本文主要是介绍“新KG”视点 | 知识图谱与大语言模型协同模式探究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OpenKG

大模型专辑
导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织新KG视点系列文章——“大模型专辑”,不定期邀请业内专家对知识图谱与大模型的融合之道展开深入探讨。本期特别邀请到天津大学王鑫教授、同济大学王昊奋研究员和天津大学陈子睿博士共同分享“知识图谱与大语言模型协同模式探究”,本文发表于CCF计算机学会通讯2023年第11期。
分享嘉宾 | 王鑫(天津大学)、陈子睿(天津大学)、王昊奋(同济大学)
笔记整理 | 邓鸿杰(OpenKG)
内容审定 | 陈华钧

摘要:本文探讨了知识图谱与大语言模型的协同模式。首先介绍了背景与现状,然后分别探讨了知识图谱增强的大语言模型、大语言模型增强的知识图谱以及知识图谱与大语言模型交互融合,并给出交互融合的具体案例。最后探讨了知识图谱与大语言模型协同模型的未来发展方向。
01
背景与现状
随着ChatGPT为代表的大语言模型(Large Language Model, LLM)兴起,及其对知识图谱(Knowledge Graph, KG)技术影响的深入探讨[1],LLM和KG的关系及其相互作用已成为人工智能领域的一个研究热点问题。LLM正在人工智能的多个领域产生深刻影响,可以认为是“联结主义”的最新进展;而KG代表人工智能知识工程领域的前沿发展,是“符号主义”的集大成者。一方面,LLM涵盖范围广泛,能够适应不同的语境及上下文,生成更加自然贴切的语言,可用于文本摘要、问答系统、机器翻译等多种不同的自然语言处理任务,但LLM为参数化隐式知识,会存在事实编造、缺乏可解释性等问题;另一方面,KG是结构化显式知识,天然就具有可解释性,领域特定的知识质量高,但其构建开销大,往往不够完备,且缺乏自然语言处理能力。LLM与KG协同工作可以克服各自缺陷、发挥互补优势,共同提升自然语言处理能力,扩大应用范围。KG可以提供额外的、结构化的、高质量的知识,提高模型泛化能力,其结构化知识可以帮助人们理解模型输出;LLM可以自动从文本数据中提取知识,从而降低KG的构建和维护成本。
目前,KG和LLM的协同仍处于起步阶段,其协同设计模式存在很多待解决的问题,有必要对这些问题进行梳理总结,以便研究人员和开发人员更好地理解这一领域的现状和发展趋势,共同讨论KG与LLM相结合的潜力与未来。
02
知识图谱增强的大语言模型(KG4LLM)
LLM能从大规模语料库中学习知识,并在诸如实体识别,关系抽取等多种自然语言处理任务中取得最先进的性能。然而,LLM在生成文本时可能产生看似合理而实际错误的内容,被称为“幻觉问题”;其次,尽管LLM可以从大规模语料库中学习大量知识,但这些知识基于统计模式,不是真正的实际知识,可能导致在处理特定领域问题时缺乏深刻理解和准确知识;最后,LLM生成的结果通常缺乏可解释性,用户很难理解模型如何得出特定结论或生成特定文本,结果缺乏可解释性限制了模型在关键任务中的可用性。
