本文主要是介绍9月5日关键点检测学习笔记——人体骨骼点检测:自底向上,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、堆叠沙漏网络 Stacked Hourglass Networks
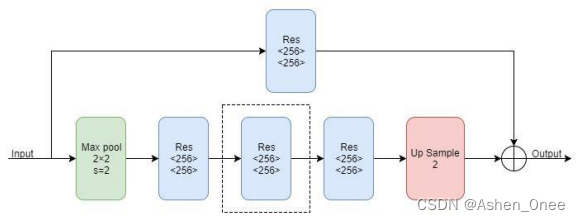
- 1、Hourglass Module
- 2、Heat map
- 二、自顶向下的问题
- 三、自底向上
- 1、OpenPose
- 四、OpenPose 实战
前言
本文为9月5日关键点检测学习笔记——人体骨骼点检测:自底向上,分为四个章节:
- 堆叠沙漏网络 Stacked Hourglass Networks;
- 自顶向下的问题;
- 自底向上;
- OpenPose 实战。
一、堆叠沙漏网络 Stacked Hourglass Networks
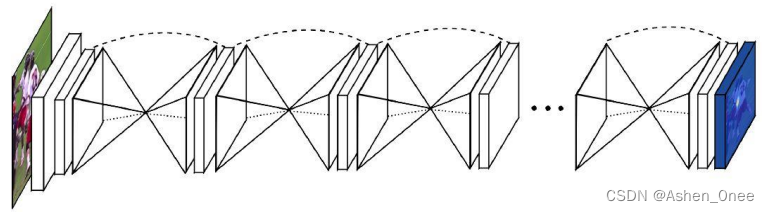
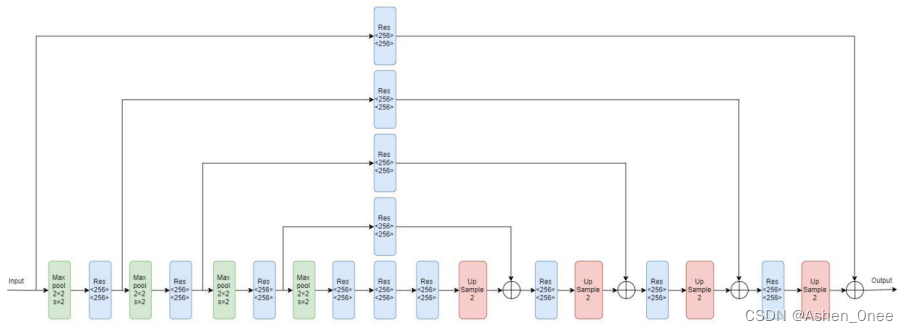
1、Hourglass Module
2、Heat map

二、自顶向下的问题
- 速度慢;
- Temporal occlusion 目标遮挡。
三、自底向上
1、OpenPose

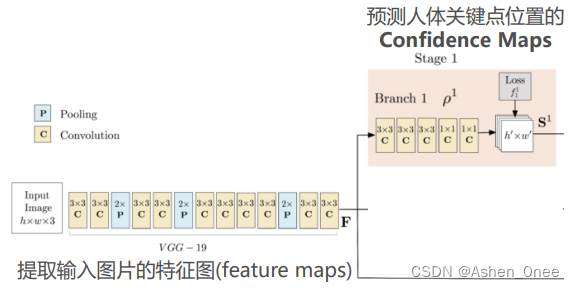
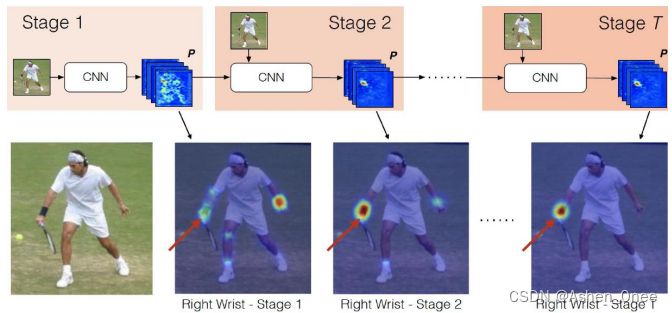
每个 confidence map 是一个灰度图,其最大值的位置坐标即为对应人体某个概率最高的关键点。

另一个分支预测 part affinities 的 2D 向量场,表示两个关键点间的关联度。
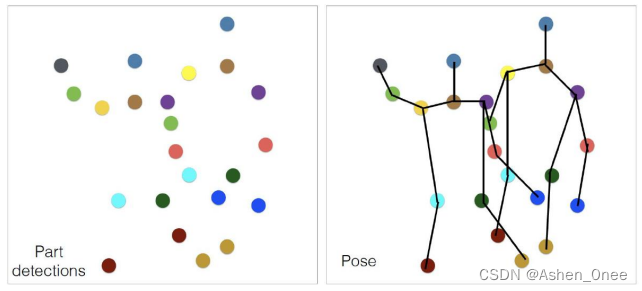
- Parts detection:
- Parts association:

L c , k ∗ ( p ) = { v i f p o n l i m b c , k 0 o t h e r w i s e v = ( x j 2 , k − x j 1 , k ) ∣ ∣ x j 2 , k − x j 1 , k ∣ ∣ 2 0 ≤ v ⋅ ( p − x j i , k ) ≤ l c , k a n d ∣ v ⊥ ⋅ ( p − x j i , k ) ∣ ≤ σ l \textbf{L}^*_{c, k}(p) = \left\{\begin{matrix} \textbf{v} \quad if\ \textbf{p}\ on\ limb\ c, k \\ \textbf{0} \quad otherwise \end{matrix}\right. \\ \textbf{v} = \frac{(\textbf{x}_{j_2, k} - \textbf{x}_{j_1, k})}{||\textbf{x}_{j_2, k} - \textbf{x}_{j_1, k}||_2}\\ 0 \le \textbf{v}\cdot (\textbf{p} - \textbf{x}_{j_i, k} ) \le l_{c, k} \quad and \quad |\textbf{v}_\perp \cdot (\textbf{p} - \textbf{x}_{j_i, k}) | \le \sigma _l Lc,k∗(p)={vif p on limb c,k0otherwisev=∣∣xj2,k−xj1,k∣∣2(xj2,k−xj1,k)0≤v⋅(p−xji,k)≤lc,kand∣v⊥⋅(p−xji,k)∣≤σl
其中,四肢宽度 limb width σ l \sigma_l σl 为像素宽度,四肢长度: l c , k = ∣ ∣ x j 2 , k − x j 1 , k ∣ ∣ 2 l_{c, k} = ||\textbf{x}_{j_2, k} - \textbf{x}_{j_1, k}||_2 lc,k=∣∣xj2,k−xj1,k∣∣2; v ⊥ \textbf{v}_{\perp} v⊥ 是 v \textbf{v} v 的垂直向量。
四、OpenPose 实战
train_VGG19.py 代码如下:
import argparse
import time
import os
import numpy as np
from collections import OrderedDictimport torch
import torch.nn as nn
from torch.optim.lr_scheduler import ReduceLROnPlateaufrom lib.network.rtpose_vgg import get_model, use_vgg
from lib.datasets import coco, transforms, datasets
from lib.config import update_configDATA_DIR = '/data/coco'ANNOTATIONS_TRAIN = [os.path.join(DATA_DIR, 'annotations', item) for item in ['person_keypoints_train2017.json']]
ANNOTATIONS_VAL = os.path.join(DATA_DIR, 'annotations', 'person_keypoints_val2017.json')
IMAGE_DIR_TRAIN = os.path.join(DATA_DIR, 'images/train2017')
IMAGE_DIR_VAL = os.path.join(DATA_DIR, 'images/val2017')def train_cli(parser):group = parser.add_argument_group('dataset and loader')group.add_argument('--train-annotations', default=ANNOTATIONS_TRAIN)group.add_argument('--train-image-dir', default=IMAGE_DIR_TRAIN)group.add_argument('--val-annotations', default=ANNOTATIONS_VAL)group.add_argument('--val-image-dir', default=IMAGE_DIR_VAL)group.add_argument('--pre-n-images', default=8000, type=int,help='number of images to sampe for pretraining')group.add_argument('--n-images', default=None, type=int,help='number of images to sample')group.add_argument('--duplicate-data', default=None, type=int,help='duplicate