本文主要是介绍【大数据开发】FineReport报表基础入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
博主:👍不许代码码上红
欢迎:🐋点赞、收藏、关注、评论。
格言: 大鹏一日同风起,扶摇直上九万里。文章目录
- 一 登录账号
- 二 创建一个新的表格
- 三 单元格扩展
- 3.1 无扩展
- 3.2 纵向扩展
- 3.3 横向扩展
- 四 父子格设置
- 4.1 上父格
- 4.2 左父格
- 五 创建一张普通报表
- 5.1 报表设计流程
- 5.2 新建数据库连接
- 5.3 选择数据集
- 5.4 报表设计
- 5.4.1 标题设计
- 5.4.2 表格数据设计
- 5.4.3 设计父子格关系以及主题
- 六 参数查询
- 6.1 模板设计
- 6.2 控件设置
- 6.3 添加过滤条件
- 6.4 效果预览
- 七 图表设计
- 八 填报功能
- 1 数据准备
- 2 报表设计
- 3 添加填报控件
- 4 设置填报属性
- 5 设置模板Web属性
- 6 效果预览
- 九 决策系统挂载报表
- 9.1 步骤
- 十 移动端预览
目录
一 登录账号
第一次打开预览效果页面,会提示登录账号。首先创建一个随意地账号与密码用于登录即可。如图1-1。
