配置上的,用户是无需任何操作的。
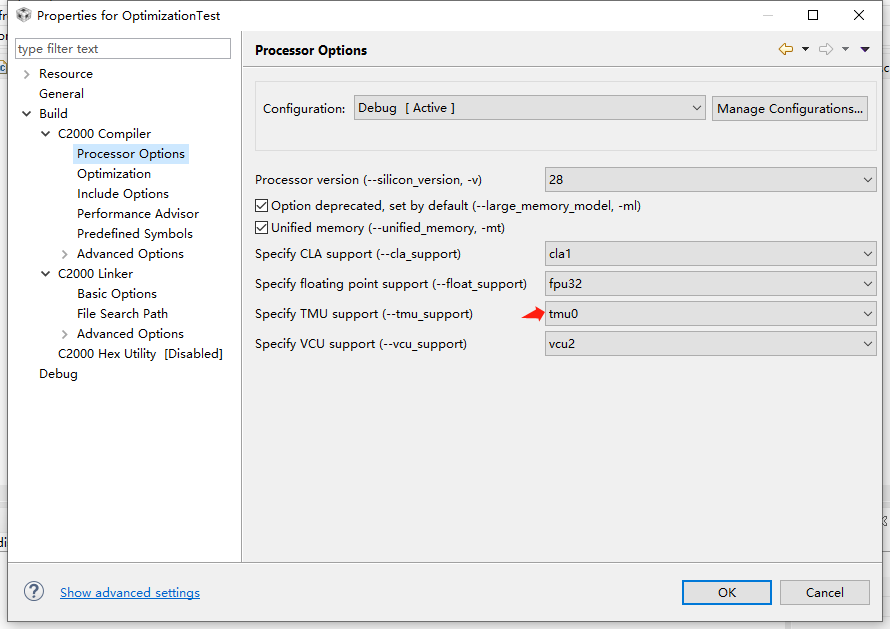
另外,本人实测,在28335项目中,TMU库是无效的,我怀疑28335就不支持TMU加速。如果有知道怎么操作的朋友,可评论区、私信告知。
该方法的加速能力比方法2还强。不过同样也有一个范围的:
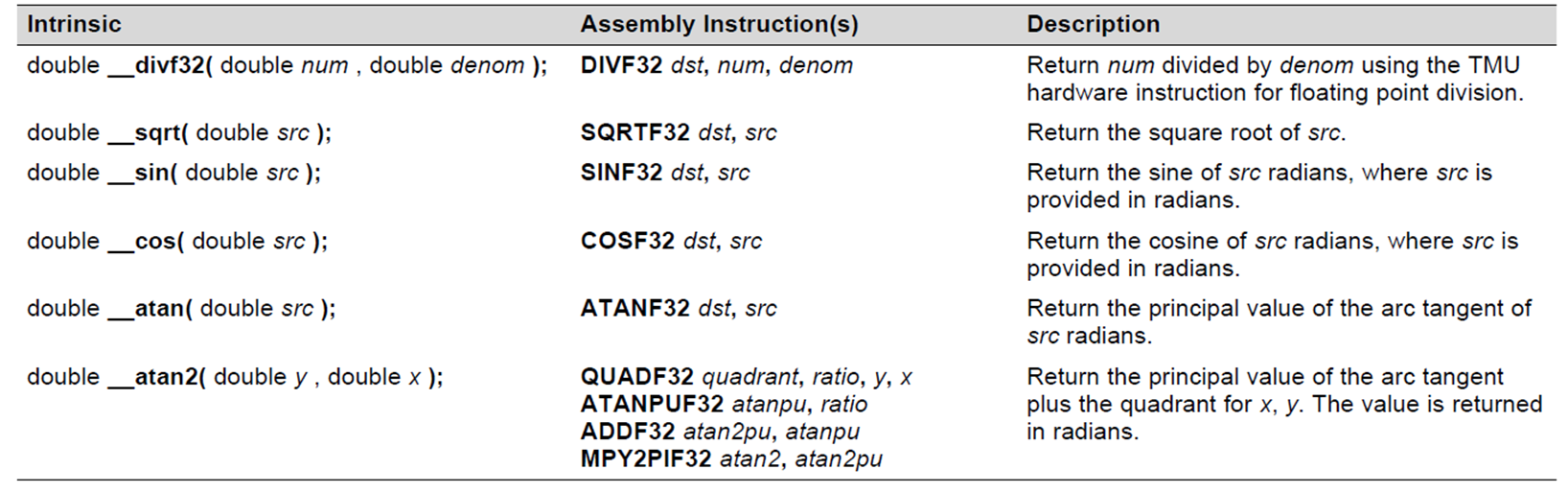

方法2我们简称为FPU加速,本文的方法(方法3)我们简称为TMU加速。 FPU加速和TMU加速是两种互斥的方法,就是你用了某一种,就不能用另一种了。 所以你必须有所取舍。
1 速度对比
下面我们从速度和精度两方面做一个对比,首先来看速度。(代码贴到最后吧)
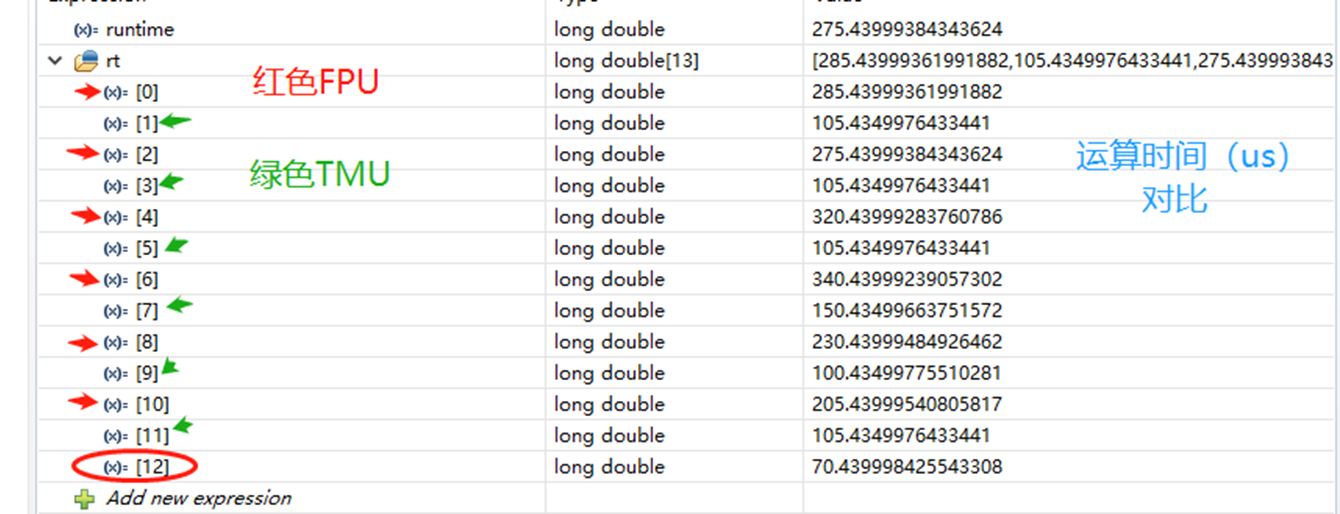
TMU相比于FPU在速度上有非常明显的优势,TMU相比于FPU能够加速两倍以上。 (最后10 11 12,都是测试的小数的除法,12的结果是我直接用常数运算,而没有用变量的方式)。
2 精度对比
精度方面,我用sin(1.9)来做一个对比测试吧。
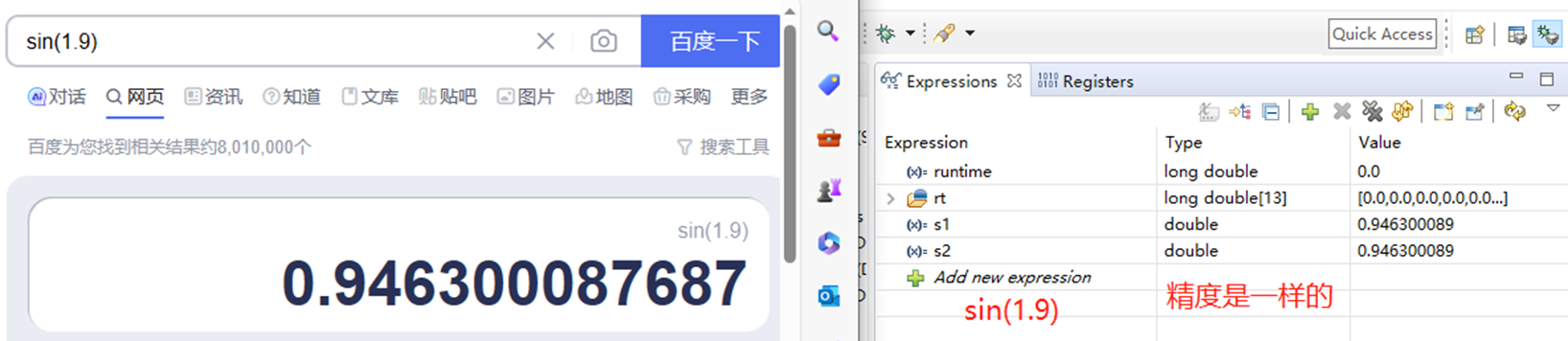
可以看到精度都要损失,但是FPU和TMU两种方法的精度是一样的。
结论:对于相同的函数,最优的选择就是TMU。
3 代码
代码的整体框架本文不赘述,看:DSP_基于TMS320F28377D双核芯片和CCS7.40的编程入门_ccs双核芯片下载_江湖上都叫我秋博的博客-CSDN博客
如何获取代码块的运行时间,本文也不赘述,看: DSP_TMS320F28377D_使用定时器实现<获取代码块运算时间>的功能_江湖上都叫我秋博的博客-CSDN博客
代码我就只贴一下main.c 和 main.h
// main.c
#include <main.h>float64 rt[13];
double s1;
double s2;
void main(void)
