本文主要是介绍数据分析实战 | K-means算法——蛋白质消费特征分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、数据及分析对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据准备
七、模型训练
编辑 八、模型评价
九、模型调参与预测
一、数据及分析对象
txt文件——“protein.txt”,主要记录了25个国家的9个属性,主要属性如下:
(1)ID:国家的ID。
(2)Country(国家类别):该数据涉及25个欧洲国家肉类和其他食品之间的关系。
(3)关于肉类和其他食品的9个数据包括RedMeat(红肉)、WhiteMeat(白肉)、Eggs(蛋类)、Milk(牛奶)、Fish(鱼类)、Cereals(谷类)、Starch(淀粉类)、Nuts(坚果类)、Fr&Veg(水果和蔬菜)。
二、目的及分析任务
理解机器学习方法在数据分析中的应用——采用k-means方法进行聚类分析。
(1)将数据集导入后,在初始化阶段随机选择k个类簇进行聚类,确定初始聚类中心。
(2)以初始化后的分类模型为基础,通过计算每一簇的中心点重新确定聚类中心。
(3)迭代重复“计算距离——确定聚类中心——聚类”的过程。
(4)通过检验特定的指标来验证k-means模型聚类的正确性和合理性。
三、方法及工具
scikit-learn、pandas和matplotlib等Python工具包。
四、数据读入
import pandas as pd
protein=pd.read_table("D:\\Download\\JDK\\数据分析理论与实践by朝乐门_机械工业出版社\\第5章 聚类分析\\protein.txt",sep='\t')
protein.head()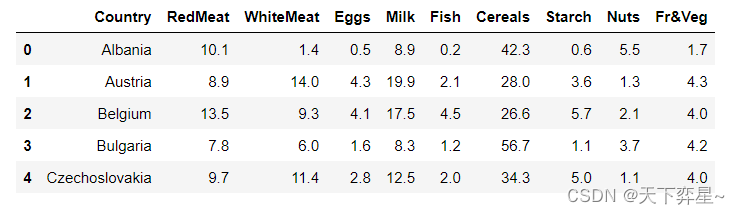
五、数据理解
对数据框protein进行探索性分析,这里采用的实现方式为调用pandas包中数据框(DataFrame)的describe()方法。
protein.describe()
除了describe()方法,还可以调用shape属性和pandas_profiling包对数据框进行探索性分析。
protein.shape(25, 10)
六、数据准备
在进行不同国家蛋白质消费结果分析时,要把对信息分析有用的数据提取出来,即关于肉类和其他食品的9列。具体实现方式为调用pandas包中数据框的drop()方法,删除列名“Country”的数据。
sprotein=protein.drop(['Country'],axis=1)
sprotein.head()
将待聚类数据提取后,需要对该数据集进行以均值为中心的标准化处理,在此采用的是统计学中的Z-Score标准化方法。
from sklearn import preprocessing
sprotein_scaled=preprocessing.scale(sprotein)
sprotein_scaledarray([[ 0.08294065, -1.79475017, -2.22458425, -1.1795703 , -1.22503282,0.9348045 , -2.29596509, 1.24796771, -1.37825141],[-0.28297397, 1.68644628, 1.24562107, 0.40046785, -0.6551106 ,-0.39505069, -0.42221774, -0.91079027, 0.09278868],[ 1.11969872, 0.38790475, 1.06297868, 0.05573225, 0.06479116,-0.5252463 , 0.88940541, -0.49959828, -0.07694671],[-0.6183957 , -0.52383718, -1.22005113, -1.2657542 , -0.92507375,2.27395937, -1.98367386, 0.32278572, 0.03621022],[-0.03903089, 0.96810416, -0.12419682, -0.6624669 , -0.6851065 ,0.19082957, 0.45219769, -1.01358827, -0.07694671],[ 0.23540507, 0.8023329 , 0.69769391, 1.13303099, 1.68457011,-0.96233157, 0.3272812 , -1.21918427, -0.98220215],[-0.43543839, 1.02336124, 0.69769391, -0.86356267, 0.33475432,-0.71124003, 1.38907137, -1.16778527, -0.30326057],[-0.10001666, -0.82775116, -0.21551801, 2.38269753, 0.45473794,-0.55314536, 0.51465594, -1.06498727, -1.5479868 ],[ 2.49187852, 0.55367601, 0.33240914, 0.34301192, 0.42474204,-0.385751 , 0.3272812 , -0.34540128, 1.33751491],[ 0.11343353, -1.35269348, -0.12419682, 0.07009624, 0.48473385,0.87900638, -1.29663317, 2.4301447 , 1.33751491],[-1.38071781, 1.24438959, -0.03287563, -1.06465843, -1.19503691,0.73021139, -0.17238476, 