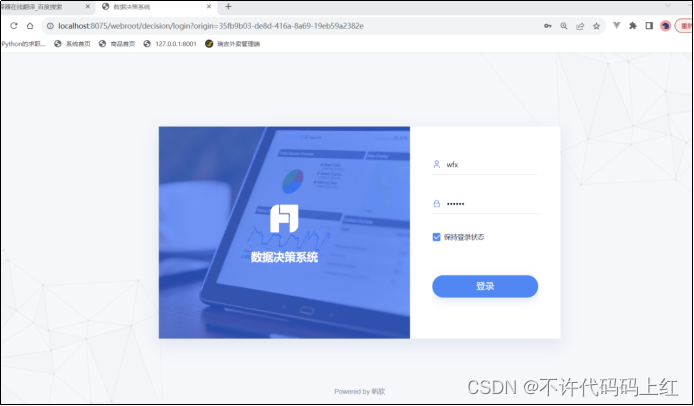
图1-1
二 创建一个新的表格
存放路径默认即可。如图2-1。
图2-1
三 单元格扩展
单元格只有2个方向,横向和纵向,而FineReport恰恰是一款类Excel的报表工具,其单元格也一样,因此,FineReport报表中单元格的扩展是有方向的,可纵向扩展,也可横向扩展,当然也可以不扩展。
3.1 无扩展
在单元格中放入数据后,选择无扩展然后进行预览。如图3-1
图3-1
预览效果。如图3-2。
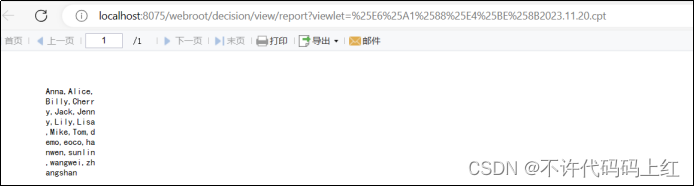
图3-2
3.2 纵向扩展
单元格中的数据依次从上至下的显示,即纵向扩展(行方向的扩展,一行变多行),如下图,在单元格中输入公式 =range(1,5),在右侧的单元格属性表-扩展属性中选择扩展方向为纵向。如图3-3。
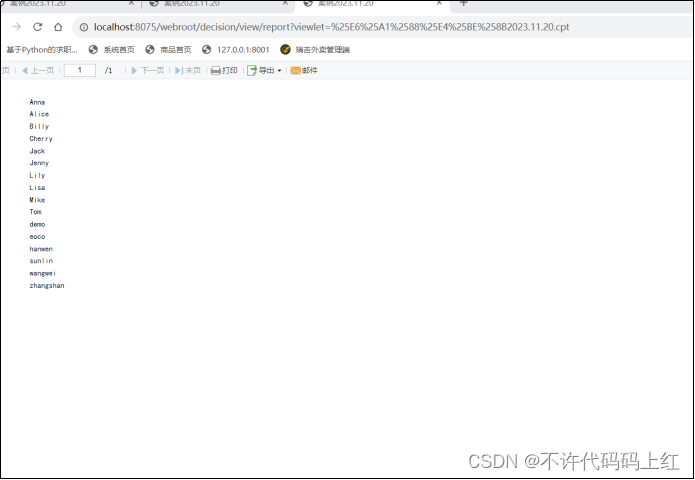
图3-3
3.3 横向扩展
单元格中的数据依次从左至右的显示,即横向扩展(列方向的扩展,一列变多列),如下图,在单元格中输入公式 =range(1,5),在右侧的单元格属性表-扩展属性中选择扩展方向为横向。如图3-4。

图3-4
