本文主要是介绍Python爬虫——爬取近3个月绵阳市降水量数据源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、基本目标
- 二、使用步骤
- 1.进行分析
- 2.整体代码
- 结果
- 总结
前言
😽爬取近3个月绵阳市的降水量数据,并存储在xlsx文档中。利用xpath和re爬虫技术获取数据,利用pandas把数据存储到xlsx文档中。
⚠️提示:爬虫不可用作违法活动,爬取时要设定休眠时间,不可过度爬取,造成服务器宕机,需付法律责任!!!
一、基本目标
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、使用步骤
1.进行分析
😿打开中国天气网的数据,发现只有40天的选项里能更全面的显示降水量,但是只能显示一个月的,我需要找到其他月份的数据

😹发现这边可以选择月份,初步认为当我选择月份的时候,会触发某些函数事件而返回数据。打开开发者工具,准备查看网络数据。
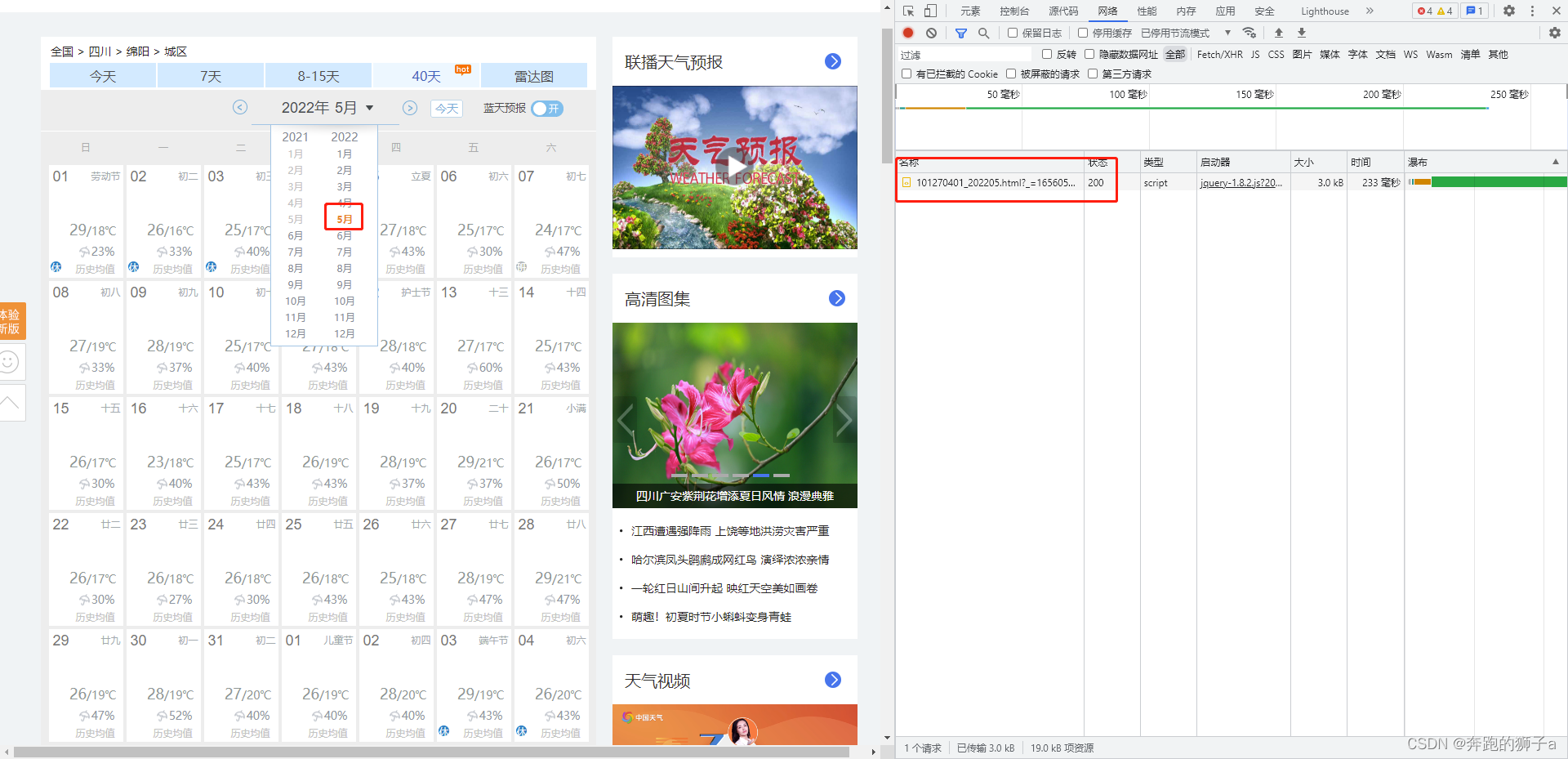
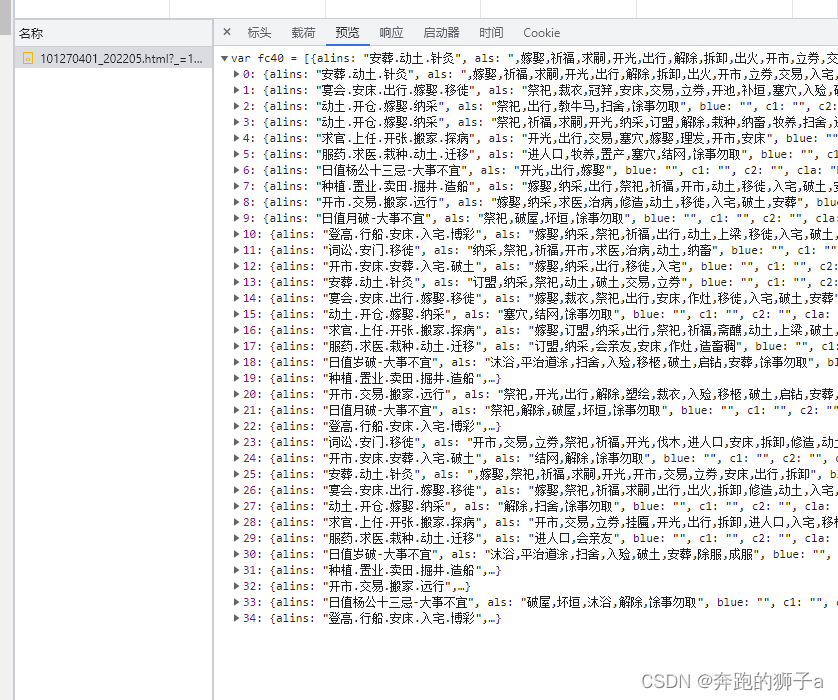
👺点击其他月份,出现了几个html的网络数据,点击Preview查看发现是具体的天气各项数据,包含日期、温度、降水、黄历等等信息。
2.整体代码
import requests
import json
import pandas as pd# 结果集合
result_list = []
for i in range(2,6):# 待爬取的urlurl = "http://d1.weather.com.cn/calendar_new/2022/101270401_20220"+(str)(i)+".html"# 反反爬headersheaders = {"Referer": "http://www.weather.com.cn/","Connection": "keep-alive","Content-Encoding": "gzip","Content-Type": "text/html","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36","Cookie": "f_city=%E5%8D%97%E5%AE%81%7C101300101%7C; Hm_lvt_080dabacb001ad3dc8b9b9049b36d43b=1654830903,1654838893,1654956338; Hm_lpvt_080dabacb001ad3dc8b9b9049b36d43b=1654957148","Accept-Encoding": "gzip, deflate","Accept-Language": "zh-CN,zh;q=0.9"}# 爬取resp = requests.get(url=url, headers=headers)resp.encoding = 'utf-8'# 数据字符串data_str = resp.text[11:]# 转json,变数据集合data_list = json.loads(data_str)# 循环数据集合,获取数据for data in data_list:data['城市'] = '绵阳'rain = data['hgl']date = data['date']result = {}result['城市'] = '绵阳'result['降水概率'] = rainresult['日期'] = dateresult_list.append(result)
print(result_list)
# pandas写入excel
data = pd.DataFrame(result_list)
writer = pd.ExcelWriter('降雨.xlsx') # 写入Excel文件
data.to_excel(writer, 'page_1', float_format='%.5f')
writer.save()
print("结束!")