data')group.add_argument('--loader-workers', default=8, type=int,help='number of workers for data loading')group.add_argument('--batch-size', default=72, type=int,help='batch size')group.add_argument('--lr', '--learning-rate', default=1., type=float,metavar='LR', help='initial learning rate')group.add_argument('--momentum', default=0.9, type=float, metavar='M',help='momentum')group.add_argument('--weight-decay', '--wd', default=0.000, type=float,metavar='W', help='weight decay (default: 1e-4)') group.add_argument('--nesterov', dest='nesterov', default=True, type=bool) group.add_argument('--print_freq', default=20, type=int, metavar='N',help='number of iterations to print the training statistics') def train_factory(args, preprocess, target_transforms):train_datas = [datasets.CocoKeypoints(root=args.train_image_dir,annFile=item,preprocess=preprocess,image_transform=transforms.image_transform_train,target_transforms=target_transforms,n_images=args.n_images,) for item in args.train_annotations]train_data = torch.utils.data.ConcatDataset(train_datas)train_loader = torch.utils.data.DataLoader(train_data, batch_size=args.batch_size, shuffle=True,pin_memory=args.pin_memory, num_workers=args.loader_workers, drop_last=True)val_data = datasets.CocoKeypoints(root=args.val_image_dir,annFile=args.val_annotations,preprocess=preprocess,image_transform=transforms.image_transform_train,target_transforms=target_transforms,n_images=args.n_images,)val_loader = torch.utils.data.DataLoader(val_data, batch_size=args.batch_size, shuffle=False,pin_memory=args.pin_memory, num_workers=args.loader_workers, drop_last=True)return train_loader, val_loader, train_data, val_datadef cli():parser = argparse.ArgumentParser(description=__doc__,formatter_class=argparse.ArgumentDefaultsHelpFormatter,)train_cli(parser)parser.add_argument('-o', '--output', default=None,help='output file')parser.add_argument('--stride-apply', default=1, type=int,help='apply and reset gradients every n batches')parser.add_argument('--epochs', default=75, type=int,help='number of epochs to train')parser.add_argument('--freeze-base', default=0, type=int,help='number of epochs to train with frozen base')parser.add_argument('--pre-lr', type=float, default=1e-4,help='pre learning rate')parser.add_argument('--update-batchnorm-runningstatistics',default=False, action='store_true',help='update batch norm running statistics')parser.add_argument('--square-edge', default=368, type=int,help='square edge of input images')parser.add_argument('--ema', default=1e-3, type=float,help='ema decay constant')parser.add_argument('--debug-without-plots', default=False, action='store_true',help='enable debug but dont plot')parser.add_argument('--disable-cuda', action='store_true',help='disable CUDA') parser.add_argument('--model_path', default='./network/weight/', type=str, metavar='DIR',help='path to where the model saved') args = parser.parse_args()# add args.deviceargs.device = torch.device('cpu')args.pin_memory = Falseif not args.disable_cuda and torch.cuda.is_available():args.device = torch.device('cuda')args.pin_memory = Truereturn argsargs = cli()print("Loading dataset...")