1.19656871, 0.03621022],[ 1.24167025, 0.58130455, 1.61090584, 1.24794286, -0.62511469,-0.76703815, 1.20169663, -0.75659327, -0.69930983],[-0.25248108, -0.77249407, -0.03287563, -0.49009911, -0.26516381,0.42332173, -1.35909141, 0.63117972, 1.45067184],[-0.10001666, 1.57593211, 0.60637272, 0.90320726, -0.53512697,-0.91583314, -0.04746827, -0.65379528, -0.24668211],[-0.13050955, -0.88300824, -0.21551801, 0.88884328, 1.62457829,-0.86003502, 0.20236471, -0.75659327, -0.81246676],[-0.89283166, 0.63656164, -0.21551801, 0.31428395, -0.38514744,0.35822393, 1.0143219 , -0.55099728, 1.39409338],[-1.10628185, -1.15929368, -1.67665709, -1.75412962, 2.97439408,-0.48804755, 1.0143219 , 0.83677571, 2.12961342],[-1.10628185, -0.44095155, -1.31137232, -0.86356267, -0.98506557,1.61368162, -0.73450896, 1.14516971, -0.75588829],[-0.83184589, -1.24217931, 0.14976676, -1.22266225, 0.81468882,-0.28345445, 0.88940541, 1.45356371, 1.73356417],[ 0.02195488, -0.0265234 , 0.51505153, 1.08993904, 0.96466835,-1.18552405, -0.35975949, -0.85939127, -1.20851601],[ 0.99772718, 0.60893309, 0.14976676, 0.96066319, -0.59511878,-0.61824316, -0.9218837 , -0.34540128, 0.43225947],[ 2.30892121, -0.60672281, 1.61090584, 0.50101573, 0.00479935,-0.73913909, 0.26482296, 0.16858872, -0.47299597],[-0.16100243, -0.91063679, -0.76344517, -0.07354359, -0.38514744,1.05570042, 1.32661312, 0.16858872, -0.69930983],[ 0.47934814, 1.27201813, 1.06297868, 0.24246404, -0.26516381,-1.26922123, 0.57711418, -0.80799227, -0.19010364],[-1.65515377, -0.80012261, -1.5853359 , -1.0933864 , -1.10504919,2.19956187, -0.79696721, 1.35076571, -0.52957443]])
七、模型训练
在使用k-means算法对其数据集进行聚类之前,我们在初始化阶段产生一个随机的k值作为类簇的个数。在scikit-learn框架中,使用“决定系数’作为性能评估的分数(score),该参数可以判断不同分类情况的统计模型对数据的拟合能力。这里采用的实现方式是调用sklearn.cluster模块的k-means.fit().score()方法。
#K值得选择
from sklearn.cluster import KMeans
NumberOfClusters=range(1,20)
kmeans=[KMeans(n_clusters=i) for i in NumberOfClusters]
score=[kmeans[i].fit(sprotein_scaled).score(sprotein_scaled) for i in range(len(kmeans))]
score[-225.00000000000003,-139.5073704483181,-110.40242709032155,-93.99077697163418,-77.34315775475405,-64.22779496320605,-52.68794493054983,-46.148487504020046,-41.95277071693863,-35.72656669867341,-30.429164116494334,-26.430420929243024,-22.402609200395787,-19.80060035995764,-16.86466531666006,-13.979313757304398,-11.450822978023083,-8.61897844282252,-6.704106008601115]
上面的输出结果为每一个kmeans(n_clusters=i)(1<=i<=19)的预测值,为更直观地观察每个值的变化情况,可绘制一个ROC曲线。具体实现方式是调用matplotlib包的pyplot()方法。
