本文主要是介绍Python3爬虫(3)--爬取电子科大学生成绩,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要是写一个爬取学生成绩的一个小爬虫,我们在这中间要使用cookie的相关内容,登录到UESTC信息门户网站。
在登陆到信息门户网站的时候我们可以通过火狐浏览器的httpfox插件查看postdata得到我们所要post的数据内容
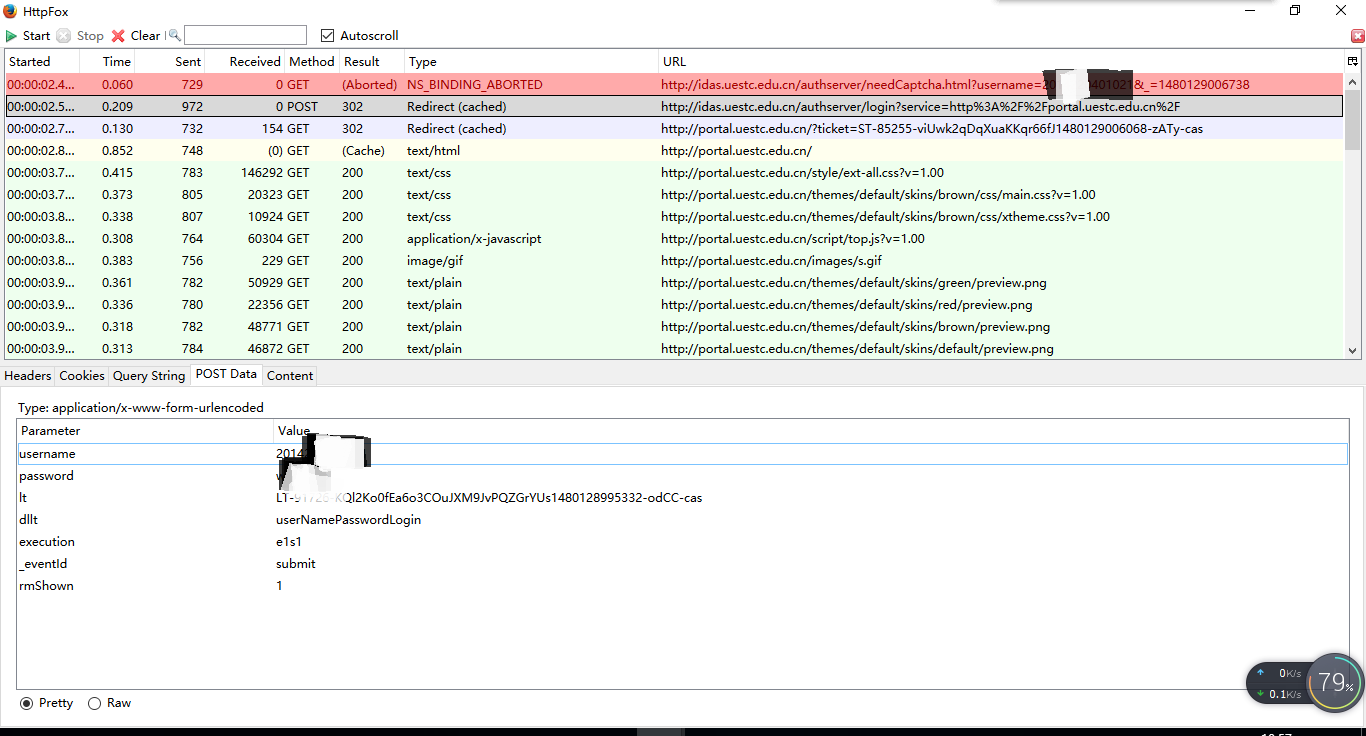
但是当我们将这些内容post到目标网站时,发现并不能得到需要返回的页面,原因在于It是一个随时间变动所生成的一个字符串,我们需要先获取这个字符串,只需要将此段字符串切片出来即可
def clt(self, url):response = urllib.request.urlopen(url)data = response.read()soup = BeautifulSoup(data, 'html.parser', from_encoding='utf-8')##print(data.decode())link = soup.find_all('input')aa = link[2]aa=str(aa)return aa[38:-3]得到了It之后,我们就可以将我们所要提交的数据提交给目标网址就可以了
def post(self):cj = http.cookiejar.CookieJar()pro = urllib.request.HTTPCookieProcessor(cj)opener = urllib.request.build_opener(pro)urllib.request.install_opener(opener)user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36r)'header = {'User-Agent': user_agent}username=input('请输入你信息门户的账号:')password=input('请输入你信息门户的密码:')postdata = urllib.parse.urlencode({'username': username,'password': password,'lt': self.clt('http://idas.uestc.edu.cn/authserver/login'),'dllt': 'userNamePasswordLogin','execution': 'e1s1','_eventId': 'submit','rmShown': '1'})postdata = postdata.encode('utf-8')url = 'http://idas.uestc.edu.cn/authserver/login?service=http%3A%2F%2Fportal.uestc.edu.cn%2F'req = urllib.request.Request(url, postdata, headers=header)result=opener.open(req)然后我们直接就可以得到成绩页的相关信息了,在成绩页面的处理中,自我感觉处理的很不好,但是已经验证了POST数据到信息门户,并且得到了想要的相关数据内容,所以并没有修改,大家在自己做的时候好的风格记得滴滴我一下哦
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
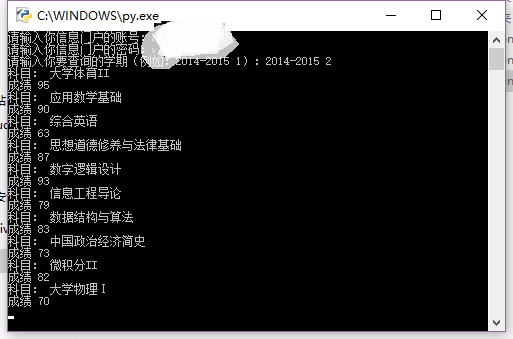
import reclass Source(object):def __init__(self):self.data={}def clsource(self):req=urllib.request.urlopen(self.choice())return req.read().decode()def output(self):data=self.clsource()soup = BeautifulSoup(data, 'html.parser')links=soup.find_all('td')datas = []a = 3while a < len(links):datas.append(links[a].get_text().strip())a = a + 5i = 0while i < len(datas):print('科目:', datas[i])i = i + 1print('成绩', datas[i])i = i + 1def choice(self):url=''datetime=input('请输入你要查询的学期(例如:2014-2015 1):')if datetime=='2014-2015 1':url='http://eams.uestc.edu.cn/eams/teach/grade/course/person!search.action?semesterId=43&projectType='elif datetime=='2014-2015 2':url='http://eams.uestc.edu.cn/eams/teach/grade/course/person!search.action?semesterId=63&projectType='elif datetime=='2015-2016 1':url='http://eams.uestc.edu.cn/eams/teach/grade/course/person!search.action?semesterId=84&projectType='elif datetime=='2015-2016 2':url='http://eams.uestc.edu.cn/eams/teach/grade/course/person!search.action?semesterId=103&projectType='elif datetime=='2016-2017 1':url='http://eams.uestc.edu.cn/eams/teach/grade/course/person!search.action?semesterId=123&projectType='else :print('对不起,没有当前学期的成绩!')return url运行我们的程序,可以看到我们想要的结果
github源代码地址UESTC
这篇关于Python3爬虫(3)--爬取电子科大学生成绩的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