# load train data
preprocess = transforms.Compose([transforms.Normalize(),transforms.RandomApply(transforms.HFlip(), 0.5),transforms.RescaleRelative(),transforms.Crop(args.square_edge),transforms.CenterPad(args.square_edge),])
train_loader, val_loader, train_data, val_data = train_factory(args, preprocess, target_transforms=None)def build_names():names = []for j in range(1, 7):for k in range(1, 3):names.append('loss_stage%d_L%d' % (j, k))return namesdef get_loss(saved_for_loss, heat_temp, vec_temp):names = build_names()saved_for_log = OrderedDict()criterion = nn.MSELoss(reduction='mean').cuda()total_loss = 0for j in range(6):pred1 = saved_for_loss[2 * j]pred2 = saved_for_loss[2 * j + 1] # Compute lossesloss1 = criterion(pred1, vec_temp)loss2 = criterion(pred2, heat_temp) total_loss += loss1total_loss += loss2# print(total_loss)# Get value from Variable and save for logsaved_for_log[names[2 * j]] = loss1.item()saved_for_log[names[2 * j + 1]] = loss2.item()saved_for_log['max_ht'] = torch.max(saved_for_loss[-1].data[:, 0:-1, :, :]).item()saved_for_log['min_ht'] = torch.min(saved_for_loss[-1].data[:, 0:-1, :, :]).item()saved_for_log['max_paf'] = torch.max(saved_for_loss[-2].data).item()saved_for_log['min_paf'] = torch.min(saved_for_loss[-2].data).item()return total_loss, saved_for_logdef train(train_loader, model, optimizer, epoch):batch_time = AverageMeter()data_time = AverageMeter()losses = AverageMeter()meter_dict = {}for name in build_names():meter_dict[name] = AverageMeter()meter_dict['max_ht'] = AverageMeter()meter_dict['min_ht'] = AverageMeter() meter_dict['max_paf'] = AverageMeter() meter_dict['min_paf'] = AverageMeter()# switch to train modemodel.train()end = time.time()for i, (img, heatmap_target, paf_target) in enumerate(train_loader):# measure data loading time#writer.add_text('Text', 'text logged at step:' + str(i), i)#for name, param in model.named_parameters():# writer.add_histogram(name, param.clone().cpu().data.numpy(),i) data_time.update(time.time() - end)img = img.cuda()heatmap_target = heatmap_target.cuda()paf_target = paf_target.cuda()# compute output_,saved_for_loss = model(img)total_loss, saved_for_log = get_loss(saved_for_loss, heatmap_target, paf_target)for name,_ in meter_dict.items():meter_dict[name].update(saved_for_log[name], img.size(0))losses.update(total_loss, img.size(0))# compute gradient and do SGD stepoptimizer.zero_grad()total_loss.backward()optimizer.step()# measure elapsed timebatch_time.update(time.time() - end)end = time.time()if i % args.print_freq == 0:print_string = 'Epoch: [{0}][{1}/{2}]\t'.format(epoch, i, len(train_loader))print_string +='Data time {data_time.val:.3f} ({data_time.avg:.3f})\t'.format( data_time=data_time)print_string += 'Loss {loss.val:.4f} ({loss.avg:.4f})'.format(loss=losses)for name, value in meter_dict.items():print_string+='{name}: {loss.val:.4f} ({loss.avg:.4f})\t'.format(name=name, loss=value)print(print_string)return losses.avg def validate(val_loader, model, epoch):batch_time = AverageMeter()data_time = AverageMeter()losses = AverageMeter()meter_dict = {}for name in