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(NumberOfClusters,score)
plt.xlabel('Number of Clusters')
plt.ylabel('Score')
plt.title('Elbow Curve')
plt.show()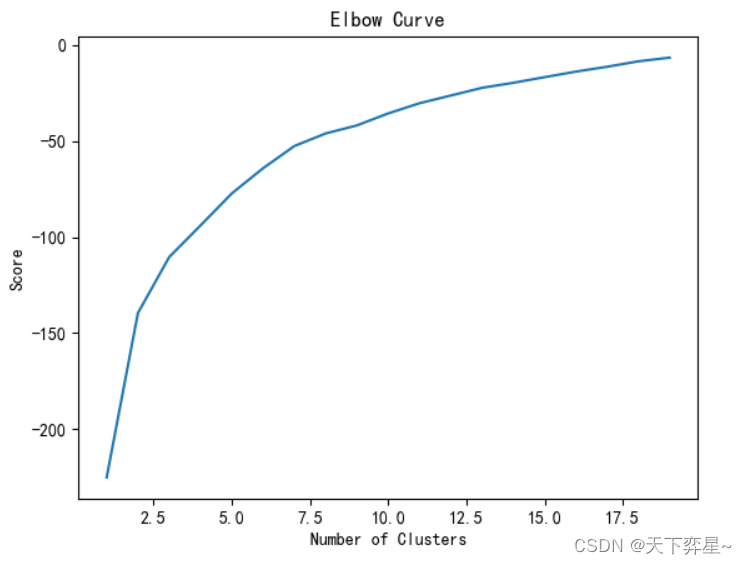
接着,随机设定聚类的数目为5,并以此为基础在数据矩阵上执行均值聚类,并查看模型预测结果,这里的具体实现方式是调用scikit-learn包的KMeans()方法和predict()方法,其中KMeans()方法需要设置的主要参数如下:
(1)algorithm使用默认值"auto",表示使用k-means中的elkan或full算法,由样本数据的稠密程度决定。
(2)n_clusters表示分类簇的数量。
(3)n_init表示运行该算法的尝试初始化次数。
(4)max_iter表示最大的迭代次数。
(5)verbose表示日志信息,这里使用默认“0”值,不输出日志信息。
myKMeans=KMeans(algorithm="auto",n_clusters=5,n_init=10,max_iter=200,verbose=0)
myKMeans.fit(sprotein_scaled)
y_kmeans=myKMeans.predict(sprotein)
print(y_kmeans)[2 4 4 2 4 4 4 3 4 2 2 4 2 4 4 4 0 2 2 4 4 4 2 4 2]
通过以上分析,由确定的k=5,将数据集protein划分成5个类簇,类簇编号为0,1,2,3,4.接下来,显示每个样本所属的类簇编号。
protein["所隶属的类簇"]=y_kmeans
protein
 八、模型评价
八、模型评价
可见,k-means算法可以完成相对应的聚类输出。接下来,引入轮廓系数对宣发聚类结果进行评价。这里采用的实现方式为调用Bio包Cluster模块的kcluster()方法,并调用silhouette_score()方法返回所有样本的轮廓系数,取值范围为[-1,1],轮廓系数值越大越好。
from sklearn.metrics import silhouette_score
silhouette_score(sprotein,y_kmeans)0.2222236683250513
number=range(2,20)
myKMeans_list=[KMeans(algorithm="auto",n_clusters=i,n_init=10,max_iter=200,verbose=0) for i in number]
y_kmeans_list=[myKMeans_list[i].fit(sprotein_scaled).predict(sprotein_scaled) for i in range(len(number))]
score=[silhouette_score(sprotein,y_kmeans_list[i]) for i in range(len(number))]score[0.4049340501486218,0.31777138102456476,0.16996270462188423,0.21041645106099247,0.1943500298289292,0.16862742616667453,0.1868090290661263,0.08996856437394235,0.10531808817576255,0.13528249120860153,0.07381598489593617,0.09675173868153258,0.056460835203354785,0.10871862224667578,0.04670651599769748,0.03724019668260051,0.0074356180520073045,0.013165944671952217]
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.plot(number,score)
plt.xlabel("k值")
plt.ylabel("轮廓系数")
九、模型调参与预测
通过轮廓系数的分析,我们可以确定聚类中心的数量为2,并以此为基础在样本数据集protein上执行聚类。
estimator=KMeans(algorithm="auto",n_clusters=2,n_init=10,max_iter=200,verbose=0)
estimator.fit(sprotein_scaled)
y_pred=estimator.predict(sprotein_scaled)
print(y_pred)[1 0 0 1 0 0 0 0 0 1 1 0 1 0 0 0 1 1 1 0 0 0 1 0 1]
绘制聚类图:
x1=[]
y1=[]
x2=[]
y2=[]
for i in range(len(y_pred)):if y_pred[i]==0:x1.append(sprotein['RedMeat'][i])y1.append(sprotein['WhiteMeat'][i])if y_pred[i]==1:x2.append(sprotein['RedMeat'][i])y2.append(sprotein['WhiteMeat'][i])
plt.scatter(x1,y1,c="red")
plt.scatter(x2,y2,c="orange")
plt.show()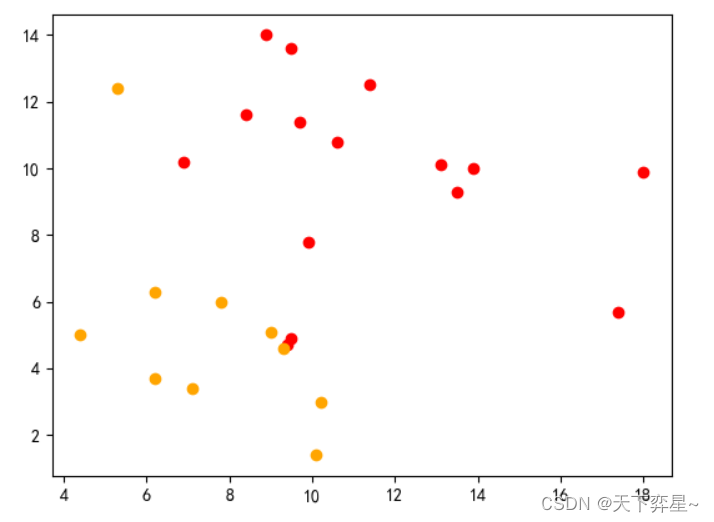
这篇关于数据分析实战 | K-means算法——蛋白质消费特征分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