为解决这些问题,鉴于KG以明确且结构化的方式存储大量知识,可用于提升LLM的性能,如图1所示,研究人员提出将KG整合到LLM中,以增强LLM的性能表现。
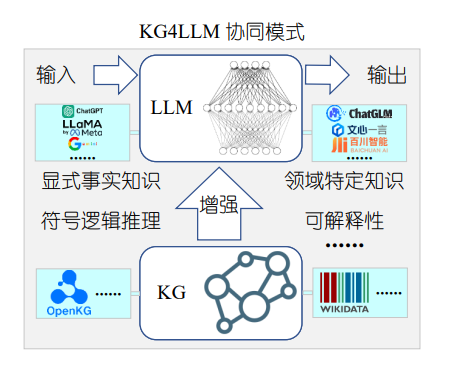
图1 KG4LLM协同模式示意图
模型预训练
KG增强LLM进行预训练的主要目的是利用外部知识,例如KG、词典或其他文本描述,加强模型的语言表示能力。预训练有两类实现方法,第一类集中于利用KG中的实体和关系信息,如GLM[2]、K-Adapter[3]等,直接将文本中的实体与KG实体对齐,从而捕捉文本中未明示的知识,利用实体关系的描述增强语言模型的表示能力。通过该方法,模型能够理解处理更复杂的关系,捕捉文本中未明示的知识,但效果依赖于KG的质量和完整性,在许多实际应用中,这对KG的更新和维护是一个挑战。第二类侧重于使用词典或其他形式的文本描述为模型提供丰富的背景知识,如E-BERT[4]、K-BERT[5]等,帮助模型更好地理解文本中的罕见词或实体,与其在词典中的定义描述对齐,提供更丰富的上下文信息及背景知识,有助于更好地理解和解释文本,但该方法依赖于词典或描述文本的质量和完整性,对于非常专业或领域特定的文本,可能缺乏足够的描述信息。
模型知识融合
在KG增强LLM的知识融合研究中,主要有两大类方法。基于检索增强的方法利用KG增强LLM的预测能力,该方法在生成结果或推理过程中,从大型外部KG中抽取与输入相关的外部信息辅助推理,主要优点在于能够动态利用丰富的外部知识,但可能需要更多的计算资源。QA-GNN[6]尝试从大型KG中识别信息,捕获问题上下文的细微差别,通过KG节点的相关性评分和联合推理,提高答题的效率和准确性,但其可能引入与问题上下文不相关的实体。JointLK[7]尝试解决子图中噪音节点的问题以及语言表示和KG表示之间互动有限的问题,支持语言模型和KG之间的多步联合推理,能够在两种模态间进行深入信息交互,但实际操作中可能需要更多的计算资源。其次是深度集成方法,这类方法在模型架构的多个层次上融合语言模型和KG的信息,使两者能够深入交互并相互补充,优点在于允许在整个模型架构的深入整合和交互,但可能需要大量的计算资源和复杂的模型设计。GreaseLM[8]尝试实现KG和LLM之间真正统一的融合,允许在架构的所有层面上进行深入整合和交互。
模型可解释性
为了更好理解和解释LLM的内部知识结构和行为[9],研究人员提出了多种方法。知识探测方法通过设计探测任务评估模型中的知识,尝试直接从模型中提取特定的知识。LAMA[10]通过完形填空任务评估LLM的关系知识,直观探测语言模型的知识,但模型可能对提示高度敏感。提示与查询优化方法的重点是如何为模型生成或优化提示,使其更好地提取知识,这些方法考虑到模型可能对不同的提示高度敏感,KagNet[11]利用知识图谱增强推理能力和可解释性。神经元与知识关联方法尝试探索模型的内部结构,解释模型如何存储知识,这类方法为模型的内部知识编码提供直观的解释,Dai等人[12]通过KG抽取提供模型的深入分析,为模型的行为提供清晰解释。
