本文主要是介绍Doris:多源数据目录(Multi-Catalog),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.基本概念
2.基本操作
2.1 查看 Catalog
2.2 新增 Catalog
2.3 切换 Catalog
2.4 删除 Catalog
3.元数据更新
3.1手动刷新
3.2定时刷新
3.3自动刷新
4.JDBC Catalog
4.1 上传mysql驱动包
4.2 创建mysql catalog
4.3. 读取mysql数据
1.基本概念
多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。
Multi-Catalog 功能在原有的元数据层级上,新增一层Catalog,构成 Catalog -> Database -> Table 的三层元数据层级。其中,Catalog 可以直接对应到外部数据目录。Internal Catalog 是内置的默认 Catalog,用户不可修改或删除。目前支持的外部数据目录包括:
- Apache Hive
- Apache Iceberg
- Apache Hudi
- Elasticsearch
- JDBC: 对接数据库访问的标准接口(JDBC)来访问各式数据库的数据。
- Apache Paimon(Incubating)
2.基本操作
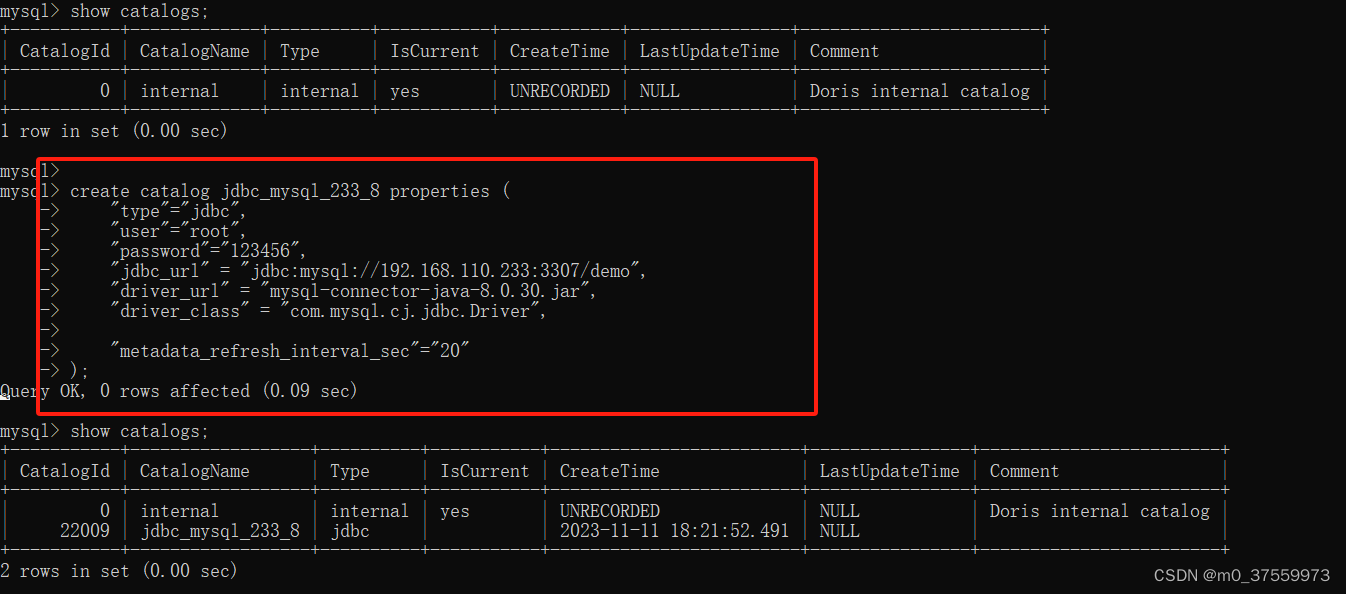
2.1 查看 Catalog
show catalogs;