结果
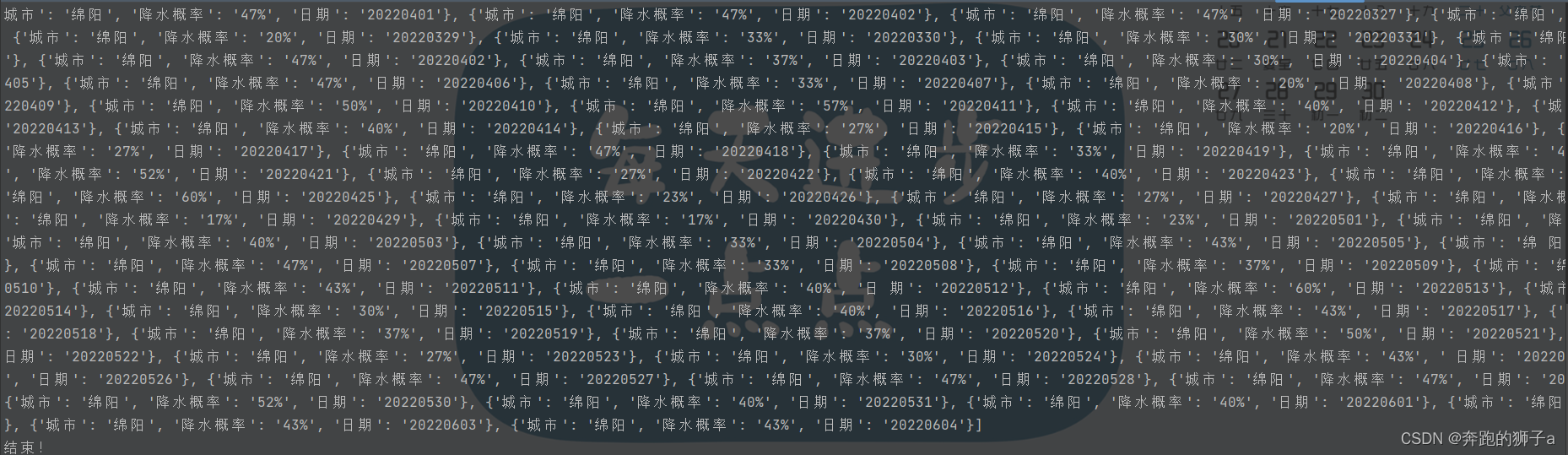
🐑程序运行结果如下
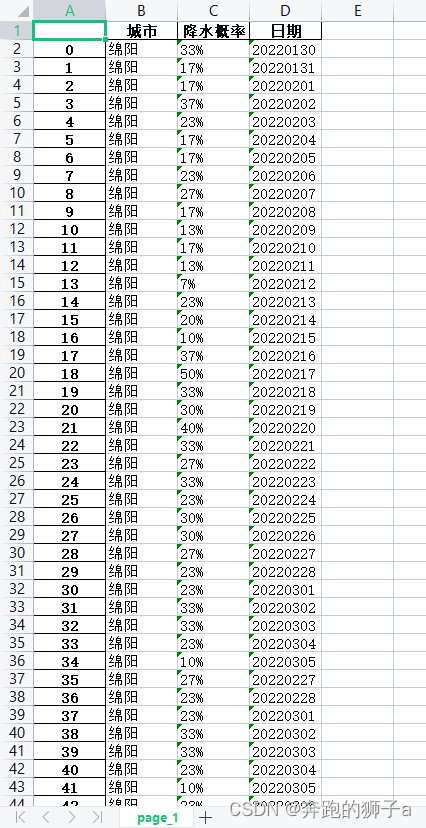
🐘存储的xlsx文档如下
总结
爬虫的基本步骤:
1.检查有没有反爬,设置常规反反爬,User-Agent和referer都是最常见的反爬手段
2.利用xpath和re技术进行定位,定位后获取想到的数据即可
3.pandas写入数据到xlsx文档
4.注意设置time休眠
这篇关于Python爬虫——爬取近3个月绵阳市降水量数据源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