03
大语言模型增强的知识图谱(LLM4KG)
KG以结构化的方式表示知识,在问答、推荐等实际应用中发挥重要作用,然而,KG难以包含所有可能的实体、关系和事实,这种不完整性易导致重要信息缺失,限制KG在各种应用中的效用;其次,随着世界的不断演化发展,KG无法及时反映现实世界中的信息变化,导致KG中的信息更新滞后,不再准确有效;最后,KG的构建维护通常需要投入大量的人力资源用于手动整理、标注和更新大量的知识,成本高昂。
对此,可利用LLM所具有的泛化能力解决KG不完整所导致的信息不准确问题,如图3所示,研究人员提出了将LLM整合到KG中,以更充分地考虑文本信息,并提高下游任务性能。
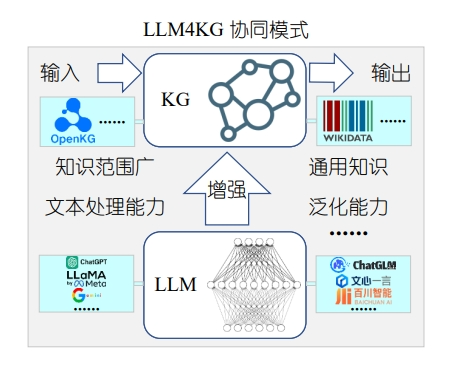
图2 LLM4KG协同模式示意图
知识图谱构建
构建大语言模型增强的知识图谱的方法主要归为五大类。KG与深度学习模型交互,如BOX4Types[13]等,这类方法通常基于现有的深度学习模型,如RNN、LSTM等,并令它们与KG进行交互,从文本中提取和利用知识,结合深度学习的学习效果和KG的丰富性,处理大量的文本数据并从中提取知识,但由于依赖深度学习模型,这类方法可能需要大量的计算资源。KG文本化方法,如CrossCR[14]等,通常将KG转化为文本格式并使用语言模型进行处理,能够充分利用预训练模型的优势,处理更复杂的关系和上下文,但转换过程可能导致信息丢失,且需要大量的数据和计算资源。
KG与LLM融合,如COMET[15]等,这类方法直接将KG和大型预训练模型(如BERT、GPT-3)结合在一起,直接从LLM中提取知识,处理大量的数据和复杂的关系,但由于依赖特定的预训练模型,可能会受到模型局限性的影响,且对计算资源的需求量大。KG自动生成与拓展,如Grapher[16]等,这些方法旨在从现有的数据和知识中自动生成和扩展KG,能够自动地生成和更新KG,处理大量数据和关系,但自动生成的知识可能不够准确,且需要复杂的算法和大量的计算资源。KG与符号计算结合的方法,如Curriculum-RE[17]等,这些方法结合了KG和符号计算方法,如知识蒸馏,能够结合符号计算的精确性和KG的丰富性,可以处理复杂的关系和上下文,但需要复杂的算法和大量的计算资源,且对数据的质量和完整性有很高的要求。
知识图谱补全
文本-序列建模方法将KG补全任务转化为一个序列到序列(Seq2Seq)的问题。这种方法主要利用Seq2Seq模型,如Transformer,对KG的实体和关系进行编码,并生成目标实体或关系。这些方法的核心优势在于其自然的处理方式,可直接将KG任务转化为文本生成任务,但可能面临处理长序列的挑战,或需要特定的训练策略优化性能。KG-BERT[18]采用BERT模型进行KG补全,通过调整BERT模型预测三元组的可信度,但可能会错过某些关系信息。GenKGC[19]用Seq2Seq的生成方式模拟KG补全,可以自然地将KG补全问题转换为生成任务。