build_names():meter_dict[name] = AverageMeter()meter_dict['max_ht'] = AverageMeter()meter_dict['min_ht'] = AverageMeter() meter_dict['max_paf'] = AverageMeter() meter_dict['min_paf'] = AverageMeter()# switch to train modemodel.eval()end = time.time()for i, (img, heatmap_target, paf_target) in enumerate(val_loader):# measure data loading timedata_time.update(time.time() - end)img = img.cuda()heatmap_target = heatmap_target.cuda()paf_target = paf_target.cuda()# compute output_,saved_for_loss = model(img)total_loss, saved_for_log = get_loss(saved_for_loss, heatmap_target, paf_target)#for name,_ in meter_dict.items():# meter_dict[name].update(saved_for_log[name], img.size(0))losses.update(total_loss.item(), img.size(0))# measure elapsed timebatch_time.update(time.time() - end)end = time.time() if i % args.print_freq == 0:print_string = 'Epoch: [{0}][{1}/{2}]\t'.format(epoch, i, len(val_loader))print_string +='Data time {data_time.val:.3f} ({data_time.avg:.3f})\t'.format( data_time=data_time)print_string += 'Loss {loss.val:.4f} ({loss.avg:.4f})'.format(loss=losses)for name, value in meter_dict.items():print_string+='{name}: {loss.val:.4f} ({loss.avg:.4f})\t'.format(name=name, loss=value)print(print_string)return losses.avgclass AverageMeter(object):"""Computes and stores the average and current value"""def __init__(self):self.reset()def reset(self):self.val = 0self.avg = 0self.sum = 0self.count = 0def update(self, val, n=1):self.val = valself.sum += val * nself.count += nself.avg = self.sum / self.count# model
model = get_model(trunk='vgg19')
model = torch.nn.DataParallel(model).cuda()
# load pretrained
use_vgg(model)# Fix the VGG weights first, and then the weights will be released
for i in range(20):for param in model.module.model0[i].parameters():param.requires_grad = Falsetrainable_vars = [param for param in model.parameters() if param.requires_grad]
optimizer = torch.optim.SGD(trainable_vars, lr=args.lr,momentum=args.momentum,weight_decay=args.weight_decay,nesterov=args.nesterov) for epoch in range(5):# train for one epochtrain_loss = train(train_loader, model, optimizer, epoch)# evaluate on validation setval_loss = validate(val_loader, model, epoch) # Release all weights
for param in model.module.parameters():param.requires_grad = Truetrainable_vars = [param for param in model.parameters() if param.requires_grad]
optimizer = torch.optim.SGD(trainable_vars, lr=args.lr,momentum=args.momentum,weight_decay=args.weight_decay,nesterov=args.nesterov) lr_scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.8, patience=5, verbose=True, threshold=0.0001, threshold_mode='rel', cooldown=3, min_lr=0, eps=1e-08)best_val_loss = np.infmodel_save_filename = './network/weight/best_pose.pth'
for epoch in range(5, args.epochs):# train for one epochtrain_loss = train(train_loader, model, optimizer, epoch)# evaluate on validation setval_loss = validate(val_loader, model, epoch) lr_scheduler.step(val_loss) is_best = val_loss<best_val_lossbest_val_loss = min(val_loss, best_val_loss)if is_best:torch.save(model.state_dict(), model_save_filename)
这篇关于9月5日关键点检测学习笔记——人体骨骼点检测:自底向上的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







