cudnn专题

torch.backends.cudnn.benchmark和torch.use_deterministic_algorithms总结学习记录
经常使用PyTorch框架的应该对于torch.backends.cudnn.benchmark和torch.use_deterministic_algorithms这两个语句并不陌生,在以往开发项目的时候可能专门化花时间去了解过,也可能只是浅尝辄止简单有关注过,正好今天再次遇到了就想着总结梳理一下。 torch.backends.cudnn.benchmark 是 PyTorch 中的一个设置

windows 机器学习 tensorflow-gpu +keras gpu环境的 相关驱动安装-CUDA,cuDNN。
本人真实实现的情况是: windows 10 tensorboard 1.8.0 tensorflow-gpu 1.8.0 pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ tensorflow-gpu==1.8.0 Keras 2.2.4 pip

Pytorch安装 CUDA Driver、CUDA Runtime、CUDA Toolkit、nvcc、cuDNN解释与辨析
Pytorch的CPU版本与GPU版本 Pytorch的CPU版本 仅在 CPU 上运行,适用于没有显卡或仅使用 CPU 的机器。安装方式相对简单,无需额外配置 CUDA 或 GPU 驱动程序。使用方式与 GPU 版相同,唯一不同的是计算将自动在 CPU 上进行。 Pytorch的GPU版本 在 NVIDIA GPU 上运行,充分利用 CUDA(Compute Unified Device

Ubuntu16.04安装Nvidia驱动cuda,cudnn和tensorflow-gpu
本文个人博客地址: 点击查看之前有在阿里云GPU服务器上弄过: 点击查看, 这里从装Nvidia开始 一、 安装Nvidia驱动 1.1 查找需要安装的Nvidia版本 1.1.1 官网 官网上查找: https://www.nvidia.com/Download/index.aspx?lang=en-us 这里是 GeForce GTX 1080 TI如下图,推荐 410 版本的
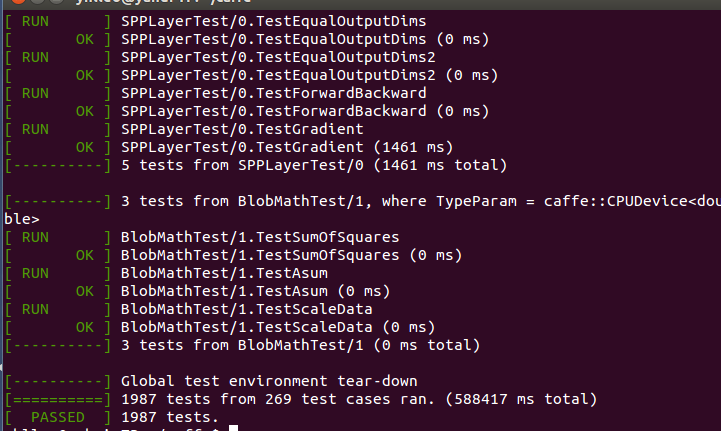
cuda caffe cudnn
本系列文章由 @yhl_leo 出品,转载请注明出处。 文章链接: http://blog.csdn.net/yhl_leo/article/details/50961542 花了一天时间,在电脑上安装配置了Caffe深度学习框架,网上的很多教程和指导都已经过期,中间辗转耗费了点时间,这里把个人认为最简单的方法整理如下。 1 版本 笔记本:ThinkPad W541

Loaded runtime CuDNN library: 7101 (compatibility version 7100) but source was compiled with 7005
https://blog.csdn.net/qq_22532597/article/details/80314896 https://blog.csdn.net/zw1078825408/article/details/82390542

CUDA, CUDNN 版本查询
CUDA 查询: cat /usr/local/cuda/version.txt 或者 nvcc -V (也可以看到版本信息) CUDNN 查询: cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 --------------------- 作者:Y-hit 来源:CSDN 原文:https://blog.csd