2.2 新增 Catalog
create catalog jdbc_mysql_233_8 properties (
"type"="jdbc",
"user"="root",
"password"="123456",
"jdbc_url" = "jdbc:mysql://192.168.110.233:3307/demo",
"driver_url" = "mysql-connector-java-8.0.30.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver","metadata_refresh_interval_sec"="20"
);
2.3 切换 Catalog
switch catalog_name
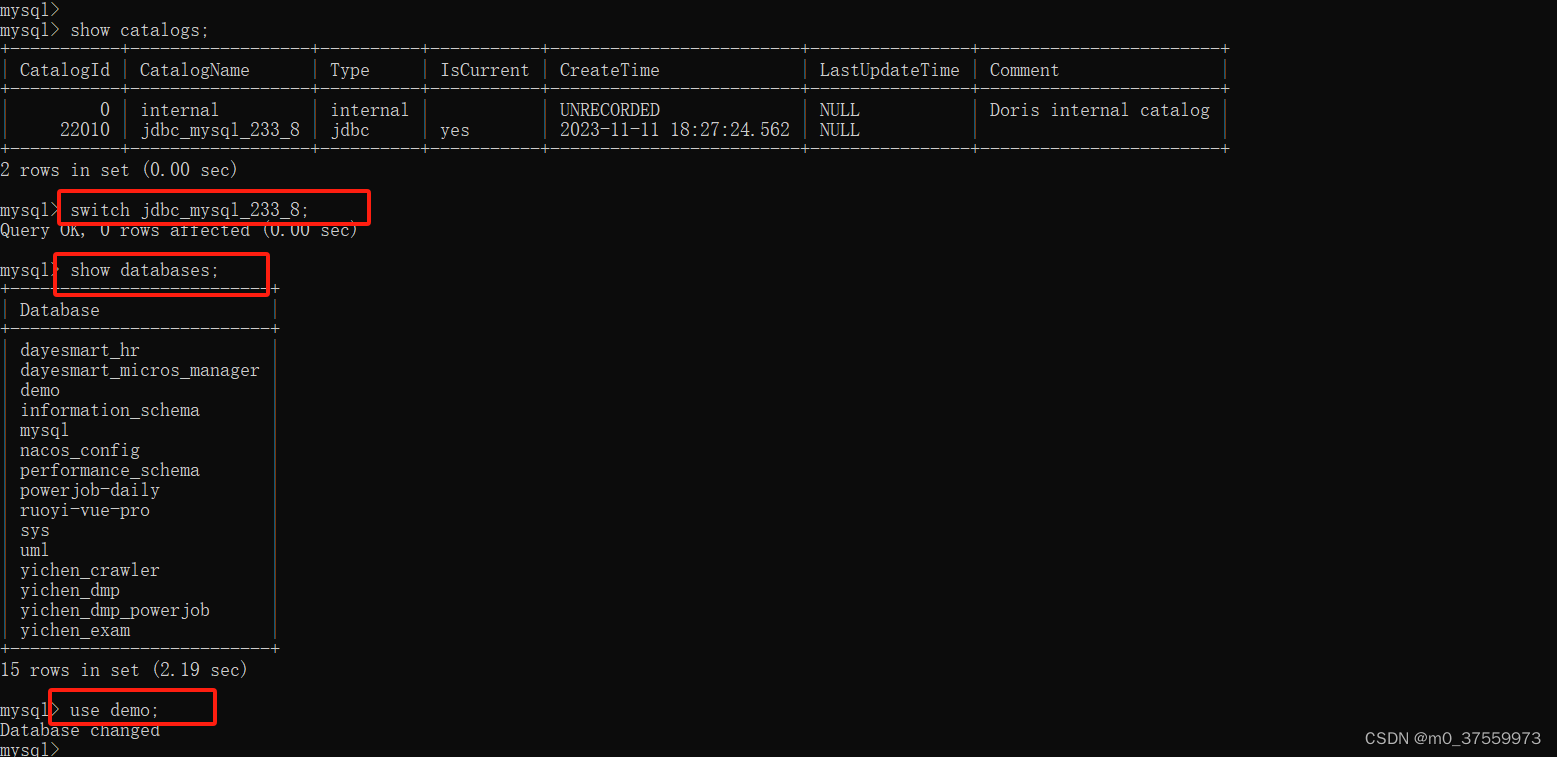
切换后,可以直接通过 SHOW DATABASES,USE DB 等命令查看和切换对应 Catalog 中的 Database。Doris 会自动通过 Catalog 中的 Database 和 Table。用户可以像使用 Internal Catalog 一样,对 External Catalog 中的数据进行查看和访问。
当前,Doris 只支持对 External Catalog 中的数据进行只读访问。
2.4 删除 Catalog
drop catalog catalog_name

3.元数据更新
默认情况下,外部数据源的元数据变动,如创建、删除表,加减列等操作,不会同步给 Doris。
用户可以通过以下几种方式刷新元数据。
3.1手动刷新
用户需要通过 REFRESH CATALOG catalog_name;命令手动刷新元数据。
3.2定时刷新
在创建catalog时,在properties 中指定刷新时间参数metadata_refresh_interval_sec ,以秒为单位,若在创建catalog时设置了该参数,FE 的master节点会根据参数值定时刷新该catalog。目前支持三种类型
- hms:Hive MetaStore
- es:Elasticsearch
- jdbc:数据库访问的标准接口(JDBC)
3.3自动刷新
自动刷新目前仅支持 Hive Catalog。该特性在 fe.conf 中有如下参数:
- enable_hms_events_incremental_sync: 是否开启元数据自动增量同步功能,默认关闭。
- hms_events_polling_interval_ms: 读取 event 的间隔时间,默认值为 10000,单位:毫秒。
- hms_events_batch_size_per_rpc: 每次读取 event 的最大数量,默认值为 500。
4.JDBC Catalog
JDBC Catalog 通过标准 JDBC 协议,连接其他数据源。连接后,Doris 会自动同步数据源下的 Database 和 Table 的元数据,以便快速访问这些外部数据。
4.1 上传mysql驱动包
需将 Jar 包预先存放在 FE 和 BE 部署目录的 jdbc_drivers/ 目录下。系统会自动在这个目录下寻找。该目录的位置,也可以由 fe.conf 和 be.conf 中的 jdbc_drivers_dir 配置修改。

