本文主要是介绍Elasticsearch:在 ES|QL 中使用 DISSECT 和 GROK 进行数据处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
DISSECT 还是 GROK? 或者两者兼而有之?
使用 DISSECT 处理数据
Dissect pattern
术语
例子
DISSECT 关键修饰符
右填充修饰符 (->)
附加修饰符 (+)
添加顺序修饰符(+ 和 /n)
命名的跳过键(?)
参考键(* 和 &)
使用 GROK 处理数据
Grok pattern
正则表达式
例子
Grok 调试器
局限性
你的数据可能包含你想要结构化的非结构化字符串。 这使得分析数据变得更加容易。 例如,日志消息可能包含你想要提取的 IP 地址,以便你可以找到最活跃的 IP 地址。
对于使用过 Logstash 及 Ingest pipeline 的开发者来说,DISSECT 及 GROK 对你们来说并不陌生。你可以参阅如下的文章:
-
Elasticsearch:深入理解 Dissect ingest processor
-
Elasticsearch:Dissect 和 Grok 处理器之间的区别
-
Logstash:使用 dissect 导入 CSV 格式文档
-
Logstash:日志解析的 Grok 模式示例
Elasticsearch 可以在索引时或查询时构建数据。 在索引时,你可以使用 Dissect 和 Grok 摄取处理器,或 Logstash Dissect 和 Grok 过滤器。 在查询时,你可以使用 ES|QL DISSECT 和 GROK 命令。
DISSECT 还是 GROK? 或者两者兼而有之?
DISSECT 的工作原理是使用基于分隔符的模式分解字符串。 GROK 的工作原理类似,但使用正则表达式。 这使得 GROK 更强大,但通常也更慢。 当数据可靠地重复时,DISSECT 效果很好。 当你确实需要正则表达式的强大功能时,例如当文本的结构因行而异时,GROK 是更好的选择。
你可以将 DISSECT 和 GROK 用于混合用例。 例如,当一行的一部分可靠地重复时,但整行则不然。 DISSECT 可以解构重复的行条部分。 GROK 可以使用正则表达式处理剩余的字段值。
使用 DISSECT 处理数据
DISSECT 处理命令将字符串与基于分隔符的模式进行匹配,并将指定的键提取为列。
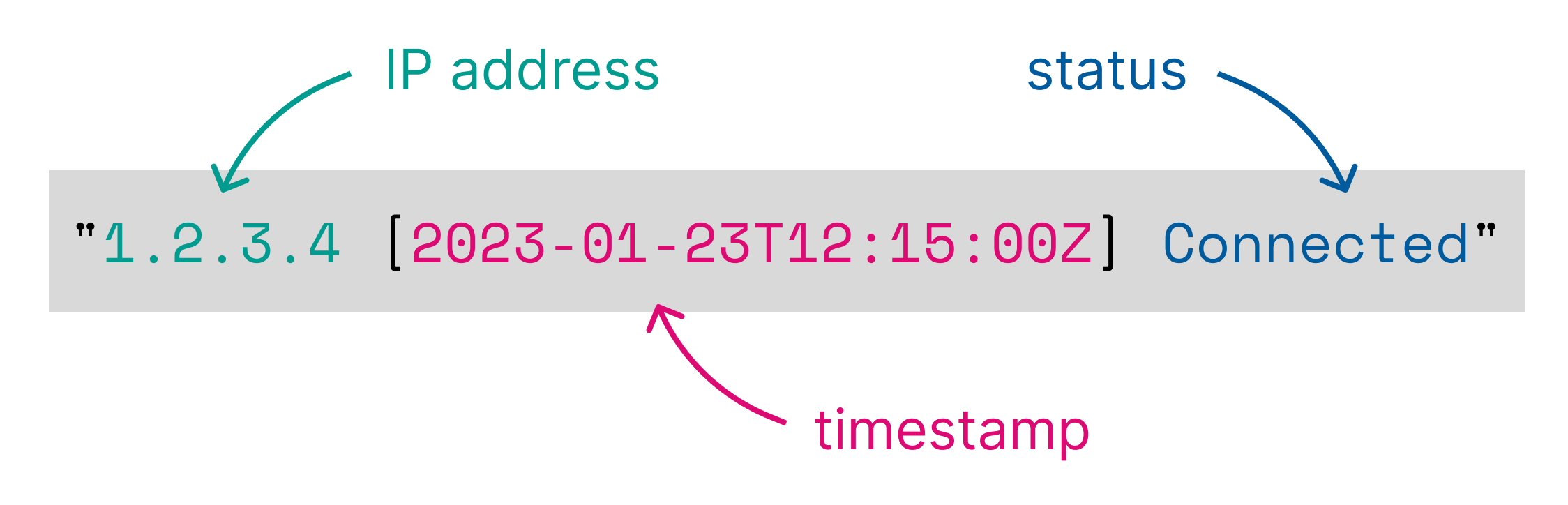
例如,以下模式:
%{clientip} [%{@timestamp}] %{status}匹配以下格式的日志行:
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected并将以下列添加到输入表中:
| clientip:keyword | @timestamp:keyword | status:keyword |
|---|---|---|
| 1.2.3.4 | 2023-01-23T12:15:00.000Z | Connected |
Dissect pattern
Dissect pattern 由将被丢弃的字符串部分定义。 在前面的示例中,要丢弃的第一个部分是单个空格。 Dissect 找到这个空间,然后为该空间之前的所有内容分配 clientip 的值。 接下来,dissect 匹配 [ 和 ],然后将 @timestamp 分配给 [ 和 ] 之间的所有内容。 特别注意要丢弃的字符串部分将有助于构建成功的 dissect patterns。
空键 %{} 或
命名的跳过键可用于匹配值,但从输出中排除该值。
所有匹配的值都作为关键字字符串数据类型输出。 使用类型转换函数转换为另一种数据类型。
Dissect 还支持可以更改 dissect 默认行为的键修饰符 (key modifier)。 例如,你可以指示 dissect 忽略某些字段、追加字段、跳过填充等。
术语
| 名称 | 描述 |
|---|---|
| dissect pattern | 描述文本格式的字段和分隔符集。 也称为 dissection。 使用一组 %{} 部分来描述 dissection:%{a} - %{b} - %{c} |
| 字段 | 从 %{ 到 }(含)的文本。 |
| 分隔符 | } 和接下来的 %{ 字符之间的文本。 除 %{、'not }' 或 } 之外的任何字符集都是分隔符。 |
| key | %{ 和 } 之间的文本,不包括 ?、+、& 前缀和序数后缀。 例子:
|
例子