对比学习和负采样策略方法强调使用对比学习和(或)负采样策略提高KG补全的效率和性能。对比学习通常涉及对正样本和负样本进行区分,而负采样策略则涉及选择与正样本不相关的样本进行训练。这些方法旨在有效地提取和区分KG中的关系,但可能需要大量的负样本实现最佳效果。SimKGC[20]通过增加三种负样本类型提高文本基于KG补全方法的效果,通过对比学习的方法提高了效率,但模型性能可能受到负采样比例低的影响与限制。
语言模型抽取方法使用如BERT或GPT等语言模型处理KG任务。这些方法试图从预训练模型中提取丰富的语言知识,并将其应用于KG补全。预训练模型的一个主要优势是它们已经在大量文本数据上进行了训练,从而捕获了丰富的语言和世界知识。然而,这种方法可能需要特定的调优策略才能在特定的KG任务上实现最佳性能。AutoKG[21]研究了LLM在KG构建和推理中的行为,有助于KG的自动化构建和推理。
语义和结构融合的方法旨在结合KG的结构信息和文本的语义信息,通常涉及使用图嵌入技术表示KG的结构,同时使用预训练的语言模型处理实体和关系的文本描述,以试图充分利用KG中的结构和语义信息。但要实现这种融合可能会遇到一些技术挑战。LASS[22]提出了一种联合的语言语义和结构嵌入方法,充分结合了KG的结构和语义信息。
其他方法采用独特的策略或技术执行KG任务,可能涉及特定的任务设置,如开放世界KG补全,或涉及特定的技术策略,如基于掩码语言建模(MLM)任务补全。这些方法可能特别适用于某些特定的KG场景或挑战。LP-BERT[23]利用MLM任务进行KG完善,采用多任务预训练策略。
知识图谱问答
随着KG和大规模语言模型在自然语言处理领域的广泛应用,研究者已经提出了多种将两者结合进行KG问答的方法。首先,诸如GreaseLM等KG与语言模型的深度交互方法重点关注KG与LLM之间的深入互动,确保两者信息能够完全交融和互补,它们不仅使用语言模型解析和理解问题,还确保KG中的信息与语言模型紧密集成,以提供结构化的答案,但可能需要复杂的训练策略确保KG和语言模型之间的有效交互,且模型的大小和复杂性可能导致效率低下的问题。
基于语言模型的KG文本化方法将KG转化为文本格式,利用预训练的语言模型进行处理,如OreoLM[24]等系统。它们强调将KG转化为文本形式,并使用预训练的语言模型处理,充分利用LLM的理解能力,同时确保KG中的信息得到正确的表示,可以直接利用预训练语言模型的能力,无须进行复杂的KG编码,可处理复杂的自然语言问题,并提供直接的答案,但将KG转化为文本可能会丢失一些结构信息,此外,系统还依赖高质量的KG文本化方法。
KG与语言模型的融合方法试图直接将两者结合在一起,如QA-GNN等,这类方法尝试直接融合KG和语言模型。它们通常使用图神经网络处理KG,并使用预训练的语言模型处理文本信息,提供了一个综合的方法处理KG和文本数据,能够直接利用KG和语言模型的优势,适用于各种KG和语言模型任务,但模型的复杂性可能导致训练和推理变得复杂,且需要大量的数据和计算资源。
04
知识图谱与大语言模型交互融合(KG+LLM)
