本文主要是介绍【深度学习服务器环境配置】显卡驱动、CUDA11、CUDNN及torch、tensorflow安装,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 丑话说在前
- 一、了解服务器配置
- 1.系统版本信息
- 2.显卡信息
- 二、安装驱动及CUDA
- 1.驱动安装
- 2.卸载旧CUDA(选)
- 3.CUDA11安装
- 1)下载安装
- 2)配置环境变量
- 3)查看是否安装成功
- 三、安装CUDNN
- 1.下载
- 2.解压安装
- 3.查看是否安装成功
- 四、 安装anaconda
- 1.下载安装
- 2.设置环境变量
- 五、安装深度学习库
- 1.torch安装
- 2.tensorflow安装
- 总结
丑话说在前
首先,我基本是现学现卖,linux基础懂一点,深度学习基础懂一点,然后服务器也只玩过阿里云的,以下内容是配了学院四台服务器深度学习环境后总结出的笔记,希望能帮到下一个学习的你
(必要时候请掌握科学上网方法)
如果你不了解配置流程,你可以先泛读全文,了解下配置的大概流程。本文,我会从一个未安装显卡驱动和CUDA的服务器开始记录起(升级cuda的方法请从卸载旧cuda读起),内容包括安装anaconnda、cuda、cudnn以及深度学习常用库pytorch和tensorflow。可以选择你需要配置的部分阅读。
一、了解服务器配置
包括:服务器安装的系统版本信息、显卡信息等
1.系统版本信息
服务器安装的系统各不相同(window较少见),较常见的是轻量级的centos和ubuntu。
因接下来下载cuda等配件时需选择系统版本信息,所以需提前了解系统版本信息,
- 查看linux系统版本命令:
lsb_release -a
- 输出:
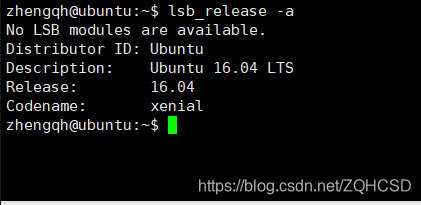
如图:该服务器安装的linux版本为Ubuntu16.04
2.显卡信息
如果服务器未安装显卡情况下,nvidia-smi命令输出将为空,那么要了解显卡信息需用以下命令:
lspci | grep -i nvidia
输出:
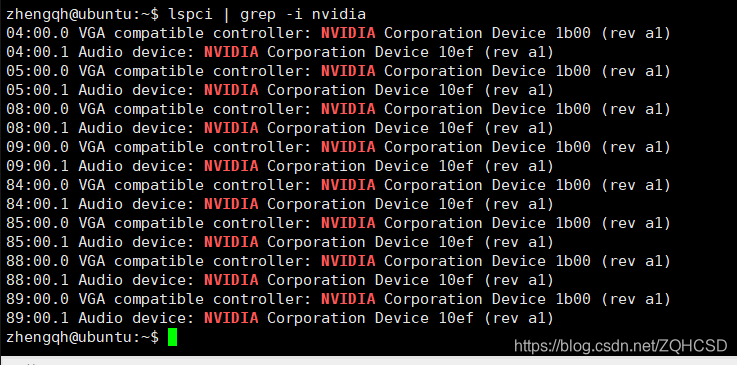
【这™是什么鬼.png】
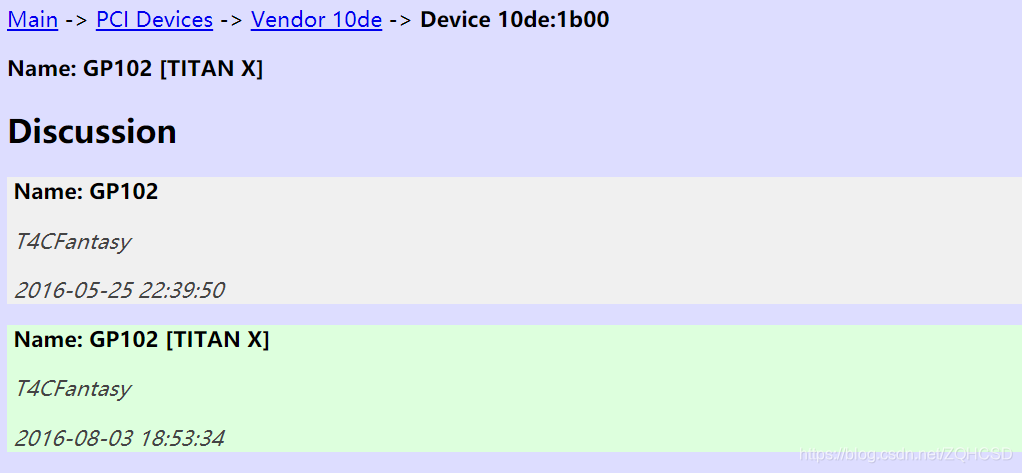
由于驱动问题无法显示显卡的具体型号,在网址输入1b00,可以看到显卡型号是:TITAN X
二、安装驱动及CUDA
1.驱动安装
因为安装CUDA时会有选项让你选择是否安装显卡驱动,选择是,便会帮你安装好新驱动,所以无论是安装(升级)驱动还是安装(升级)CUDA,都可以选择跳过手动安装驱动步骤,直接到下一步安装cuda。
2.卸载旧CUDA(选)
如安装过cuda,想升级CUDA版本,需先卸载旧的cuda版本,卸载方法也很简单
原理(按cuda8.0):
在安装cuda时默认会安装在/usr/local/cuda-8.0文件夹下
卸载cuda8.0,则只需要运行文件夹下的uninstall文件卸载即可
命令如下:
sudo /usr/local/cuda-8.0/bin/uninstall_cuda_8.0.pl
卸载之后,会发现cuda-8.0该文件夹还存在,这是cudnn文件,所以输入命令将文件删除干净:
sudo rm -rf /usr/local/cuda-8.0
同理安装cuda其他版本时默认都会安装在/usr/local/下对应的文件夹下,卸载只需运行uninstall文件即可。
3.CUDA11安装
1)下载安装
在Google(或百度)输入CUDA11.0 download

