本文主要是介绍去噪论文阅读——[CVPR2022]Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
知乎同名账号同步发布
今天看一篇自监督图像去噪论文:
题目:Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots
paper:https://arxiv.org/abs/2203.06967
code:https://github.com/demonsjin/Blind2Unblind
目录
- 前置知识
- 创新点
- 模型架构
- inference阶段
- 实验
前置知识
需要了解Noise2Void,如果不了解,可以看我写的笔记。
看完之后,我们知道,对于Noise2void(N2V)来说,给定一张noisy image y,先将它上面的一些点mask掉,然后输入给神经网络,神经网络输出的target为y本身,这样网络就能够学到去噪的方法。
上面的这种方法被称为blindspots schemes,因为它mask掉了input的一些pixels,使得网络看不见这些pixel。
Blind2Unblind文中提到了“relief from identity mapping”,其指出含有盲点的方法,能够避免恒等映射。所谓恒等映射,指的就是如果在blindspots schemes中,不去mask掉input中的一些pixels,而是将完整的y输入给神经网络,并且神经网络的target是输出y本身,那么网络就会学到恒等映射,而不是学到去噪的方法。
但另一方面,作者也提出,blindspots schemes也有缺点,那就是会导致information loss,因为网络看不到被mask掉的这些点的信息。
创新点
作者指出,N2V这一类的方法,由于盲点的存在,能够避免网络学习恒等映射,同时根据数学分析和实验证明,网络能够学到去噪。
所以作者准备使用blindspots schemes,但是作者同时也不想承受information loss,所以在架构设计的时候,他使用了raw noisy image y,也就是不进行mask操作的、原始的noisy image。这样,就能够利用到所有input像素点的信息,理论上讲避免了information loss。
模型架构
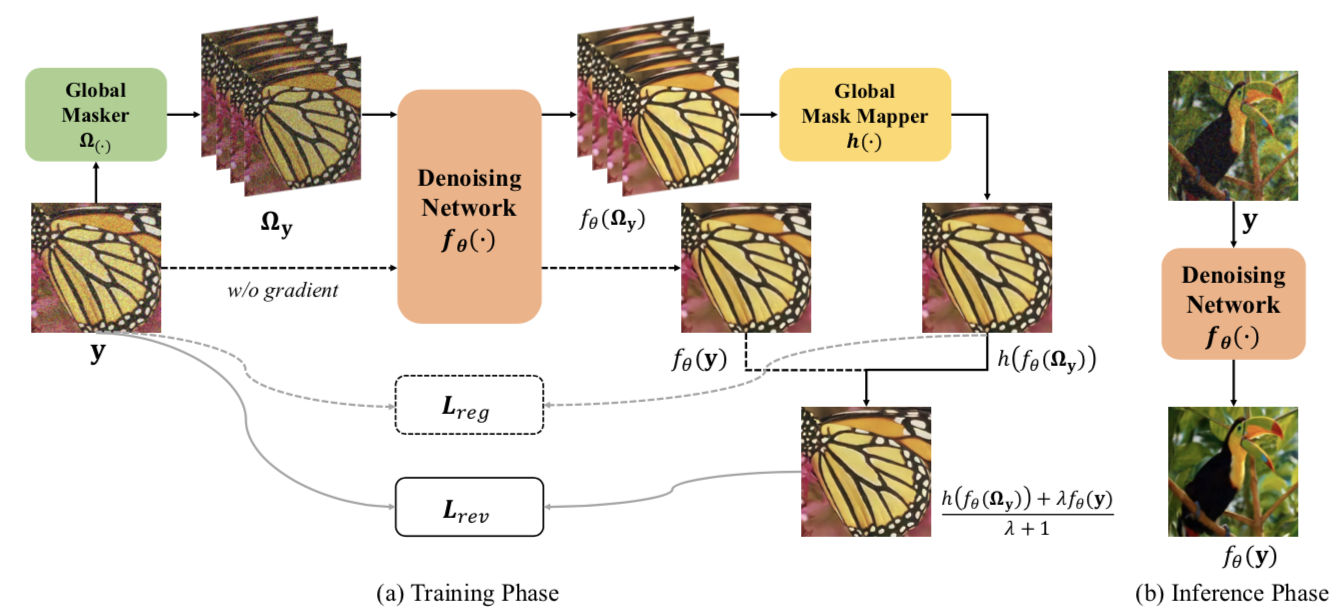
一张noisy image y通过一个global masker Ω操作,变成四张含有盲点的图片,这四张图片分别通过去噪网络f,获得四张去噪结果,然后通过global mask mapper h的操作,获得一张去噪结果 h ( f θ ( Ω y ) ) h(f_θ(Ω_y)) h(fθ(Ωy))。另一方面,完整的noisy image y也要通过去噪神经网络f,获得另一个去噪结果 f θ ( y ) f_θ(y) fθ(y)。为了简便起见,前者我称其为“含有盲点的去噪结果”,后者我称其为“不含盲点的去噪结果”。两者进行一个加权平均,获得的结果和y做loss,即 L r e v L_{rev} Lrev,rev的意思是re-visible,也就是本来是一个blindspots的方案,现在因为引入了raw noisy image y,它变得不再那么blind了,不再需要承受information loss了。 L r e g L_{reg} Lreg是正则化项,意义自明。
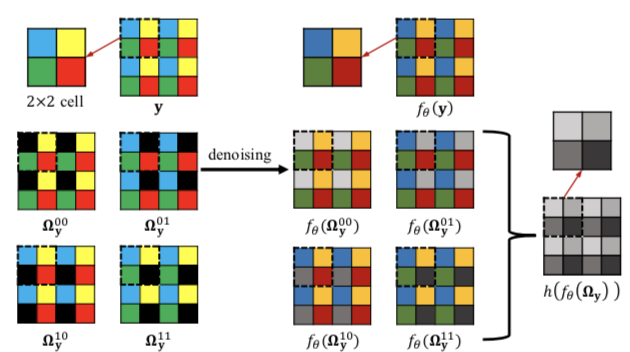
架构图中的Ω和h操作也非常简单。作者用4×4的图片进行举例说明,先将图片分成若干2×2的cell,分别同时对每个cell的左上角、右上角、左下角、右下角进行mask操作,获得四张含有盲点的图片,输入去噪网络,得到四张去噪结果。四张去噪结果中的灰色代表和去噪前盲点所在位置对应的pixel,h要做的事情就是将所有灰色的pixel,相对位置不发生变化,提取出来组成一张图片,也就是最右边的灰色图片,它就是所有盲点对应的去噪结果。上图中有半部分的最上面,对应的就是完整的y得到的去噪结果(不含盲点)。两个去噪结果要一同使用来训练。
inference阶段

注意一下上图就行了,意思就是说不含盲点的去噪结果,从经验上来讲要拥有更好的效果,所以inference阶段只使用它。
实验
做了合成图像去噪、真实图像去噪,部分情况下指标不是最高,节选部分显著的实验结果如下:

这是SIDD上的结果,可以看出确实比N2V要好,但是和NBR2NBR无明显差异。
这篇关于去噪论文阅读——[CVPR2022]Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)