本文主要是介绍pytorch中对nn.BatchNorm2d()函数的理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pytorch中对BatchNorm2d函数的理解
- 简介
- 计算
- 3. Pytorch的nn.BatchNorm2d()函数
- 4 代码示例
简介
机器学习中,进行模型训练之前,需对数据做归一化处理,使其分布一致。在深度神经网络训练过程中,通常一次训练是一个batch,而非全体数据。每个batch具有不同的分布产生了internal covarivate shift问题——在训练过程中,数据分布会发生变化,对下一层网络的学习带来困难。Batch Normalization强行将数据拉回到均值为0,方差为1的正太分布上,一方面使得数据分布一致,另一方面避免梯度消失。
计算
如图所示:
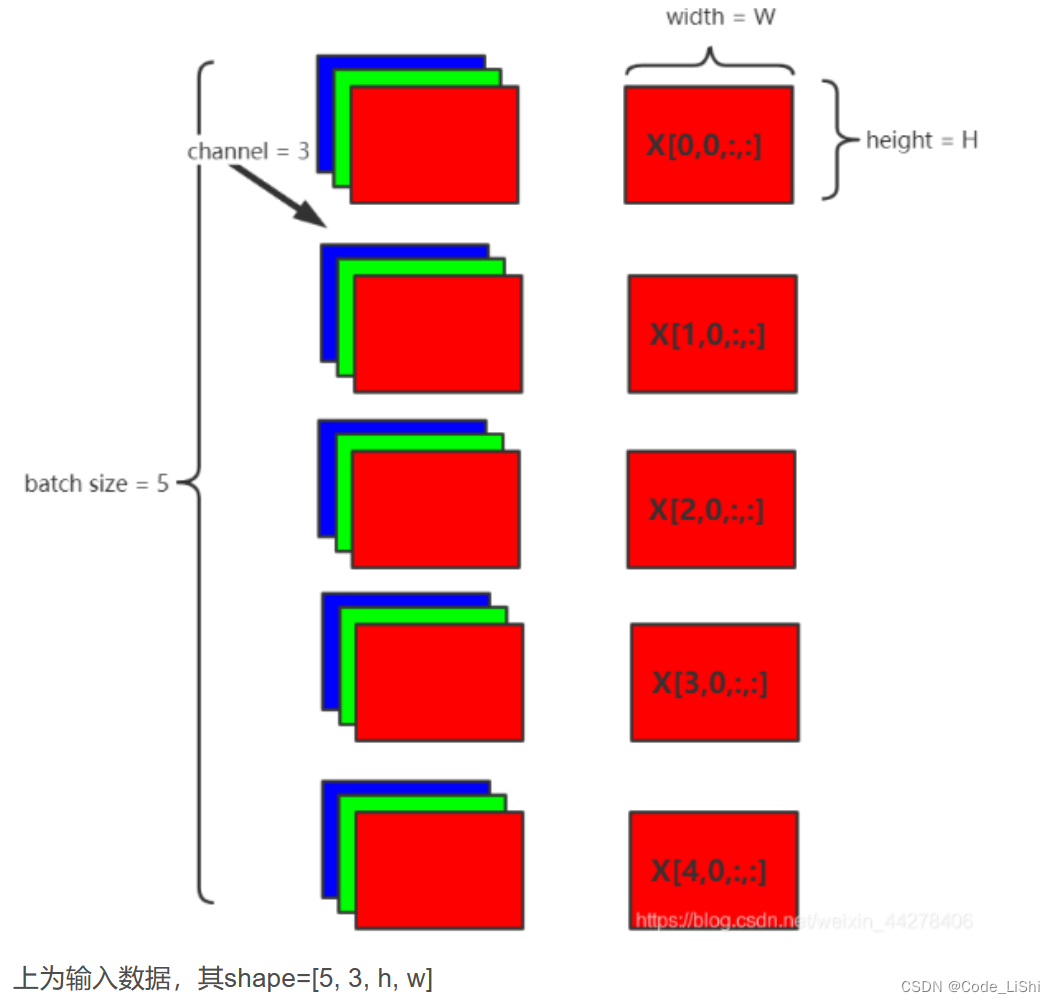

3. Pytorch的nn.BatchNorm2d()函数
其主要需要输入4个参数:
(1)num_features:输入数据的shape一般为[batch_size, channel, height, width], num_features为其中的channel;
(2)eps: 分母中添加的一个值,目的是为了计算的稳定性,默认:1e-5;
(3)momentum: 一个用于运行过程中均值和方差的一个估计参数,默认值为0.1.

