本文主要是介绍python爬取淘宝热卖商品(附xpath下载),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本文采用的主要工具是xpath,如果没有下载的可以点开此链接下载:https://pan.baidu.com/share/init?surl=GXPm1kMENXhOkefKcEQnlA
提取码:8wwv
xpath工具使用方法,即简单实战链接:https://blog.csdn.net/weixin_45859193/article/details/107064009
注意:本文xpath工具查找是有点难找的,我找了挺久(是我太菜了,嘿嘿…),所以如果不是很懂xpath的建议先看看我上面的简单实战链接去试试在过来看,这样可能会比较好懂点…(我也希望有大佬可以提点提点我改进代码,欢迎评论!)
爬虫离不开的四大步骤
1.目标url(这个是开头,也是很重要的一步)
2.发送请求
3.解析数据
4.保存数据
那么搞懂这些后就来开始实战吧!
开始
按照第一步来,应该是需要获取目标的url地址,所以我们点开淘宝热卖https://re.taobao.com,然后再里面随便搜索你喜欢的商品,然后把链接复制起来,放到代码里,因为我们是要指定爬取的所以代码要这样写:
url=input('请输入想查找的链接:')
#使用正则匹配,查看是不是我们要求的网页
url_link=re.findall("https://(.*?)/",url)
#这里是记个时,如果到5次就给他提示吧....
i=0
#死循环
while True:#判断是不是点进了淘宝热卖if url_link==['re.taobao.com']:breakelse:url = input('请重新输入淘宝热卖的链接:')url_link = re.findall("https://(.*?)/", url)i+=1#如果用户输入5次还是一样给出提示= =if i==5:print('提示:请进入https://re.taobao.com官网获取链接!')这是开始的大概思路,直接点的意思就是判断你点开的链接是不是淘宝热卖的,不是的话就会一直循环,循环…嘿嘿嘿…
然后是不是到了我们得第二步,发送请求了,因为我们获取了url地址,所以就要来个发送请求
#模拟浏览器
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'}
#发送请求
response=requests.get(url,headers=headers).content.decode()
是不是,你这时候是不是开始觉得爬虫其实也就这掌握了这4步奏,是不是很简单!