Ubuntu下tensorflow的安装(Ubuntu14.0+cuda8.0+cudnn v6+ Anaconda3-5.0.1+ tensorflow gpu1.3)
一、安装显卡驱动cuda和cudnn 1、这里用的是cuda8.0,因为购买的服务器已经配置好的cuda环境,所以暂时先略过。 2、安装cudnn。 如果要使用gpu来对tensorflow进行加速,除了安装CUDA以外,cuDNN也是必须要安装的。跟cuda一样,去nvidia的官网下载cuDNN的安装包。 这里注意:不要下cuDNN v5.1Developer Library for

conda虚拟环境中安装cuda和cudnn
目录 一、cuda安装步骤 1)cuda的安装 1、查看conda支持的cuda版本 2、下载cuda并安装cuda 2)cudnn的安装 1、查看cuda对应的cudnn版本 2、下载cudnn并安装 二、torch的安装和tensorflow的安装 1)安装tensorflow 1、确定安装版本并安装 2、验证是否可以调用gpu 2)安装torch 1、安装torch

WSL-ubuntu下载安装配置cudnn
下载 安装cuDnn的话需要和CUDA版本对应,可参考官网: cuDNN Archive | NVIDIA Developer 我的cuda是11.8 这个cuDNN8.9.7_Linux直接下载: https://developer.nvidia.com/downloads/compute/cudnn/secure/8.9.7/local_installers/11.x/cudnn