(4)affine:当设为true时,给定可以学习的系数矩阵 γ \gamma γ和 β \beta β
4 代码示例
import torchdata = torch.ones(size=(2, 2, 3, 4))
data[0][0][0][0] = 25
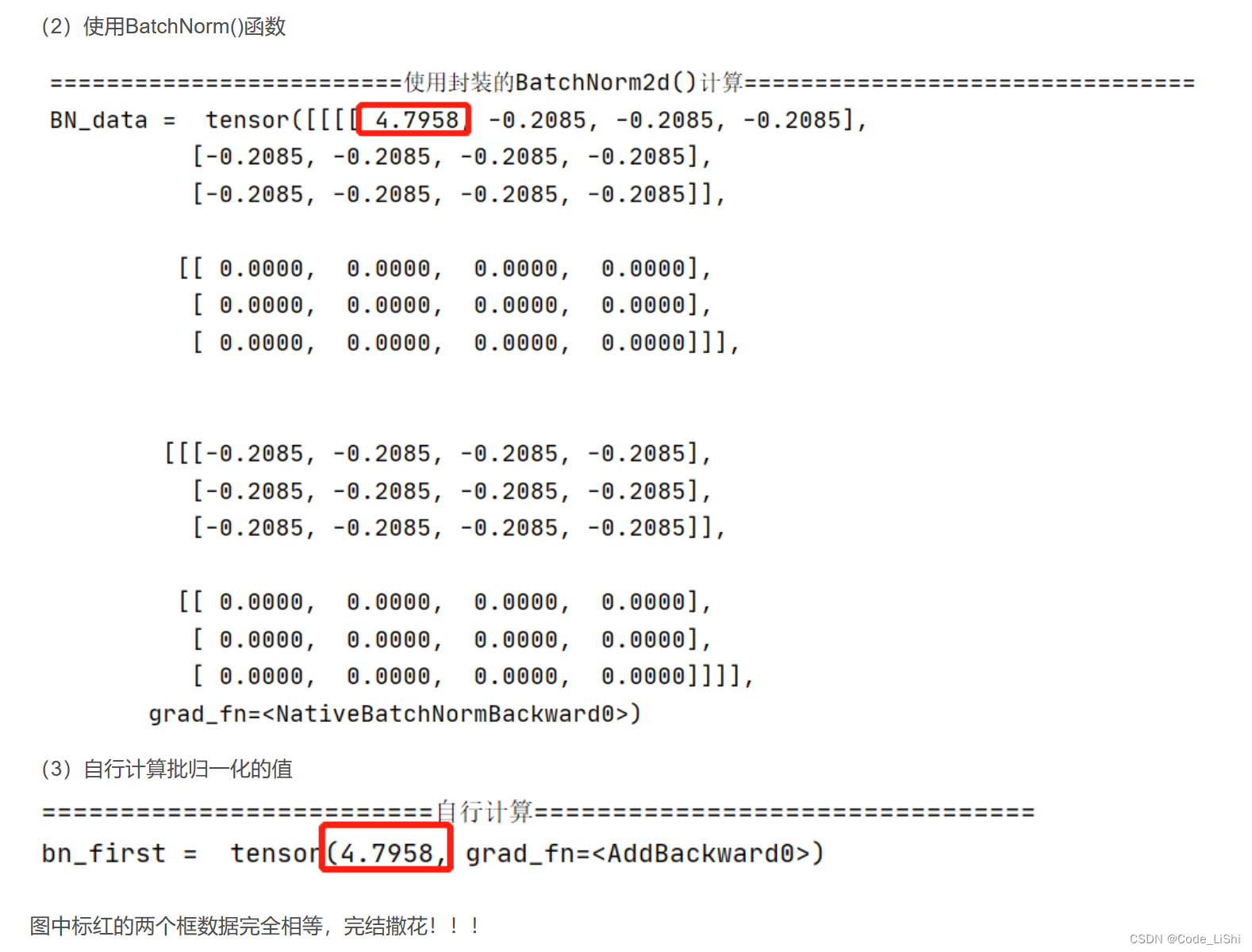
print("data = ", data)print("\n")print("=========================使用封装的BatchNorm2d()计算================================")
BN = torch.nn.BatchNorm2d(num_features=2, eps=0, momentum=0)
BN_data = BN(data)
print("BN_data = ", BN_data)print("\n")print("=========================自行计算================================")
x = torch.cat((data[0][0], data[1][0]), dim=1) # 1.将同一通道进行拼接(即把同一通道当作一个整体)
x_mean = torch.Tensor.mean(x) # 2.计算同一通道所有制的均值(即拼接后的均值)
x_var = torch.Tensor.var(x, False) # 3.计算同一通道所有制的方差(即拼接后的方差)# 4.使用第一个数按照公式来求BatchNorm后的值
bn_first = ((data[0][0][0][0] - x_mean) / ( torch.pow(x_var, 0.5))) * BN.weight[0] + BN.bias[0]
print("bn_first = ", bn_first)
这篇关于pytorch中对nn.BatchNorm2d()函数的理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