进入官网下载

根据服务器系统版本信息选择相应选项,可见支持Installer Type(安装类型)有三种,这里我们选择第一种本地运行文件(runfile)
因学院服务器并为配置完全以及其他不可抗原因(不想处理报错能力有限 )我们选择第一种安装方法。
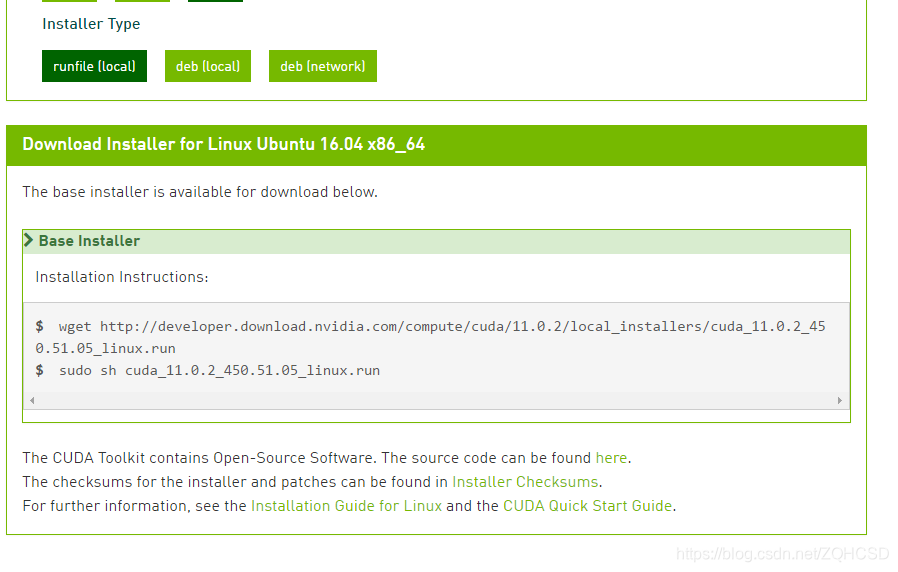
基础安装指导(base Installer)显示,我们只需要运行两句命令:
下载cuda的run文件
wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda_11.0.2_450.51.05_linux.run