LLM能够理解和生成自然语言,具有强大的文本理解和生成能力,能够从大量的文本数据中学习语言的语法、语义和上下文信息,从而自动处理和生成文本;KG则是一种结构化的知识表示形式,由实体、关系和属性组成。提供了事实知识的结构化表示,可用于存储和检索实体之间的关系,以及它们的属性和上下文信息。
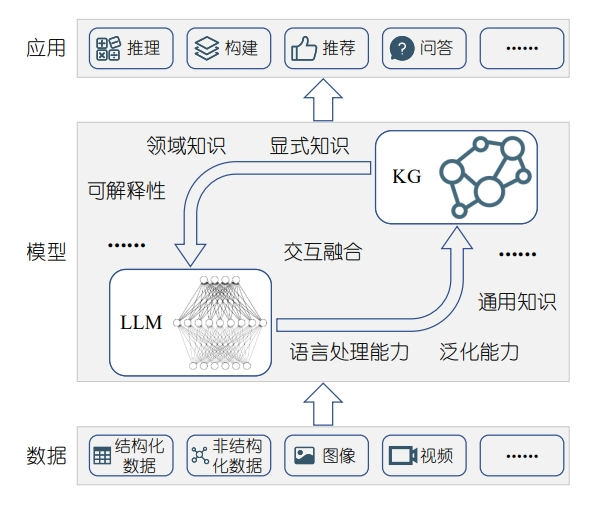
图3 KG+LLM协同模式示意图
为了同时发挥LLM和KG的优势,如图3所示,研究人员提出通过多轮迭代的方式将LLM与KG协同驱动,以获得更深入的语义理解、更丰富的知识表示和更强大的推理能力。
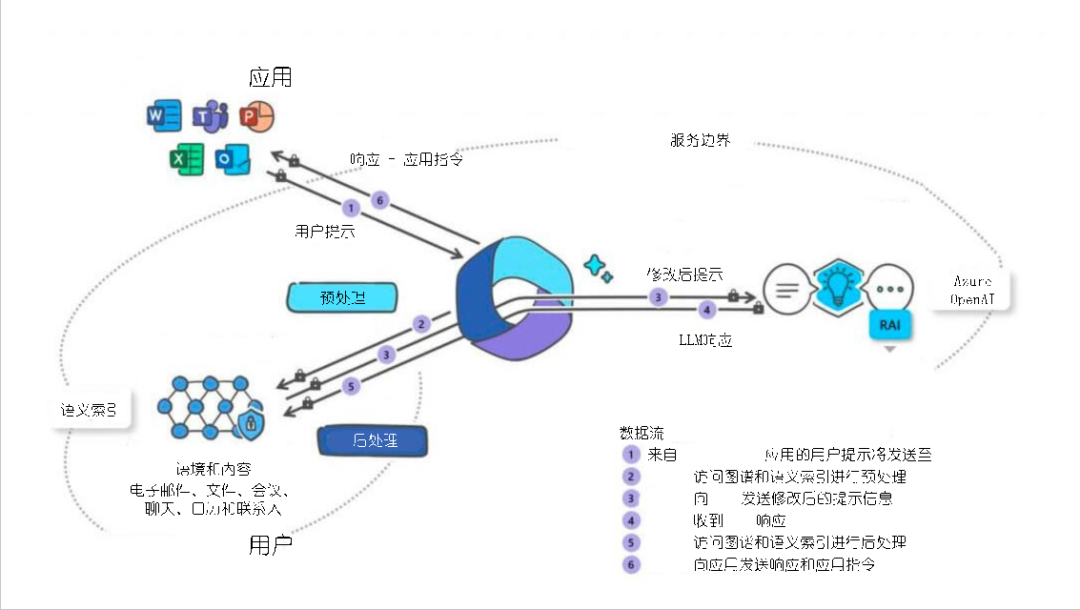
图4 基于KG+LLM的Microsoft 365 Copilot示意图
Microsoft 365 Copilot[25]是一个先进的助手系统,通过与知识图谱(Microsoft Graph)和LLM的交互整合Microsoft 365的各种应用程序以提供智能响应,这种结合为Microsoft 365 Copilot提供了巨大能量。KG确保响应基于用户的实际上下文和内容,而LLM为用户提供丰富自然的交互体验,使得Copilot不仅可以理解用户的请求,还可根据用户的数据和历史提供个性化的建议,这种结合确保用户获得的不仅仅是一般性的回答,而是真正有用而相关的信息。当用户在Microsoft 365应用中发出提示或命令时,这些提示首先经过预处理阶段,从Microsoft Graph和语义索引中获取相关的上下文和内容信息,以确保响应是针对性的;预处理完毕,提示被修改并转发给LLM进行深度处理和响应生成;LLM处理用户请求并生成响应,响应进入后处理阶段;再次访问Microsoft Graph和语义索引进一步完善或修改响应;最终,响应和可能的应用指令被发送回用户的Microsoft 365应用。
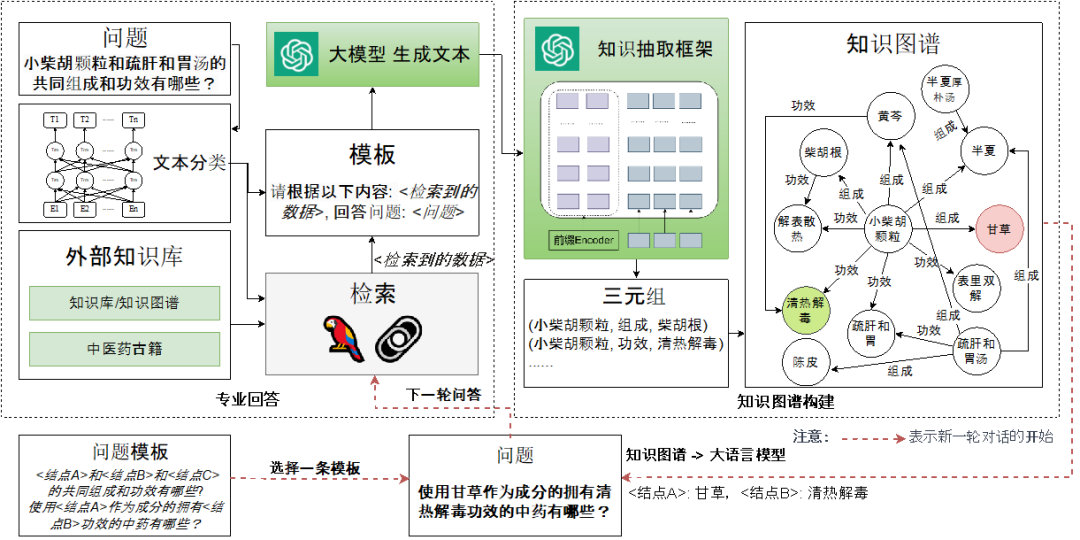
图5 基于KG+LLM的“中医药方剂”垂直领域问答方法示意图
在该研究方向,我们提出了一个中医药领域KG与LLM交互融合的问答方法[26],旨在通过KG与LLM的深度整合提供专业的中医药垂直领域问答服务。如图4所示,该方法具有信息过滤、专业问答以及抽取转化等关键功能,确保信息的准确性,减少错误信息的产生;通过LangChain技术的应用,本方法能够在不需要重训LLM的前提下,提供专业且准确的回答,同时避免高昂的硬件成本和潜在的灾难性遗忘问题;通过将自然语言文本转化为KG结构化数据,系统不仅能够提升回答的专业性,还能够通过用户易于理解的方式展现复杂信息。本方法的互动流程从用户提问开始,经过信息过滤、与知识库提示的结合、专业问答处理,最后通过三元组抽取与KG匹配来增强回答内容,该流程不仅增强了知识的深度和范围,还提高了用户交互的友好性。这一新型问答设计模式有效结合了LLM的强大处理能力和KG的专业知识结构,为用户提供了一个既准确又专业,同时用户体验友好的问答方法。
05
未来方向
尽管知识图谱与大语言模型协同的设计模式取得了突出效果,但仍面临一些问题和挑战,笔者预测可以从以下几个方向开展研究:

