本文主要是介绍heartbeat(一) heartbeat v2 haresource配置高可用集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
heartbeat(一)
heartbeat v2 haresource配置高可用集群
上一篇《LINUX集群—高可用 高可用集群》认识高可用集群的一些基本概念,下面将会用heartbeat v2及版本中的haresource配置简单的高可用WEB集群。
1、高可用集群架构设计
通过上一篇我们知道,heartbeat v2提供了完整的高可用方案,既包含了Messaging Layer,又包含CRM,其中CRM有haresource(默认)和crm,本文基于haresource配置,具体架构资源如下:

1、节点主机系统:RHEL 5.8 64bit
2、高可用集群软件:Heartbeat v2 haresource
3、两台节点主机node1,node2:
Node1: IP:192.168.18.241 host name:node1.tjiyu,com;
Node2: IP:192.168.18.242 host name:node2.tjiyu.com;
VIP: 192.168.18.240
4、所提供服务:WEB(httpd)
2、heartbeat配置前所需要的准备
2-1、配置IP、安装WEB服务、关闭防火墙
按照上面设计配置两台节点主机IP,并能ping测试:

分别安装httpd服务,为方便测试,这里两节点分别提供不同的提示页面,然后手动访问测试,测试通过后关闭httpd,禁止开机启动:

关闭selinux和防火墙:
setenforce 0
service iptables stop
2-2、配置各节点名称
集群信息传递需要各节点间能相互识别,而节点间的识别是靠节点名称,同时保证每个节点的名称都得能互相解析为节点主机的IP地址。
这个最好不用DNS,因为DNS服务也需要提供高可用才行,否则DNS出问题就导致整个集群不能可用。所以直接在各节点中配置一样的/etc/hosts文件,必须保证/etc/hosts中主机名的正反解析结果必须跟"uname -n"执行结果保持一致。
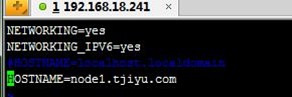
1、配置节点名称如下:
[root@localhost ~]# vim /etc/sysconfig/network
[root@localhost ~]# hostname node2.tjiyu.com
[root@localhost ~]# uname -n
node2.tjiyu.com

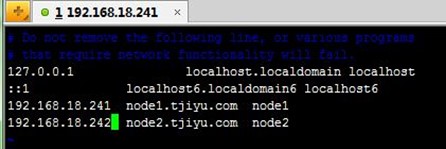
2、node1配置/etc/hosts文件,并远程复制到node2上, 然后node1和node2上都要ping 对方名称测试:
[root@node1 ~]# vim /etc/hosts
[root@node1 ~]# scp /etc/hosts node2.tjiyu.com:/etc/
[root@node1 ~]# ping node2.tjiyu.com
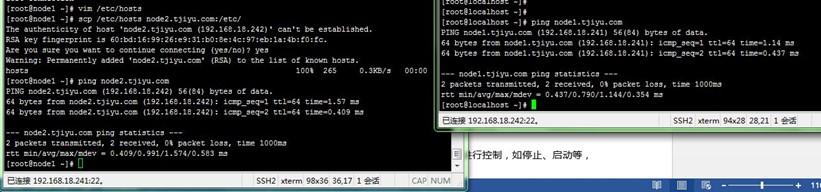
2-3、建立各节点间的SSH互信通信
高可用集群中一个(正常)节点需要对另外(故障)节点进行控制,如停止、启动等,这需要各节点间能使用管理员权限以基于SSH密钥认证通信。
具体配置如下:
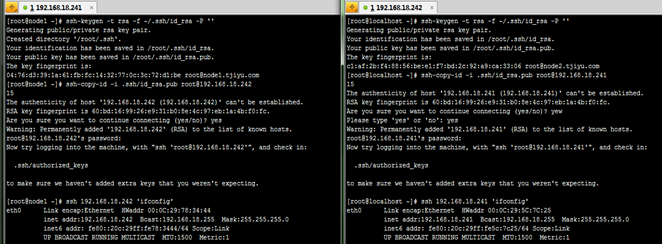
1、生成RSA类型的SSH密钥,输出保存到~/.ssh/id_rsa,密码为空:
[root@node1 ~]# ssh-keygen -t rsa -f ~/.ssh/id_rsa -P ''
2、把生成的密钥复制到远程主机(node2)的.ssh/id_rsa.pub,后面指定主机用户和地址,然后执行会提示输入该用户对应的密码:
[root@node1 ~]# ssh-copy-id -i .ssh/id_rsa.pubroot@192.168.18.242
3、经过上面两步就可实现SSH免密码登录远程主机(node2)了,测试下:
[root@node1 ~]# ssh 192.168.18.242 'ifconfig'
4、两台主机具体配置过程如下图:
2-4、各节点间的时间同步
一些集群节点间的事务依赖比较严格的时间同步,如心跳是否超时。可以使用ntpd服务或ntpdate来实现同步网络时间服务器的时间,ntpd服务是渐变同步的,配置稍复杂,但效果好,实际最好用ntpd;ntpdate一次跳变同步,比较简单,这里先用ntpdate的方式来配置.