四 父子格设置
父子格从字面上讲,就是父格汇总,子格详细,我们可以近似的理解成两个单元格之间的一种group展示效果。有两种情况,一种叫左父格,一种叫上父格。
4.1 上父格
上边的单元格做一个分组的组名,下边的单元格是组内的详细数据(上边的单元格必须是横向扩展)。如图4-1(未设置上父格)和图4-2(设置了上父格)。
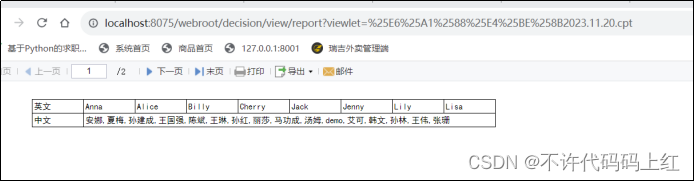
图4-1
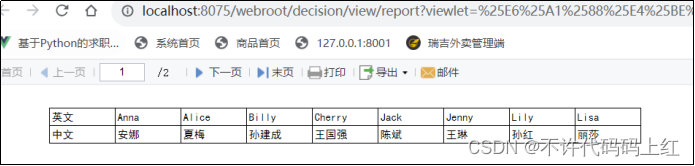
图4-2
4.2 左父格
左边的单元格做一个分组的组名,右边的单元格是组内的详细数据。如图4-3(未设置)和图4-4(设置左父格)。
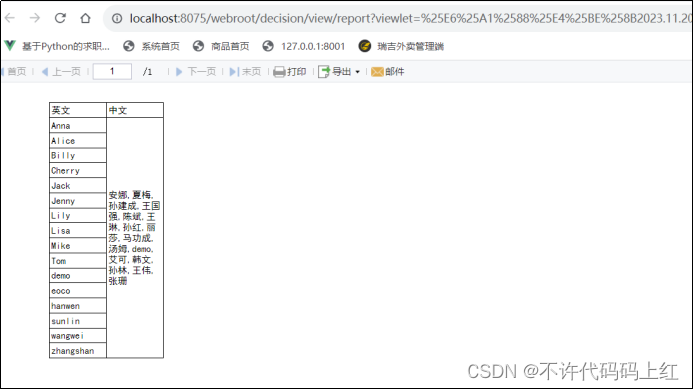
图4-3
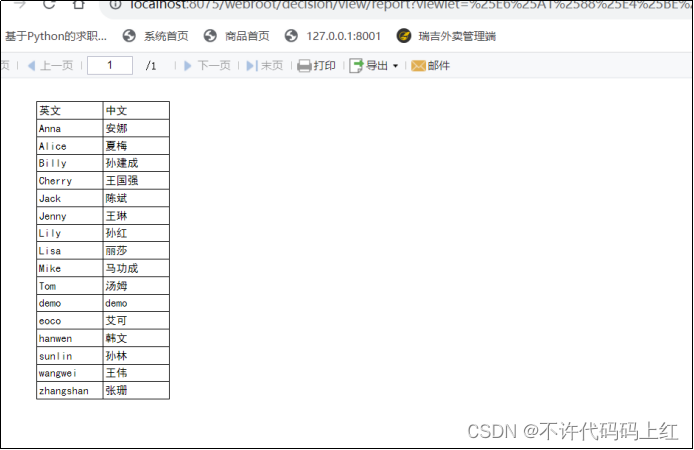
图4-4
五 创建一张普通报表
5.1 报表设计流程
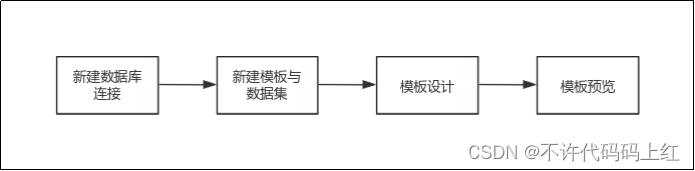
1 新建数据库连接:在设计器中建立一个新的数据库连接,建立设计器与数据库的关联桥梁。
2 新建模板与数据集:数据库连接好以后并没有具体数据集。选择模板之后,再从数据库中取出相对应的数据集。