以下示例解析包含时间戳、一些文本和 IP 地址的字符串:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a "%{date} - %{msg} - %{ip}"
| KEEP date, msg, ip| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
| 2023-01-23T12:15:00.000Z | some text | 127.0.0.1 |
默认情况下,DISSECT 输出 keyword 字符串列。 要转换为其他类型,请使用类型转换函数:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a "%{date} - %{msg} - %{ip}"
| KEEP date, msg, ip
| EVAL date = TO_DATETIME(date)| msg:keyword | ip:keyword | date:date |
|---|---|---|
| some text | 127.0.0.1 | 2023-01-23T12:15:00.000Z |
DISSECT 关键修饰符
键修饰符可以更改 dissect 的默认行为。 键修饰符可能位于 %{keyname} 的左侧或右侧,且始终位于 %{ 和 } 内。 例如 %{+keyname ->} 具有追加和右填充修饰符。
| Modifier | Name | Position | Example | Description | Details |
|---|---|---|---|---|---|
|
| Skip right padding | (far) right |
| 向右跳过所有重复的字符 | link |
|
| Append | left |
| 将两个或多个字段附加在一起 | link |
|
| Append with order | left and right |
| 按指定的顺序将两个或多个字段附加在一起 | link |
|
| Named skip key | left |
| 跳过输出中的匹配值。 与 %{} 相同的行为 | link |
|
| Reference keys | left |
| 将输出键设置为 * 值和 & 输出值 | link |
右填充修饰符 (->)
执行解析的算法非常严格,因为它要求模式中的所有字符都与源字符串匹配。 例如,模式 %{fookey} %{barkey} (1 个空格)将匹配字符串 “foo bar”(1 个空格),但不会匹配字符串“foo. bar”(2 个空格),因为该模式只有 1 个空格,源字符串有 2 个空格。
正确的填充修饰符有助于解决这种情况。 将右侧填充修饰符添加到模式 %{fookey->} %{barkey},现在它将匹配“foo bar”(1 个空格)和 “foo bar”(2 个空格),甚至“foo bar”(10 个空格) )。
使用右侧填充修饰符以允许在 %{keyname->} 之后重复字符。
右填充修饰符可以与任何其他修饰符一起放置在任何键上。 它应该始终是最右边的修饰符。 例如:%{+keyname/1->} 和 %{->}
右填充修饰符示例:
| Pattern |
|
| Input | 1998-08-10T17:15:42,466 WARN |
| Result |
|
右侧填充修饰符可以与空键一起使用,以帮助跳过不需要的数据。 例如,相同的输入字符串,但用括号括起来,需要使用空的右填充键来实现相同的结果。
带有空键的右填充修饰符示例
| Pattern |
|
| Input | [1998-08-10T17:15:42,466] [WARN] |
| Result |
|
附加修饰符 (+)
Dissect 支持将两个或多个结果附加在一起以进行输出。 值从左到右附加。 可以指定附加分隔符。 在此示例中,append_separator 被定义为空格。
附加修饰符示例:
| Pattern |
|
| Input | john jacob jingleheimer schmidt |
| Result |
|
添加顺序修饰符(+ 和 /n)
Dissect 支持将两个或多个结果附加在一起以进行输出。 值根据定义的顺序 (/n) 附加。 可以指定附加分隔符。 在此示例中,append_separator 被定义为逗号。
附加顺序修饰符示例:
| Pattern |
|
| Input | john jacob jingleheimer schmidt |
| Result |
|
命名的跳过键(?)