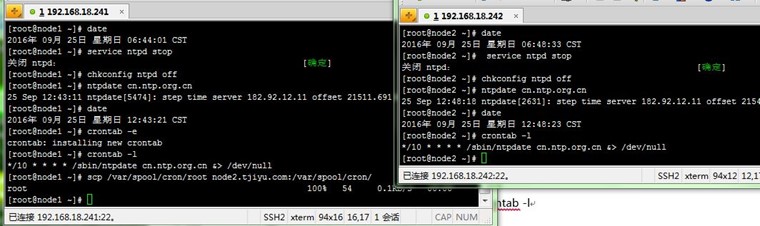
先关了ntpd服务,然后再用ntpdate同步中国区NTP服务器上的时间(也可用自己建的NTP服务器);同时在node1上用crontab任务配置了每10分同步一次的计划,然后远程复制到node2,具体配置如下:
[root@node1 ~]# date
2016年 09月 25日 星期日 06:44:01 CST
[root@node1 ~]# service ntpd stop
关闭 ntpd: [确定]
[root@node1 ~]# chkconfig ntpd off
[root@node1 ~]# ntpdate cn.ntp.org.cn
25 Sep 12:43:11 ntpdate[5474]: step time server 182.92.12.11 offset 21511.691663 sec
[root@node1 ~]# date
2016年 09月 25日 星期日 12:43:21 CST
[root@node1 ~]# crontab -e
crontab: installing new crontab
[root@node1 ~]# crontab -l
*/10 * * * * /sbin/ntpdate cn.ntp.org.cn &> /dev/null
[root@node1 ~]# scp /var/spool/cron/root node2.tjiyu.com:/var/spool/cron/
3、heartbeat v2下载安装
可以到EPEL下载,网址:https://dl.fedoraproject.org/pub/epel/5/x86_64/,下载包括:Heartbeat(高可用核心)、heartbeat-devel(开发包,不安装)、heartbeat-gui(图形接口)、heartbeat-ldirectord(LVS后端服务健康检查、不安装)、heartbeat-pils(插件和库)、heartbeat-stonith(STONITH设备控制),还要一起下载一个叫libnet的依赖库。
下载放到两台主机上,分别执行安装即可:# yum --nogpgcheck localinstall heartbeat-2.1.4-11.el5.x86_64.rpm heartbeat-gui-2.1.4-11.el5.x86_64.rpm heartbeat-pils-2.1.4-11.el5.x86_64.rpm heartbeat-stonith-2.1.4-11.el5.x86_64.rpm libnet-1.1.6-7.el5.x86_64.rpm。
4、heartbeat v2相关配置
heartbeat v2默认使用haresource为CRM,涉及到三个配置文件:
1、authkeys:密钥认证文件,600权限;
2、ha.cf:heartbeat服务的配置文件;
3、haresources:资源管理配置文件;
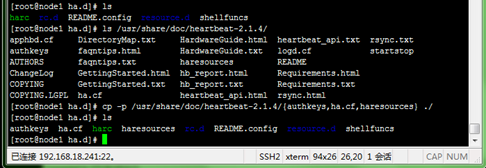
Heartbeat配置文件目录在/etc/ha.d/,但发现初始没有在该目录下发现这三个文件,所以先到/usr/share/doc/heartbeat-2.1.4/目录把这三个样例文件保留权限地复制到/etc/ha.d/,如下所示:
[root@node1 ~]# cd /etc/ha.d/
[root@node1 ha.d]# cp -p /usr/share/doc/heartbeat-2.1.4/{authkeys,ha.cf,haresources} ./
4-1、配置authkeys密钥认证文件
[root@node1 ha.d]# chmod 600 authkeys
[root@node1 ha.d]# vim authkeys
auth 3 #认证加密方式,下面'3'
3 md5 56tfd43r7u7ij #md5,加随机的盐
4-2、ha.cf:配置heartbeat服务
[root@node1 ha.d]# vim ha.cf
#logfile /var/log/ha-log #日志文件
logfacility local0 #日志记录设备
keepalive 2 #多久发一次心跳(秒)
deadtime 15 #脑裂等不正常事件后,多久认为对方故障(秒)
warntime 10 #在日志中发出"late heartbeat"警告之前等待的时间
#initdead 120 #在某些配置下,重启后网络需要一些时间才能正常工作。这个单独的"deadtime"选项可以处理这种情况。它的取值至少应该为通常deadtime的两倍