3 模板设计:数据准备好以后,进行模板设计。模板设计主要分为四大类:报表设计、参数设计、图表设计、填报设计。
4 模板预览:模板设计完成后,保存在工程目录下。可以在Web端进行预览。预览包括:分页预览、填报预览、数据分析预览、移动端预览、决策报表预览。
5.2 新建数据库连接
使用设计器内置的数据库。如图5-1。
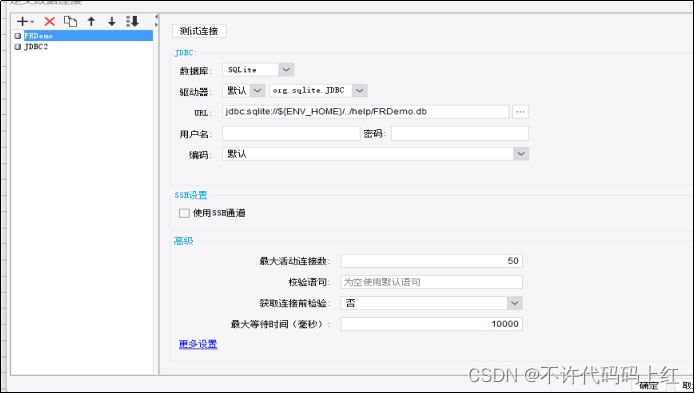
图5-1
5.3 选择数据集
首先选择设计器左下方的模板数据集,点击+号。选择销量这张表。
SQL语句:
select * from 销量
如图5-2所示。
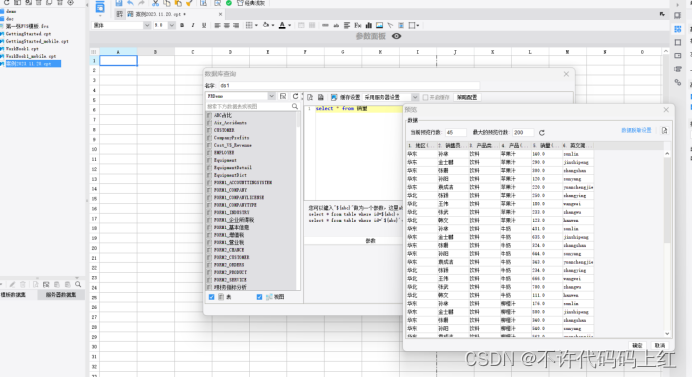
图5-2
5.4 报表设计
5.4.1 标题设计
如图5-3所示。
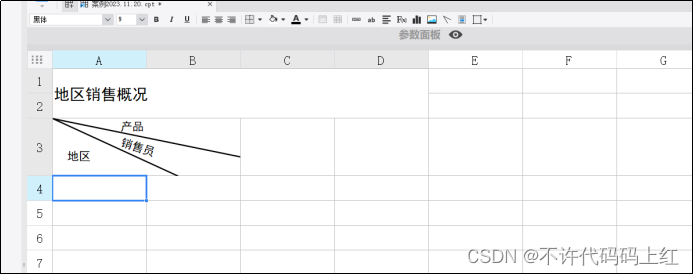
图5-3
5.4.2 表格数据设计
如图5-4所示。
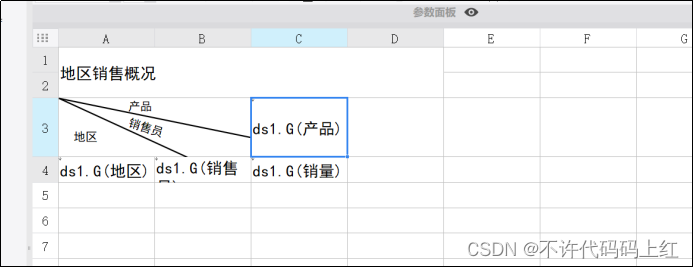
图5-4
提示,这里用到一个求和函数SUM。如图5-5。
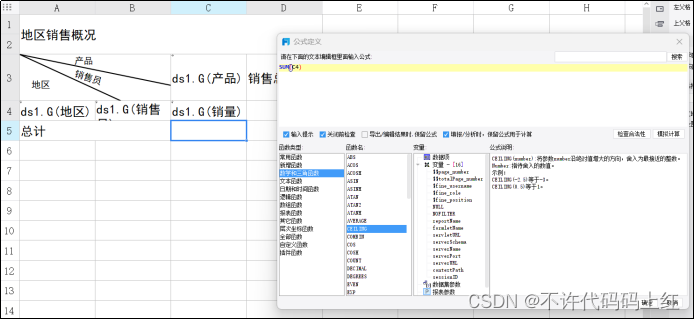
图5-5