Ubuntu 20.04安装显卡驱动、CUDA和cuDNN(2024.06最新)
一、安装显卡驱动 1.1 查看显卡型号 lspci | grep -i nvidia 我们发现输出的信息中有Device 2230,可以根据这个信息查询显卡型号 查询网址:https://admin.pci-ids.ucw.cz/mods/PC/10de?action=help?help=pci 输入后点击Jump查询 我们发现显卡型号为RTX A6000
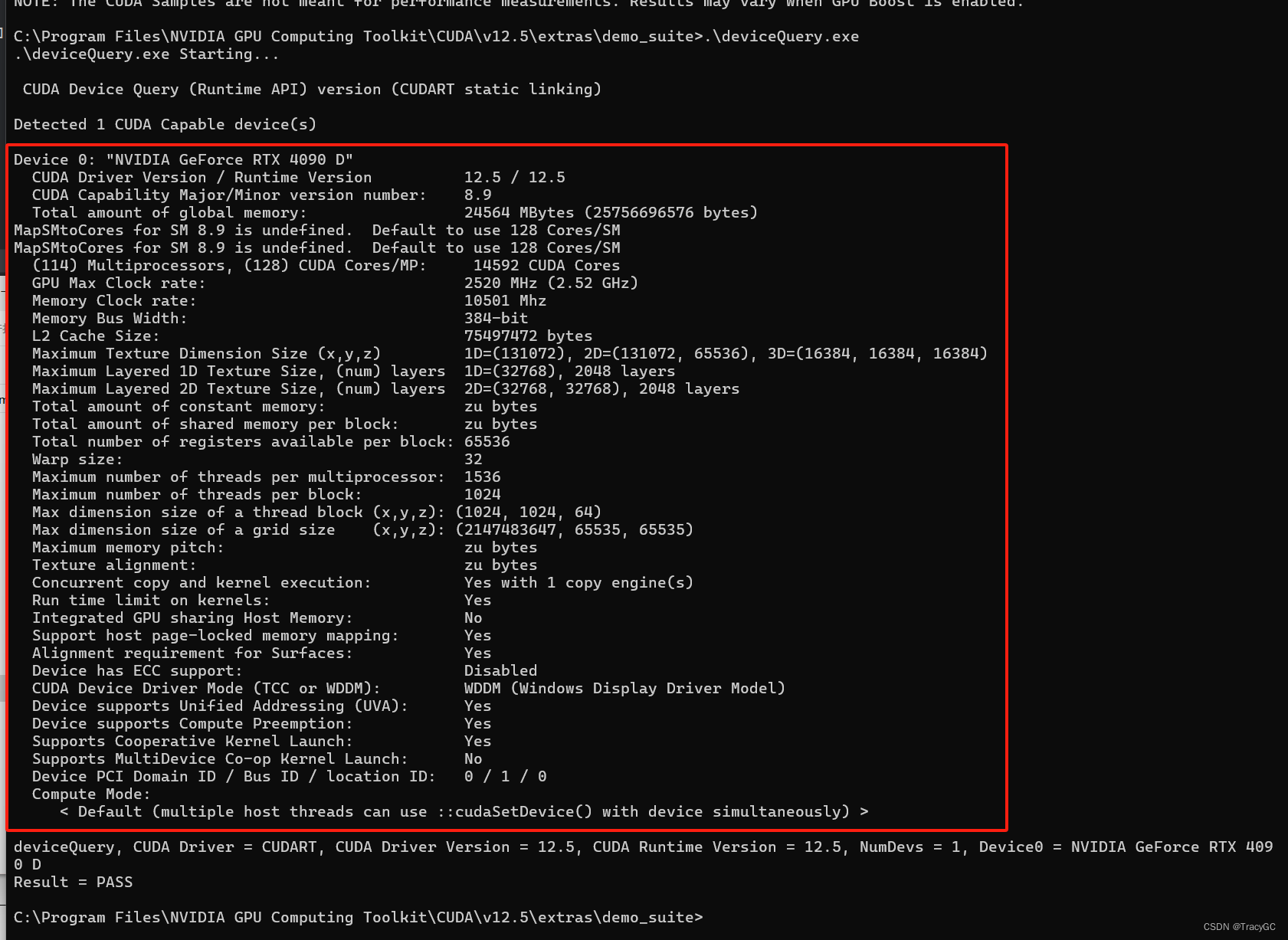
显卡nvidia的CUDA和cuDNN的安装
显卡版本,和nvidia下载的 CUDA版本和CUDNN的关系 1. 显卡版本 nvidia-smi 硬件环境:显卡版本 4090 + NVIDIA-SMI-555.85 我的驱动是510.85.02,驱动附带cuda=12.5 2. nvidia下载的cuda版本 nvcc -V 我下载的是cuda12.5 cuda在安装版本过程中需要确定安装版本!!! 在安
安装cuda、cudnn、Pytorch(用cuda和cudnn加速计算)
写在前面 最近几个月都在忙着毕业的事,好一阵子没写代码了。今天准备跑个demo,发现报错 AssertionError: Torch not compiled with CUDA enabled 不知道啥情况,因为之前有cuda环境,能用gpu加速,看这个报错信息应该是Pytorch下没有可用的cuda,不知道咋没了。因而决定从头开始配置一下环境,以此博文记录一下~ 安装cuda
Tensorflow-GPU CUDA cuDNN版本支持关系(windows)
数据来源:https://www.tensorflow.org/install/source VersionPython versionCompilerBuild toolscuDNNCUDAtensorflow_gpu-1.12.03.5-3.6MSVC 2015 update 3Bazel 0.15.079tensorflow_gpu-1.11.03.5-3.6MSVC 2015 updat
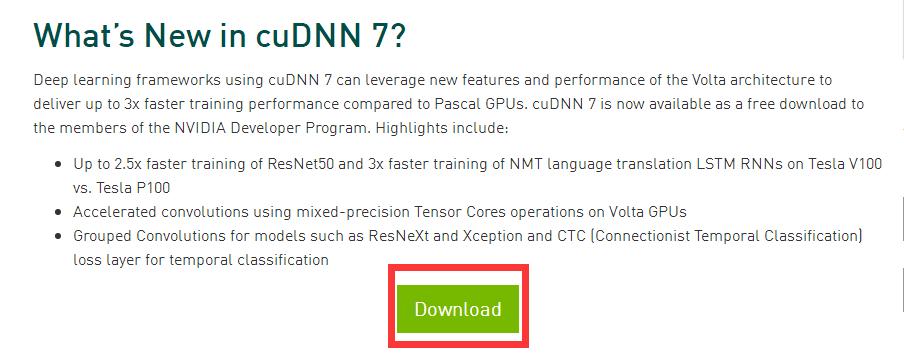
下载cuDNN历史版本方法
下载cuDNN历史版本方法 打开https://developer.nvidia.com/登录。点击Deep Learning SDK 点击Download deep learning software 点击cuDNN 点击Download 填完一系列问卷之后就可以进行下载:
在Deeplearning4j中使用cuDNN
在Deeplearning4j中使用cuDNN Deeplearning4j支持cuda,但是也支持使用cuDNN实现更进一步的加速。自从版本0.9.1之后,CNNs和LSTMs网络都支持cuDNN加速。 注意: cuDNN并不支持GravesLSTM网络层,请考虑使用LSTM网络层进行替代。为了使用cuDNN,你首先需要切换Nd4j的后端至CUDA后端。这个可以通过在你项目中的pom.xml