udpport 694 #使用端口694进行bcast和ucast通信。这是默认的,并且在IANA官方注册的端口号。
bcast eth0 # 集群消息的传递方式,广播,Linux可用
#mcast eth0 225.0.0.1 694 1 0 #组播
#ucast eth0 192.168.1.2 #单播
auto_failback on #一旦主节点重新恢复联机,将从从节点取回所有资源。若该选项设置为off,主节点便不能重新获得资源。
#stonith baytech /etc/ha.d/conf/stonith.baytech #定义STONITH设备
node node1.tjiyu.com #定义集群所有节点,后面节点名称必须与"uname -n"一致
node node2.tjiyu.com #定义集群所有节点
ping 192.168.18.101 #ping第三方设备(这里ping网关),上一篇说到的如何判断对方故障
4-3、haresources:配置资源管理
[root@node1 ha.d]# vim haresources
node1.tjiyu.com IPaddr::192.168.18.240/24/eth0 httpd
#每一行表示一个资源(组),这里表示node1.tjiyu.com节点为首先运行的主节点,然后通过~/ha.d/resource.d/目录下的资源代理IPaddr来配置VIP,使其配置在eth0的别名上,最后就是通过/etc/rc.d/init.d/目录下LSB资源代理脚本来管理httpd服务。
4-4、三个文件远程复制到node2
上面在node1上配置好了这三个文件,可以直接远程复制到node2上,内容、权限都一样:
[root@node1 ha.d]# scp -p authkeys haresources ha.cf node2:/etc/ha.d/
5、启动测试
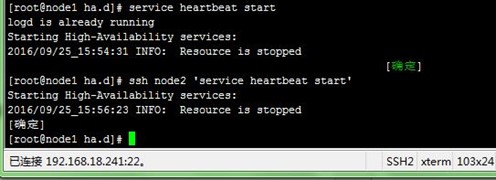
1、在node1上先启动自己的heartbeat服务,再SSH远程启动node2的;
[root@node1 ha.d]# service heartbeat start
[root@node1 ha.d]# ssh node2 'service heartbeat start'
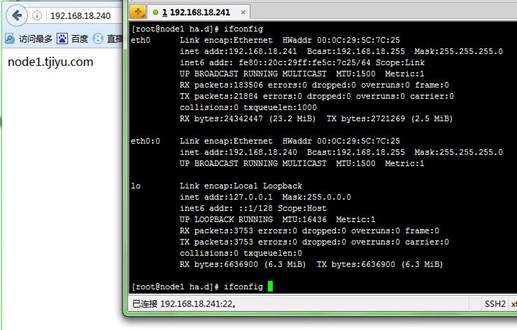
2、查看启动日志,查看VIP配置在node1的eth0的别名上,再通过浏览器访问VIP,返回的是node1测试页面:
[root@node1 ha.d]# tail -f /var/log/messages
[root@node1 ha.d]# ifconfig
3、在node1上运行使/usr/share/heartbeat/hb_standby脚本,使node1成为standy节点,node2成为主节点;查看VIP配置在node2的eth0的别名上,再通过浏览器访问VIP,返回的是node2测试页面:
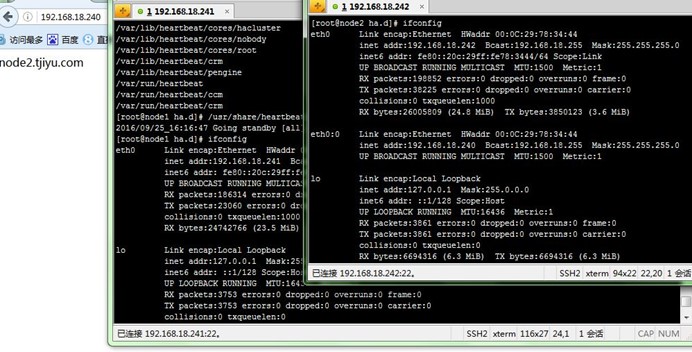
4、在node2上运行使/usr/share/heartbeat/hb_standby脚本,使node2成为standy节点,node1重新成为主节点;查看VIP配置在node1的eth0的别名上,再通过浏览器访问VIP,返回的是node1测试页面:
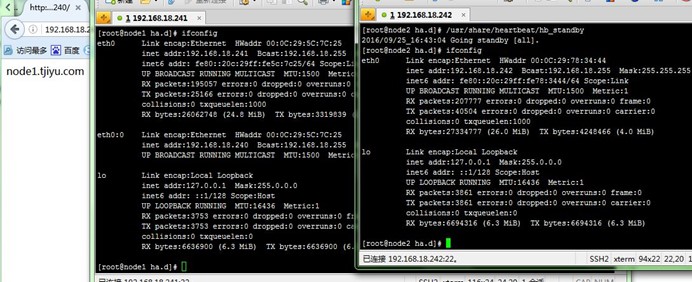
以上测试说明heartbeat提供了高可用功能。
经过写这篇文章,对heartbeat v2 haresource配置高可用集群有了一个比较全面的认识,下面还将在本篇基础上进行NFS共享WEB文件的应用配置……
【参考资料】
1、Pacemaker:http://clusterlabs.org/wiki/Pacemaker
2、High-availability cluster:https://en.wikipedia.org/wiki/High-availability_cluster#Node_configurations|
3、高可用集群基本概念与heartbeat文本配置接口:http://www.178linux.com/10982
4、heartbeat配置文件ha.cf haresources authkeys详解:https://www.centos.bz/2012/03/heartbeat-ha-cf-haresources-authkeys/
这篇关于heartbeat(一) heartbeat v2 haresource配置高可用集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