Dissect 支持忽略最终结果中的匹配项。 这可以使用空键 %{} 来完成,但为了可读性,可能需要为该空键命名。
命名的跳过键修饰符示例:
| Pattern |
|
| Input | 1.2.3.4 - - [30/Apr/1998:22:00:52 +0000] |
| Result |
|
参考键(* 和 &)
Dissect 支持使用解析值作为结构化内容的 key/value。 想象一个部分记录 key/value 对的系统。 引用键允许你维护该键/值关系。
参考键修饰符示例:
| Pattern |
|
| Input | [2018-08-10T17:15:42,466] [ERR] ip:1.2.3.4 error:REFUSED |
| Result |
|
使用 GROK 处理数据
GROK 处理命令将字符串与基于正则表达式的模式进行匹配,并将指定的键提取为列。
例如,以下模式:
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}匹配以下格式的日志行:
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected并将以下列添加到输入表中:
| @timestamp:keyword | ip:keyword | status:keyword |
|---|---|---|
| 2023-01-23T12:15:00.000Z | 1.2.3.4 | Connected |
Grok pattern
Grok 模式的语法是 %{SYNTAX:SEMANTIC}
SYNTAX 是与你的文本匹配的模式的名称。 例如,3.44 通过 NUMBER 模式匹配,55.3.244.1 通过 IP 模式匹配。 语法就是你如何匹配。
语义是你为匹配的文本片段提供的标识符。 例如,3.44 可能是事件的持续时间,因此你可以将其简称为 duration。 此外,字符串 55.3.244.1 可以标识发出请求的 client。
默认情况下,匹配的值作为关键字字符串数据类型输出。 要转换语义的数据类型,请在其后面加上目标数据类型的后缀。 例如 %{NUMBER:num:int},它将 num 语义从字符串转换为整数。 目前唯一支持的转换是 int 和 float。 对于其他类型,请使用类型转换函数。
有关可用模式的概述,请参阅 GitHub。 你还可以使用 REST API 检索所有模式的列表。
正则表达式
Grok 基于正则表达式。 任何正则表达式在 grok 中也有效。 Grok 使用 Oniguruma 正则表达式库。 有关完整支持的正则表达式语法,请参阅 Oniguruma GitHub 存储库。
注意:特殊的正则表达式字符如 [ 和 ] 需要用 \ 转义。 例如,在之前的模式中:
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}在 ES|QL 查询中,反斜杠字符本身是一个特殊字符,需要用另一个 \ 进行转义。 对于此示例,相应的 ES|QL 查询变为:
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected" | GROK a "%{IP:ip} \\[%{TIMESTAMP_ISO8601:@timestamp}\\] %{GREEDYDATA:status}"
定制 patterns
如果 grok 没有你需要的模式,你可以使用 Oniguruma 语法进行命名捕获,它可以让你匹配一段文本并将其保存为一列:
(?<field_name>the pattern here)例如,postfix 日志的 queue id 是 10 或 11 个字符的十六进制值。 可以使用以下命令将其捕获到名为 queue_id 的列中:
(?<queue_id>[0-9A-F]{10,11})例子
以下示例解析包含时间戳、IP 地址、电子邮件地址和数字的字符串:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}"
| KEEP date, ip, email, num| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
| 2023-01-23T12:15:00.000Z | 127.0.0.1 | some.email@foo.com | 42 |
默认情况下,GROK 输出关键字字符串列。 int 和 float 类型可以通过将 :type 附加到模式中的语义来转换。 例如 {NUMBER:num:int}:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
| 2023-01-23T12:15:00.000Z | 127.0.0.1 | some.email@foo.com | 42 |
对于其他类型转换,请使用类型转换函数:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num
| EVAL date = TO_DATETIME(date)| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
| 127.0.0.1 | some.email@foo.com | 42 | 2023-01-23T12:15:00.000Z |
Grok 调试器
要编写和调试 grok 模式,你可以使用 Grok 调试器。 它提供了一个用于根据示例数据测试模式的 UI。 在幕后,它使用与 GROK 命令相同的引擎。
局限性
GROK 命令不支持配置自定义模式或多个模式。 GROK 命令不受 Grok 看门狗设置的约束。
这篇关于Elasticsearch:在 ES|QL 中使用 DISSECT 和 GROK 进行数据处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