使用管理员权限运行该安装文件
sudo sh cuda_11.0.2_450.51.05_linux.run
运行安装文件会显示几个可选项:
依次如下:
1 .输入:accept,接受协议

2.选择默认配置(包括安装驱动)Install

静待安装。
2)配置环境变量
修改环境变量文件~/.bashrc(该文件是在根目录下的隐藏文件,根目录下输入ls -a可见)
vim ~/.bashrc
在变量文件后加上下面三句:
export CUDA_HOME=/usr/local/cuda-11.0
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}保存并退出(关于vim的用法如果你不是很懂的话,我这里大概说一下,进入vim编辑环境需要按 i,进入命令环境按 esc,保存并退出(在命令环境)按 :wq(w表示写,q表示退出))。
最后执行.bashrc:
source ~/.bashrc
使其生效
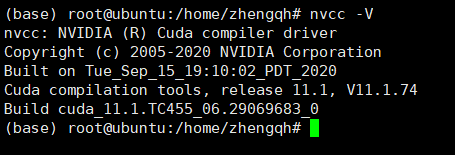
3)查看是否安装成功
使用命令nvcc -V查看安装版本信息:
三、安装CUDNN
1.下载
到官网下载对应cuda和linux版本的cudnn
先在本地电脑下载完上传到服务器,下载后格式为.solitairetheme8文件,需先转为压缩包格式后解压
执行命令:
cp cudnn-11.0-linux-x64-v8.0.5.39.solitairetheme8 cudnn-11.0-linux-x64-v8.0.5.39.tgz
tar -zxvf cudnn-11.0-linux-x64-v8.0.5.39.tgz
2.解压安装
解压后再拷贝文件到CUDA目录下即可:
cp cuda/lib64/* /usr/local/cuda-11.0/lib64/
cp cuda/include/* /usr/local/cuda-11.0/include/3.查看是否安装成功
查看信息,是否安装成功
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2(网上说有输出证明是安装成功,但我本次安装的三台服务器都无输出,仔细查看对应的cudnn.h文件后发现文件中并无cudnn版本信息,个人猜测是新版的cudnn文件中无版本信息)
四、 安装anaconda
1.下载安装
- 官网下载linux对应版本anaconda
下载后上传服务器
- 查看当前目录下的文件
- 给与安装文件可执行权限
- 运行安装文件
ls
sudo chmod +x Anaconda3-2020.11-Linux-x86_64.sh
./Anaconda3-2020.11-Linux-x86_64.sh
- 如图:

- 安装选项如下
回车(继续)