然后是不是继续到了我们的第三步的解析数据:
#解析成xpath格式
html=etree.HTML(response)
#价格
req_list=html.xpath('//span[@class="pricedetail"]//strong//text()')
#名字
name_list=html.xpath('//span[@class="title"]/@title')
#付款人数
host_list=html.xpath('//span[@class="payNum"]//text()')
#商家名字
host_1_list=html.xpath('//span[@class="shopNick"]//text()')
#评分,提示一下这里我找了挺久,因为id没加上多出了几个,淘宝也是坑
score_list=html.xpath('//div[@id="J_waterfallWrapper"]//span//b//text()')
#链接
link_list=html.xpath('//div[@id="J_waterfallWrapper"]//div[@class="item"]//a/@href')
#如实描述,创建几个空列表,获取这些评分,因为淘宝有坑,想爬准确只能3个3个爬,但是想打印出来,有点麻烦(我太菜了= =)
是不是围绕着这四步走是不是很顺利(其实不是的,我找评分,找了一个小时,因为有干扰数据,我太笨了有点晚才发现,呜呜呜…)
在这里我先来几张图片提醒一下大家,爬淘宝评分的坑
正常的我们去用xpath应该是这样吧
 每个数据3个,我着一页有200个数据,顶多600个,那15个怎么来的,起初我不想管他,回来发现,不能不管,因为有些数据会不一样,最后我往下翻,发现这五个商品,刚好也就是15个数据,不过这广告是想暗示我的头发吗…(突然一阵风从我头上吹过,很凉快…)
每个数据3个,我着一页有200个数据,顶多600个,那15个怎么来的,起初我不想管他,回来发现,不能不管,因为有些数据会不一样,最后我往下翻,发现这五个商品,刚好也就是15个数据,不过这广告是想暗示我的头发吗…(突然一阵风从我头上吹过,很凉快…)
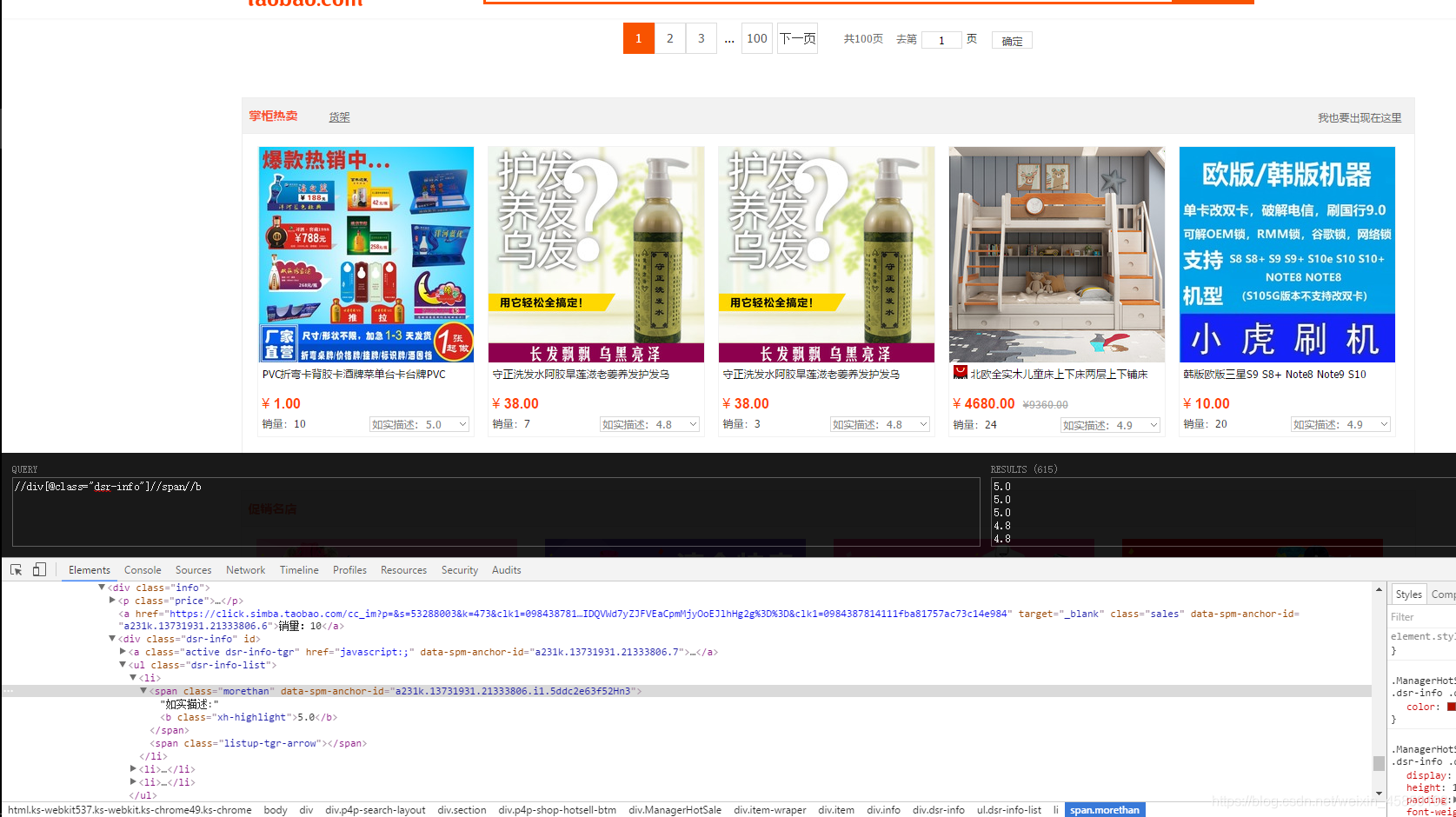
当场吐血,淘宝这么会玩…
最后再经历了一点磨难后,我找了一个和他们不一样的数据,就是id就是这个[//div[@id=“J_waterfallWrapper”],这是我发现下面那5个没有,但是上面的数据都在那里,所以就好办啦!
到了我们最后一步,保存数据,是不是一个爬虫就已经大功告成啦,所以爬虫是需要耐心滴!