也可是直接数据公式,与Excel操作基本上一样。设计完成后的表格如图5-6所示。
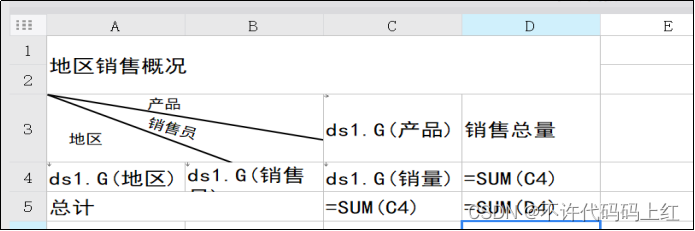
图5-6
5.4.3 设计父子格关系以及主题
将图5-6的D4单元格的左父单元格设置为B4;
设置主题风格,如图5-7所示。
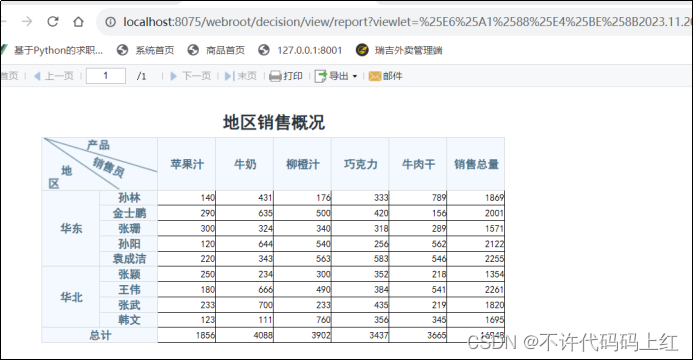
图5-7
六 参数查询
6.1 模板设计
添加模板参数,如图6-1。
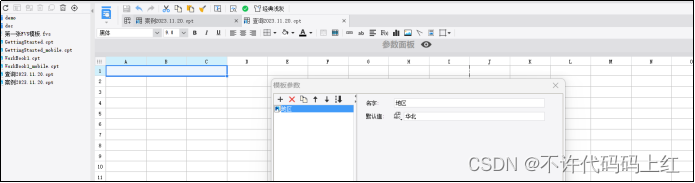
图6-1
6.2 控件设置
主要设置查询的范围和控件的样式。如图6-2。
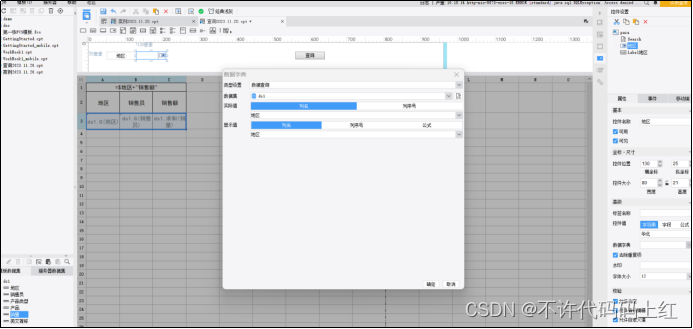
图6-2
6.3 添加过滤条件
如图6-3所示。
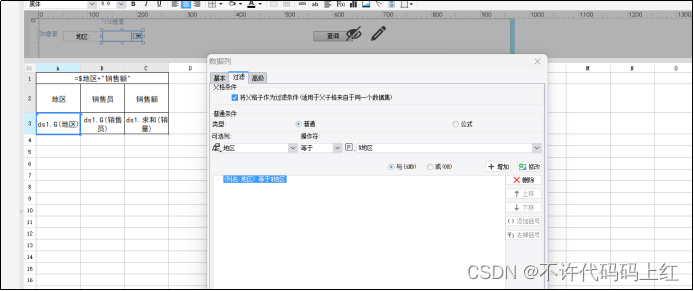
图6-3
6.4 效果预览
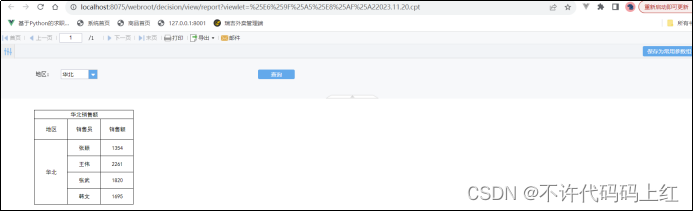
图6-4
七 图表设计
设计一张柱状图。如图7-1。
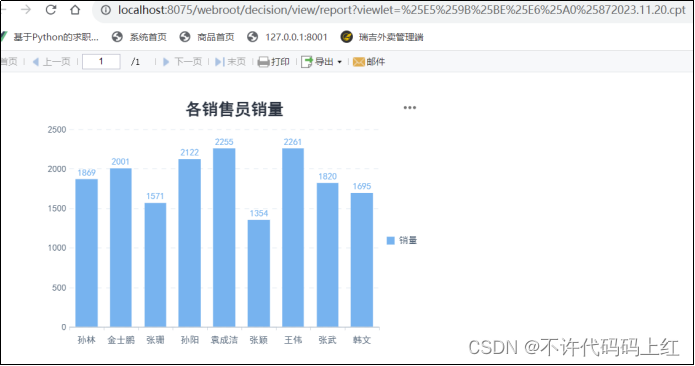
图7-1
八 填报功能
1 数据准备
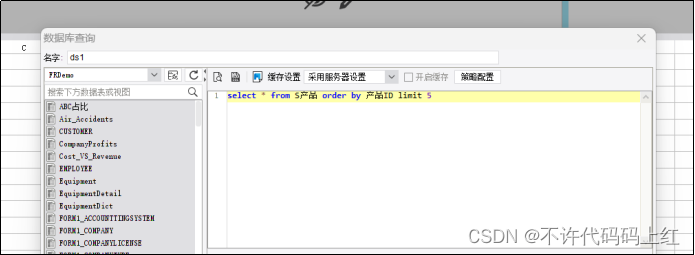