windows下配置gpu加速——cuda与cudnn安装
windows下配置gpu加速——cuda与cudnn安装 一、系统情况二、安装工具准备三、工具安装1、 显卡驱动安装2、cuda9.0安装3、cudnn9.0安装4、vs2015安装 四、使用vs2015编译cuda 一、系统情况 系统:windows7 gpu:quadro p620 注意:pascal架构显卡只能使用cuda8.0,所有资源(除显卡驱动)见该网盘地址 二、

CUDA、CUDNN、Torch的配置
文章目录 一、 配置CUDA1.CUDA下载2.CUDA安装3.CUDA配置环境4.CUDA是否配置成功 三、 配置CUDNN四、配置torch1.创建Python 3.8环境并激活2.下载torch-GPU版本 一、 配置CUDA Win+R打开命令行,输入cmd,在终端输入:nvidia-smi。 查看本机的GPU信息 1.CUDA下载 CUDA下载链接:https:
windows下安装cuda+cudnn+python人工智能环境
安装python3 https://www.python.org/downloads/windows/ https://www.python.org/ftp/python/3.9.13/python-3.9.13-amd64.exe 以Tesla T4显卡为例 安装显卡驱动 https://www.nvidia.cn/content/DriverDownloads/confirmation

ubuntu 16.04安装nvdia驱动,cuda驱动以及cudnn
一. nvidia驱动安装 1. 查询显卡型号 nvidia-smi -L 出现显卡型号,我的是:GPU 0: GeForce RTX 2080 SUPER 2. 查询显卡驱动 网址:https://www.geforce.cn/drivers 输入显卡型号并搜索,列表中会出现很多驱动版本,选择一款驱动 3.安装显卡驱动 网上常见的做法是:从命令行系统安装,巨麻烦,推荐使用ap
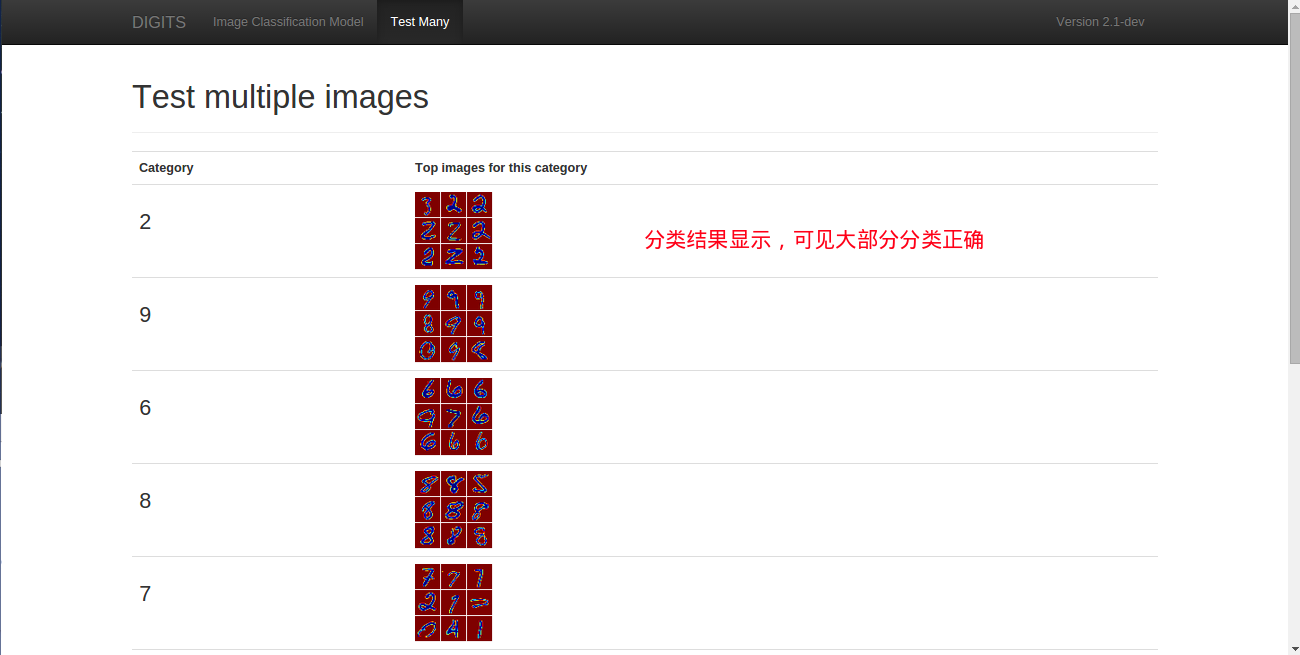
NVIDIA DIGITS 学习笔记(NVIDIA DIGITS-2.0 + Ubuntu 14.04 + CUDA 7.0 + cuDNN 7.0 + Caffe 0.13.0)
NVIDIA DIGITS-2.0 + Ubuntu 14.04 + CUDA 7.0 + cuDNN 7.0 + Caffe 0.13.0环境配置 引言 DIGITS简介DIGITS特性资源信息说明 DIGITS安装 软硬件环境 硬件环境软件环境 操作系统安装DIGITS安装前准备 安装CUDA70deb方式 显卡切换 安装cuDNN70安装Caffe-0130 安装DIGITS启