#如实描述,创建几个空列表,来保存后面3个数据
temp=[]
#服务态度
temp_1=[]
#发货速度
temp_2=[]
i_1=0
#一开始的数据放进去
temp.append(score_list[i_1])
temp_1.append(score_list[i_1+1])
temp_2.append(score_list[i_1+2])for i in range(0,200):#防止报错try:i_1 += 3temp.append(score_list[i_1])temp_1.append(score_list[i_1+1])temp_2.append(score_list[i_1+2])except:break
#转化为浮点型,后面要进行总分评测
temp = list(map(float, temp))
temp_1 = list(map(float, temp_1))
temp_2 = list(map(float, temp_2))
#打印
mylog=open('淘宝商品大全.log',mode='a',encoding='utf-8')
for req,name,host,host_1,tem,tem_1,tem_2,link in zip(req_list,name_list,host_list,host_1_list,temp,temp_1,temp_2,link_list):sum=(tem+tem_1+tem_2)/3print('名字:%s 价格:$%s 付款人数:%s 商家名字:%s\n如实描述:%.1f 服务态度:%.1f 发货速度:%.1f 总分:%.2f''\n链接:%s\n-------------'%(name,req,host,host_1,tem,tem_1,tem_2,sum,link),file=mylog)
mylog.close()
print('爬取完成-v-')代码块
import requests
from lxml import etree
import re
import sysurl=input('请输入想查找的链接:')
#使用正则匹配,查看是不是我们要求的网页
url_link=re.findall("https://(.*?)/",url)
#这里是记个时,如果到5次就给他提示吧....
i=0
#死循环
while True:#判断是不是点进了淘宝热卖if url_link==['re.taobao.com']:breakelse:url = input('请重新输入淘宝热卖的链接:')url_link = re.findall("https://(.*?)/", url)i+=1#如果用户输入5次还是一样给出提示= =if i==5:print('提示:请进入https://re.taobao.com官网获取链接!')#模拟浏览器
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'}
#发送请求
response=requests.get(url,headers=headers).content.decode()
#解析成xpath格式
html=etree.HTML(response)
#价格
req_list=html.xpath('//span[@class="pricedetail"]//strong//text()')