{int i;InitSysCtrl();DINT;InitPieCtrl();InitGpio();IER = 0x0000;IFR = 0x0000;InitPieVectTable();InitCpuTimers();s1 = sin(1.9);s2 = __sin(1.9);asm (" ESTOP0");runtime_init();while(1){for(i = 0; i < 13; i++){runtime_start();testfunction(i+1);runtime_stop();rt[i] = runtime;}}}void testfunction(int sel){int i = 0;double s,a,b;a = 1.023;b = 2.312;switch(sel){case 1:for(i = 0; i < 1000; i++){s = sin(a);}break;case 2:for(i = 0; i < 1000; i++){s = __sin(a);}break;case 3:for(i = 0; i < 1000; i++){s = cos(a);}break;case 4:for(i = 0; i < 1000; i++){s = __cos(a);}break;case 5:for(i = 0; i < 1000; i++){s = atan(a);}break;case 6:for(i = 0; i < 1000; i++){s = __atan(a);}break;case 7:for(i = 0; i < 1000; i++){s = atan2(a,b);}break;case 8:for(i = 0; i < 1000; i++){s = __atan2(a,b);}break;case 9:for(i = 0; i < 1000; i++){s = sqrt(a);}break;case 10:for(i = 0; i < 1000; i++){s = __sqrt(a);}break;case 11:for(i = 0; i < 1000; i++){s = a/b;}break;case 12:for(i = 0; i < 1000; i++){s = __divf32(a,b);}break;case 13:for(i = 0; i < 1000; i++){s = 1.023 / 2.312;}break;default :break;}}// main.h
#include <F28x_Project.h>
#include <runtime.h>