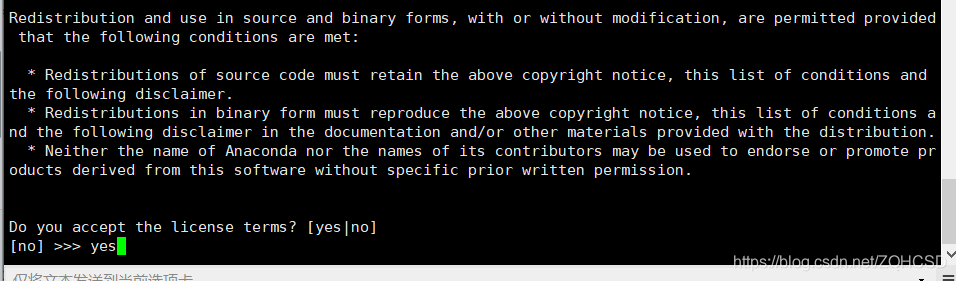
安装协议,按q退出

接受协议,输入yes
设置安装路径

添加配置环境,输入yes

静待安装完成
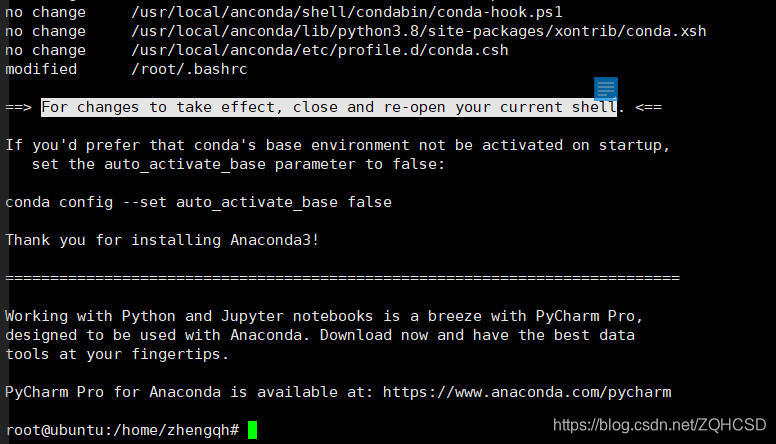
安装完成,提示告诉我们(for changes to take…)关闭旧连接打开新shell,经过我实验发现仅需要运行下环境配置文件即可。
source ~/.bashrc
此时在输入conda即有相关信息输出,安装完成
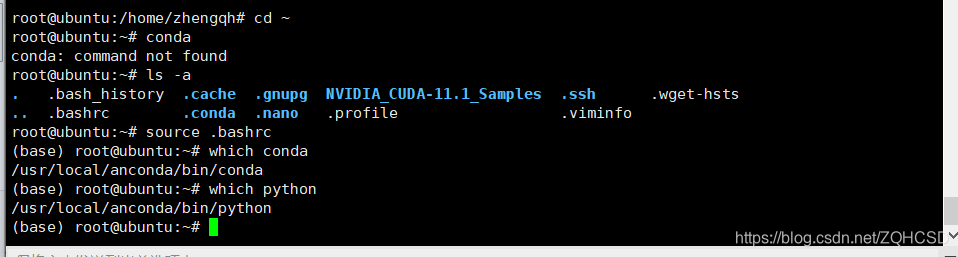
2.设置环境变量
上述操作虽完成了anaconda的安装,但细心的你一定发现该安装仅在该安装用户下(我的操作都是在root用户下)。所以需要添加个环境变量,使得所有用户都能使用anaconda。(也可以针对单个用户更改用户对应的.bashrc文件即可)
在已安装anaconda的用户下执行命令:
vim /etc/environment
在添加上安装anaconda路径,注意分割符":"(如我添加):
/usr/local/anconda/bin
重启,操作生效,所有用户都能使用anaconda。
五、安装深度学习库
1.torch安装
官网选择安装选项信息,使用conda命令下载安装
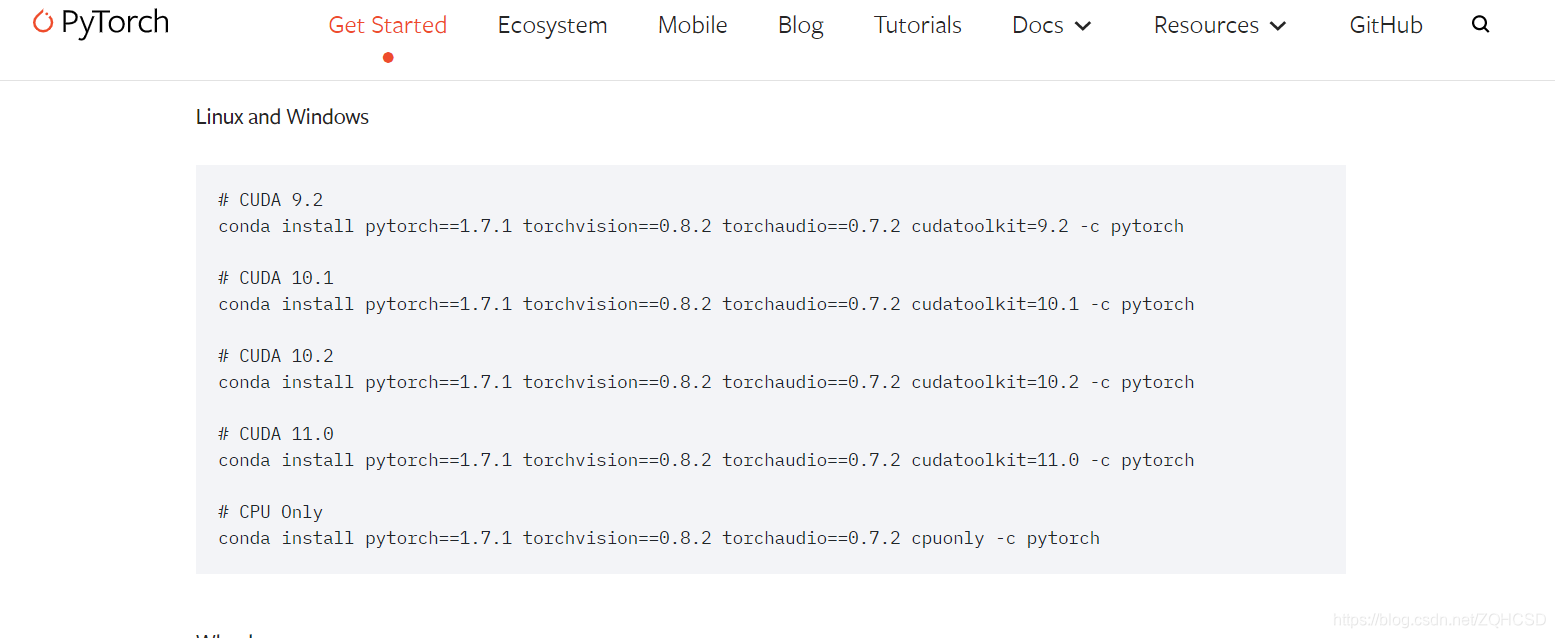
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
注意:安装pytorch时官方会顺便安装类似cudnn的包,因此我们上面也可以不用安装cudnn
- 检测是否torch-gpu安装成功,依次输入:
python
import torch
torch.__version__
torch.cuda.is_available()
输出结果为true,安装成功
如图:

2.tensorflow安装
同样使用pip命令安装,如:
pip install tensorflow-gpu==2.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
需要注意的是tensorflow版本与对应的cuda和cudnn版本需按官方支持版本对应

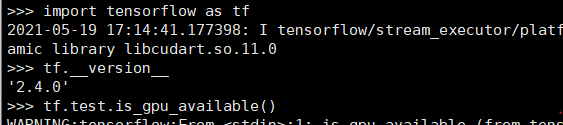
- 检测是否torch-gpu安装成功,依次输入:
python
import tensorflow as tf
tf.__version__
tf.test.is_gpu_available()
输出结果为true,安装成功
如图:

总结
1.服务器未安装驱动时可以跳过手动安装显卡驱动环境,直接安装cuda(安装cuda时会默认安装对应版本显卡驱动)
2.安装anconda时基本默认安装即可(安装路径可自行修改)
3.安装tensorflow库时,需注意到官网查看对应cuda版本信息,以免不兼容(不兼容时可用使用多cuda切换的方式,其实也就是安装多个版本cuda,在需要时通过修改配置文件切换对应版本)。
参考:
https://blog.csdn.net/wuzhongqiang/article/details/109703047
https://blog.csdn.net/xiao_xian_/article/details/109054598
https://blog.csdn.net/wanzhen4330/article/details/81699769
这篇关于【深度学习服务器环境配置】显卡驱动、CUDA11、CUDNN及torch、tensorflow安装的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