基于ubuntu安装cuda,cuDNN
1.cuda驱动安装 (1)下载驱动 NVIDIA 驱动程序下载, 根据自己的GPU型号旋转相应的驱动进行下载,下载后的驱动程序放入主目录下(/home/my_work),这是因为在后续的驱动纯命令行安装环境下,不支持中文输入,不容易切换目录。 (2)卸载原有驱动 两种方式,如果新装的的系统,就不必执行以下代码 #for case1: original dr
PyTorch、显卡、CUDA 和 cuDNN 之间的关系
概述 PyTorch、显卡、CUDA 和 cuDNN 之间的关系及其工作原理可以这样理解: 显卡 (GPU) 显卡,特别是 NVIDIA 的 GPU,具有大量的并行处理单元,这些单元可以同时执行大量相似的操作,非常适合进行大规模矩阵运算,如深度学习中的卷积神经网络(CNNs)和循环神经网络(RNNs)的计算。 CUDA CUDA(Compute Unified Device Archit
记录深度学习GPU配置,下载CUDA与cuDnn,安装tensorflow
目标下载: cuda 11.0.1_451.22 win10.exe cudnn-11.0-windows-x64-v8.0.2.39.zip Anaconda的安装请看别的博主的,这里不再赘述 看看自己电脑的cuda 方法一:打开英伟达面板查看 方法二:使用命令行 随便找个文件夹,在顶部路径输入"cmd" 输入下面命令 nvidia-smi 我的目标下载cu

【nvidia】3.cuda及cudnn安装
文章目录 第一步:检测显卡的计算能力以及匹配的cuda版本第二步:检查显卡驱动版本以及可适配的cuda版本第三步:安装CUDA 10第四步:设置cuda的 路径变量第五步:运行CUDA example,验证安装是否正确第六步:下载并安装CuDNN 在系统 显卡安装完成以及 旧版本卸载后,初装cuda toolkit。 第一步:检测显卡的计算能力以及匹配的cuda版本 可
Cannot load cudnn shared library. Cannot invoke method cudnnGetVersion.
PaddleDetection 运行时报错解决方案 报错信息 Traceback (most recent call last):File "/PaddleDetection/deploy/pipeline/pipeline.py", line 1103, in <module>main()File "/PaddleDetection/deploy/pipeline/pipeline.py",