#名字
name_list=html.xpath('//span[@class="title"]/@title')
#付款人数
host_list=html.xpath('//span[@class="payNum"]//text()')
#商家名字
host_1_list=html.xpath('//span[@class="shopNick"]//text()')
#评分,提示一下这里我找了挺久,因为id没加上多出了几个,淘宝也是坑
score_list=html.xpath('//div[@id="J_waterfallWrapper"]//span//b//text()')
#链接
link_list=html.xpath('//div[@id="J_waterfallWrapper"]//div[@class="item"]//a/@href')
#如实描述,创建几个空列表,来保存后面3个数据
temp=[]
#服务态度
temp_1=[]
#发货速度
temp_2=[]
i_1=0
#一开始的数据放进去
temp.append(score_list[i_1])
temp_1.append(score_list[i_1+1])
temp_2.append(score_list[i_1+2])for i in range(0,200):#防止报错try:i_1 += 3temp.append(score_list[i_1])temp_1.append(score_list[i_1+1])temp_2.append(score_list[i_1+2])except:break
#转个型
temp = list(map(float, temp))
temp_1 = list(map(float, temp_1))
temp_2 = list(map(float, temp_2))
#打印
#mylog=open('淘宝商品大全.log',mode='a',encoding='utf-8')
for req,name,host,host_1,tem,tem_1,tem_2,link in zip(req_list,name_list,host_list,host_1_list,temp,temp_1,temp_2,link_list):sum=(tem+tem_1+tem_2)/3print('名字:%s 价格:$%s 付款人数:%s 商家名字:%s\n如实描述:%.1f 服务态度:%.1f 发货速度:%.1f 总分:%.2f''\n链接:%s\n-------------'%(name,req,host,host_1,tem,tem_1,tem_2,sum,link))
#mylog.close()
print('爬取完成-v-')效果
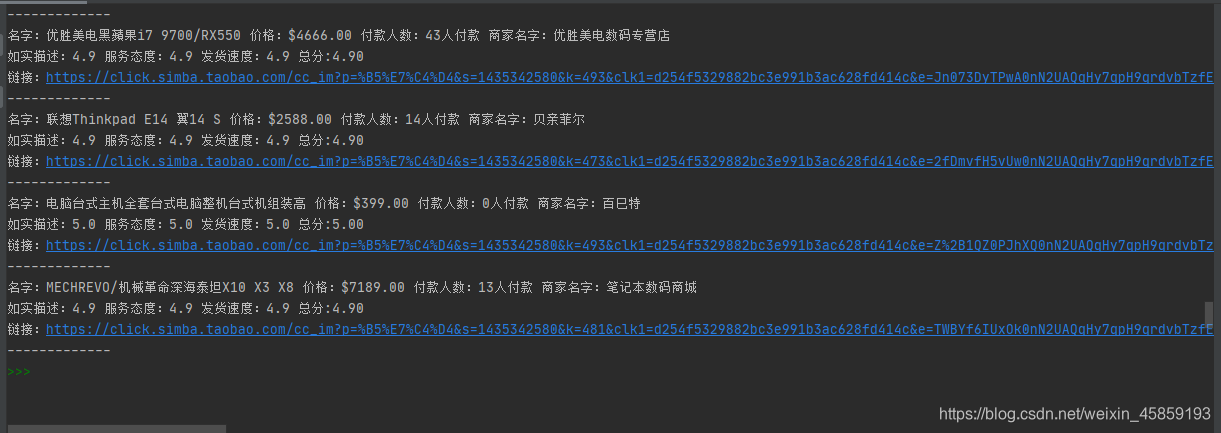
我就随便搜个电脑的链接吧!
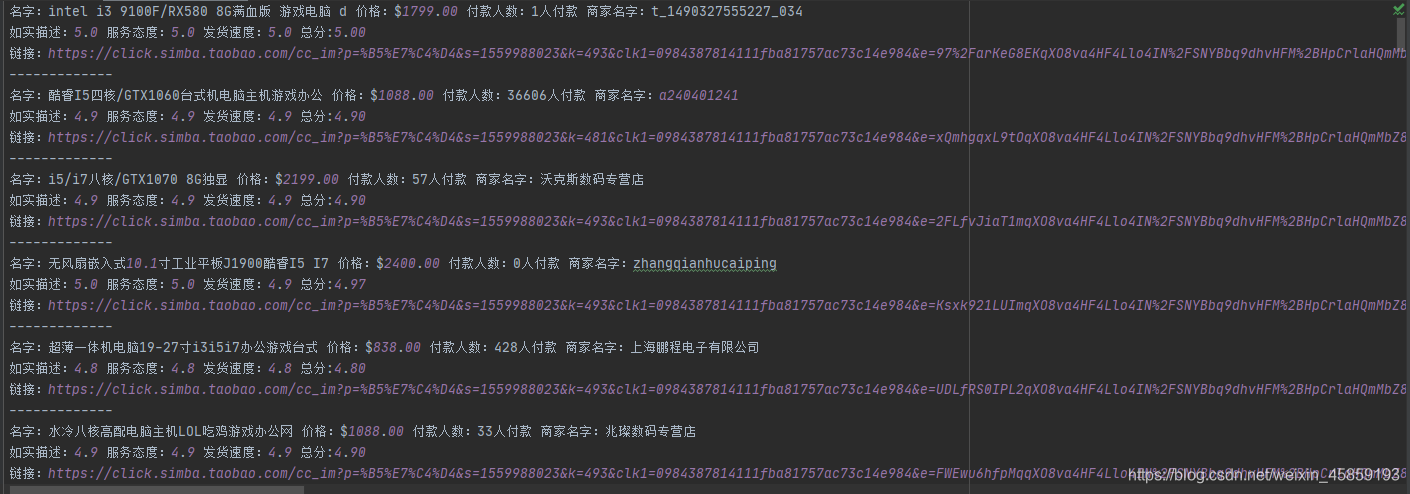
其实我还是喜欢不保存,因为用的是pycharm所以打开链接方便
这篇关于python爬取淘宝热卖商品(附xpath下载)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