#include <math.h>interrupt void CpuTimer0ISR(void);
#pragma CODE_SECTION(testfunction,".TI.ramfunc");void testfunction(int sel);算了,还是runtime的也贴上吧
// runtime.c#include <runtime.h>float64 runtime = 0; // 单位usvoid runtime_init(void){ConfigCpuTimer(&CpuTimer1, 200, 10000000); // 支持代码块最长运行时常10s
}void runtime_start(void){CpuTimer1Regs.TCR.bit.TRB = 1; // 周期计时器重装载CpuTimer1Regs.TCR.bit.TSS = 0; // 开始计数
}void runtime_stop(void){runtime = (float64)(CpuTimer1Regs.PRD.all - CpuTimer1Regs.TIM.all) * 0.005; // 等价于 / 200, 单位usCpuTimer1Regs.TCR.bit.TSS = 1; // 停止计数
}// runtime.h
#ifndef PROGRAM_RUNTIME_RUNTIME_H_
#define PROGRAM_RUNTIME_RUNTIME_H_#include <main.h>extern float64 runtime;
void runtime_init(void);
void runtime_start(void);
void runtime_stop(void);#endif /* PROGRAM_RUNTIME_RUNTIME_H_ */
4 关于是否与方法1叠加加速
答:可以! 亲测可叠加!
5 中断中是否可用
答:肯定可以!我猜的,我没测😄。
后续会再推出DSP算法加速的方法与大家探讨。感谢您的阅读,如果您有什么优化方法,欢迎留言分享、收藏、点赞。
这篇关于DSP_TMS320F28377D_算法加速方法3_使用TMU库加速的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