图6 未来方向脉络图
1、知识图谱与大语言模型协同模式有望成为“神经+符号”人工智能的突破点。
KG具备显式(符号)知识表示,可以为隐式(神经)知识表示的LLM提供明确、结构化的知识源,通过将KG和LLM结合,可以使用KG明确的事实引导LLM的输出,从而减少或消除错误表达;其次,KG可以解决LLM的知识更新问题,KG可持续更新信息和数据,将KG与LLM结合,意味着LLM可以获取到最新的信息,确保其输出的时效性与准确性。
2、知识图谱与大语言模型协同模式有望开辟通向通用人工智能研究的新方法。
基于LLM的底层能力,如自然语言理解及生成等,引入KG为高层机制,提供明确的知识结构和逻辑关系,这种结合可以确保系统既具备广泛常识和信息处理能力,又能够进行逻辑化推理,通过持续训练和优化,逐步实现通用人工智能(AGI)的目标。
3、知识图谱与大语言模型协同模式有望成为人工智能在各领域落地的新模式。
不同领域有不同要求和挑战,例如,医疗领域要求高准确性和可靠性,而金融领域则更加重视风险管理,为满足不同领域的需求,KG与LLM的协同模式还有很多工作可做。KG与LLM的协同模式可以为Copilot助手提供更强大、更准确的支持,KG提供明确的知识结构,而LLM提供强大的文本理解和生成能力,从而使Copilot助手可以更好地理解用户需求,提供更准确的建议和解决方案,有效协助人类完成任务。
参考文献
[1] Pan SR, Luo LH, Wang YF, et al. Unifying Large Language Models and Knowledge Graphs: A Roadmap. arXiv preprint arXiv:2306.08302, 2023.
[2] Shen T, Mao Y, He P, et al. Exploiting structured knowledge in text via graph-guided representation learning[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Online: Association for Computational Linguistics. 2020,11:8980-8994.
[3] Wang R, Tang D, Duan N, et al. K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Online: Association for Computational Linguistics. 2021,8:1405-1418.
[4] Zhang D, Yuan Z, Liu Y, et al. E-BERT: A phrase and product knowledge enhanced language model for e-commerce[OL]. arXiv preprint arXiv:2009.02835, 2020.
[5] Liu W, Zhou P, Zhao Z, et al. K-BERT: enabling language representation with knowledge graph[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. 2022:2901-2908.
[6] Yasunaga M, Ren H, Bosselut A, et al. QAGNN: Reasoning with language models and knowledge graphs for question answering[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 535-546.
[7] Sun Y, Shi Q, Qi L, et al. JointLK: Joint reasoning with language models and knowledge graphs for commonsense question answering[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022: 5049-5060.
[8] Zhang X, Bosselut A, Yasunaga M, et al. Greaselm: Graph reasoning enhanced language models[C]// International Conference on Learning Representations, ICLR2022. 2022.
[9] Wei J, Wang X, Schuurmans D, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv preprint arXiv:2201.11903, 2023.
[10] Petroni F, Rocktäschel T, Riedel S, et al. Language models as knowledge bases?[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 2463-2473.
[11] Lin B Y, Chen X, Chen J, et al. Kagnet: Knowledgeaware graph networks for commonsense reasoning[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 2829-2839.
[12] Dai D, Dong L, Hao Y, et al. Knowledge neurons in pretrained transformers [OL] arXiv preprint arXiv:2104.08696, 2021.
[13] Onoe Y, Boratko M, McCallum A, et al. Modeling fine-grained entity types with box embeddings[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers). 2022: 2051–2064 .