修改fe和be配置文件,指定jdbc_drivers_dir目录。

4.2 创建mysql catalog
####mysql 8
CREATE CATALOG jdbc_mysql_233_8 PROPERTIES (
"type"="jdbc",
"user"="root",
"password"="123456",
"jdbc_url" = "jdbc:mysql://192.168.110.233:3307/demo",
"driver_url" = "mysql-connector-java-8.0.30.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver"
)####mysql 5
CREATE CATALOG jdbc_mysql_233_5 PROPERTIES (
"type"="jdbc",
"user"="root",
"password"="123456",
"jdbc_url" = "jdbc:mysql://192.168.110.233:3306/demo",
"driver_url" = "mysql-connector-java-5.1.47.jar",
"driver_class" = "com.mysql.jdbc.Driver"
)

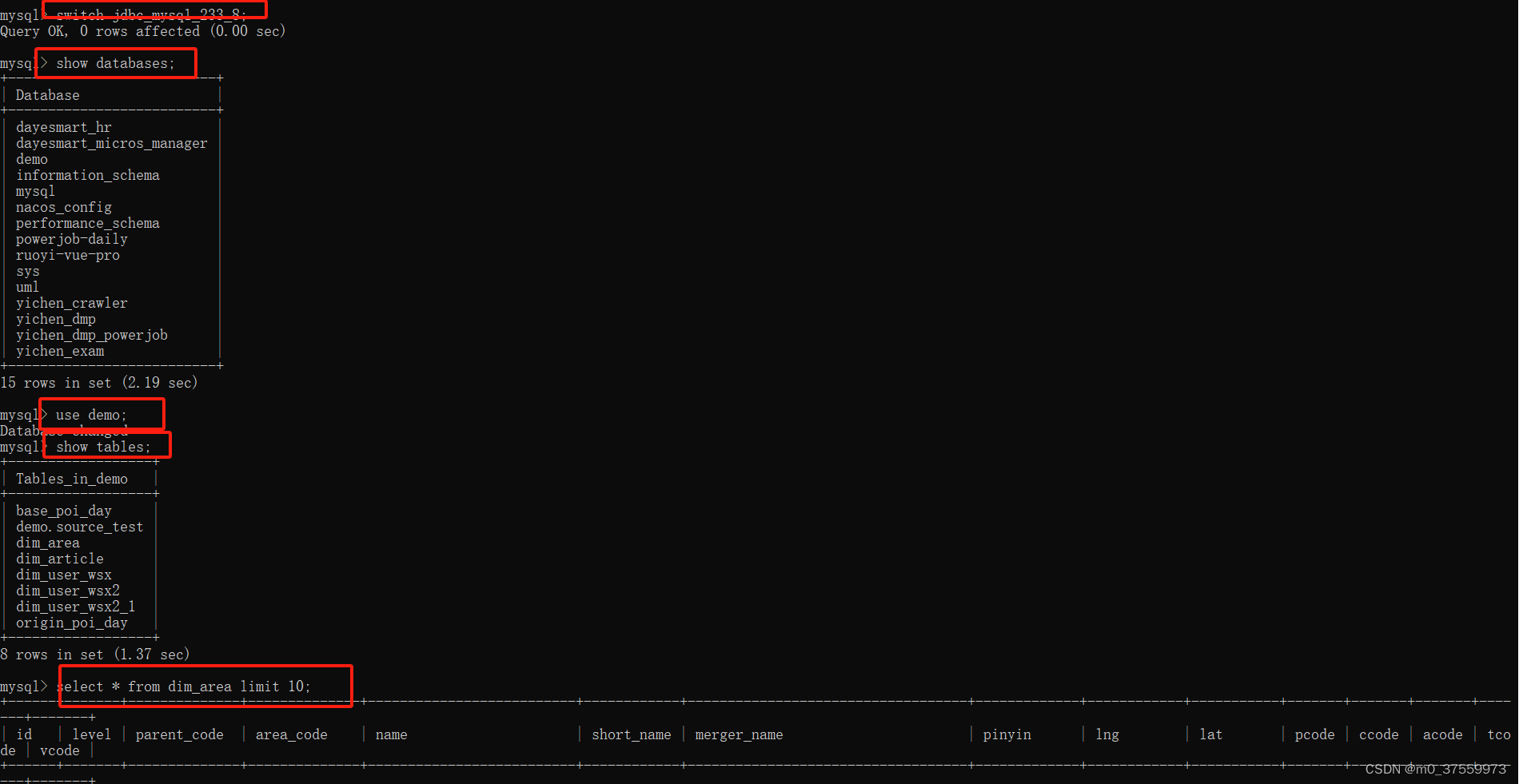
4.3. 读取mysql数据
show databases;
use db_name;
show tables;
select * from table_name limit 10;
这篇关于Doris:多源数据目录(Multi-Catalog)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






