取近专题
Python爬取近10万条程序员招聘数据,告诉你哪类人才和技能最受热捧!
来源:凹凸数据 本文约5800字,建议阅读15分钟 本文带你了解当下企业究竟需要招聘什么样的人才?需要什么样的技能? 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大。因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于在校生,还是对于求职者来说,都显得很有必要。 本文基于这个问题,针对51job招聘网站,爬
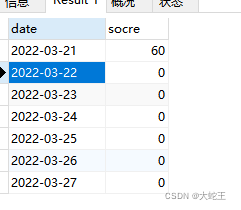
mysql 日期取近七天、当前周七天 数据(补全空数据) 简单案例
首先我们新建一张测试表格,date_day为日期,score为成绩,表格名ceshi。 我们如果取近七天的每天总成绩数据,常用的sql应该是: SELECT date_day,sum(score) as score FROM ceshi WHERE DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(date_day) GROUP BY date_day

python爬取近五年的华语电影,并储存到excel表
帮群里的一个小朋友写的,这些个名字不是我起的,大学生的作业,勿喷。 第n次更新,加了个获取快代理的免费代理,避免被豆瓣的反爬虫给怼自闭,不过还是有个小bug,就是爬取完成后不会停,如果一直在打印ip代理就手动停止一下吧。收工了,有啥问题可以扫码加我企业微信讨论。 代码如下,仅供参考: import timeimport xlwtfrom lxml import etreeimport
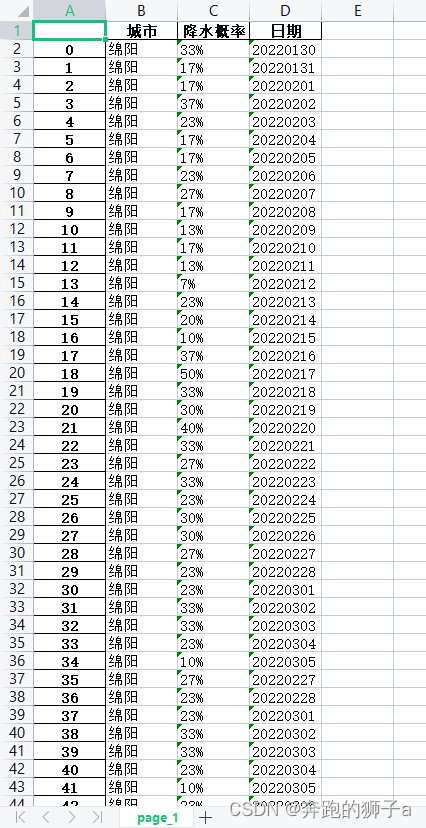
Python爬虫——爬取近3个月绵阳市降水量数据源
文章目录 前言一、基本目标二、使用步骤1.进行分析2.整体代码 结果总结 前言 😽爬取近3个月绵阳市的降水量数据,并存储在xlsx文档中。利用xpath和re爬虫技术获取数据,利用pandas把数据存储到xlsx文档中。 ⚠️提示:爬虫不可用作违法活动,爬取时要设定休眠时间,不可过度爬取,造成服务器宕机,需付法律责任!!! 一、基本目标 示例:pandas 是基于