[14] Cattan A, Eirew A, Stanovsky G, et al. Crossdocument coreference resolution over predicted mentions[C]// Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021. 2021: 5100-5107.
[15] Bosselut A, Rashkin H, Sap M, et al. Comet: Commonsense transformers for knowledge graph construction[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 4762-4779.
[16] Melnyk I, Dognin P, Das P. Grapher: Multi-stage knowledge graph construction using pretrained language models[C]// NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021.
[17] Park S, Kim H. Improving sentence-level relation extraction through curriculum learning [OL]. arXiv preprint arXiv:2107.09332 .
[18] Yao L, Mao C, Luo Y. KG-BERT: BERT for knowledge graph completion[OL]. arXiv preprint arXiv:2007.00655
[19] Xie X, Zhang N, Li Z, et al. From discrimination to generation: Knowledge graph completion with generative transformer[C]// WWW '22: Companion Proceedings of the Web Conference 2022. 2022: 162-165.
[20] Wang L, Zhao W, Wei Z, et al. Simkgc: Simple contrastive knowledge graph completion with pre-trained language models[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022: 4281–4294.
[21] Zhu Y, Wang X, Chen J, et al. Llms for knowledge graph construction and reasoning: Recent capabilities and future opportunities [OL]. arXiv preprint arXiv:2305.13168, 2023.
[22] Shen C, Wang C, Gong L, et al. Joint language semantic and structure embedding for knowledge graph completion[C]// Proceedings of the 29th International Conference on Computational Linguistics.2022: 1965-1978.
[23] Li D, Yi M, He Y. Lp-bert: Multi-task pre-training knowledge graph bert for link prediction [OL]. arXiv preprint arXiv:2201.04843, 2022.
[24] Hu Z, Xu Y, Yu W, et al. Empowering language models with knowledge graph reasoning for open-domain question answering[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 9562-9581.
[25] Introducing Microsoft 365 Copilot,https://blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot-your-copilot-for-work/
[26] 张鹤译, 王鑫, 韩立帆, 李钊, 陈子睿, 陈哲. 大语言模型融合知识图谱的问答系统研究[J]. 计算机科学与探索, 2023, 17(10): 2377-2388.
以上就是本次分享的内容,谢谢。


作者简介
INTRODUCTION

王鑫

天津大学教授

王鑫,CCF杰出会员、CCF信息系统专委会秘书长、CCF数据库专委会执行委员、CCF大数据专家委员会执行委员。天津大学教授。主要研究方向为知识图谱、图数据库。联系方式:wangx@tju.edu.cn

作者简介
INTRODUCTION

陈子睿

天津大学博士生

陈子睿,CCF学生会员。天津大学博士生。主要研究方向为大语言模型、知识图谱表示学习。联系方式:zrchen@tju.edu.cn

作者简介
INTRODUCTION

王昊奋

同济大学特聘研究员、博导

王昊奋,CCF 高级会员,CCF 上海分部秘书长、CCF SIGKG 主席、术语工委副主任,OpenKG联合发起人。同济大学百人计划特聘研究员,博士生导师。主要研究方向为知识图谱、自然语言处理。联系方式:carter.whfcarter@gmail.com
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
这篇关于“新KG”视点 | 知识图谱与大语言模型协同模式探究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