图8-1
2 报表设计

图8-2
3 添加填报控件
将A2-I2设置为文本控件。如图8-3。

图8-3
4 设置填报属性
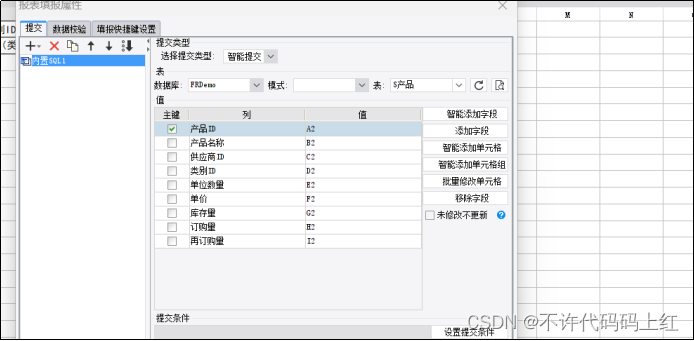
图8-4
5 设置模板Web属性
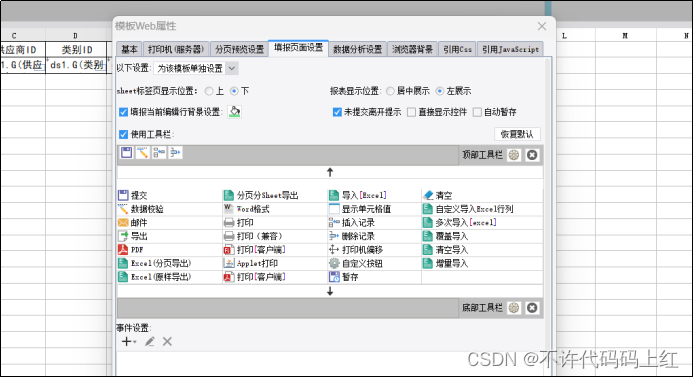
图8-5
6 效果预览
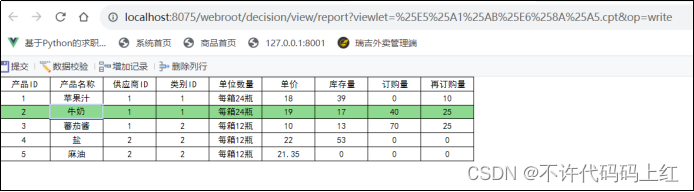
图8-6
九 决策系统挂载报表
9.1 步骤
1 完成决策系统初始化配置
2 模板上传系统,并使用管理员账户登录系统
3 将制作好的报表挂载到系统目录下
4 管理用户信息 5 给用户授权
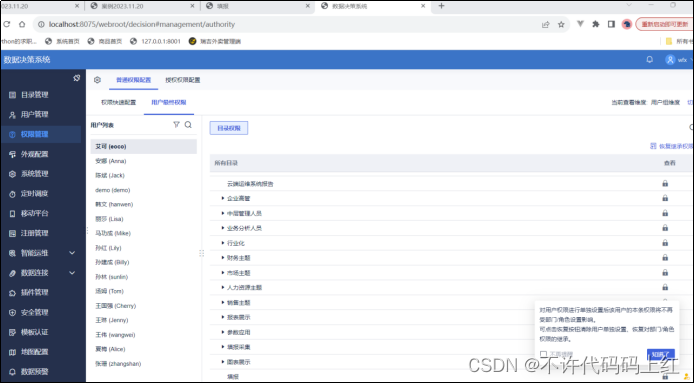
图9-1
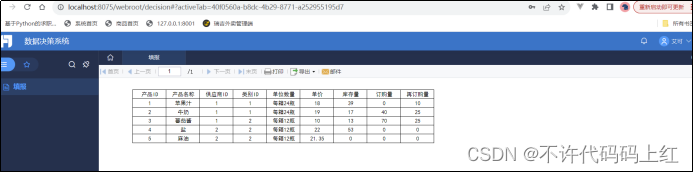
图9-2
十 移动端预览
条件:将pc端与移动端处于同一个网络环境中
图10-1
移动端。如图10-2。
图10-2
这篇关于【大数据开发】FineReport报表基础入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








