本文主要是介绍jupyternotebook 报告_利用Jupyter Notebook制作美观的数据报告,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2020-08-17
在机器学习、数据分析领域,Jupyter Notebook 已经是大家很熟悉的一个“工作平台”了,它允许我们一边写code算数据,将结果以图文的方式记录和保存下来,再辅以 Markdown 的文本,则可以直接转存成一篇完整的数据报告。
出于各种原因,我们往往需要将整个报告转存成PDF格式,并希望它包含清晰的图片、得体的字体和优美的排版,而这些元素,仅靠Notebook则有些力不从心。

我们更希望看到的是这样的报告文档:

那么该如何实现呢?实际上开源工具足够我们完成这样的工作。
经过一番搜索,我找到了 WeasyPrint 这个工具,它可以将网页转存为PDF文档,而Jupyter Notebook是可以直接存为html文档的,再搭配适当的css文件,将两者结合,就可以生成美观的数据分析报告(这里是一个报告文档的例子)。
在这个过程中,关键需要做以下几点操作:
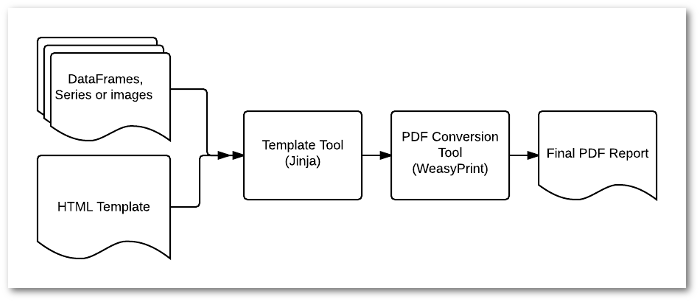
由Notebook转存为具有合适结构的html文档
Jupyter转存为html文件,依赖于Jinja引擎进行转换,所以这里首先需要修改Jupyter原有的网页模版文件,例如只保留正常的图片和文字输出等,我这里做好了一份模版,以供参考。
在转存为html文件后,还需要对html文件更进一步处理,使它具备更清晰的逻辑结构,方便套用css文件进行排版。
制作适当的css文件
要对网页内容进行排版,与网页内容搭配使用的css文件是必需的,这里我就不赘述了。
使用WeasyPrint进行转换
这里当然先要安装工具包,使用pip直接安装即可。另外,作图主要使用plotly来做,因为它可以保存svg格式的图片,有效保证了图像质量。
上面描述的只是大致流程,我依照这个流程写了一个工具包,方便大家体验,名称为SmartyDoc,也非常欢迎感兴趣的朋友共同优化这个工具。
这篇关于jupyternotebook 报告_利用Jupyter Notebook制作美观的数据报告的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








