本文主要是介绍Tensorflow回归入门实践-预测70年代末到80年代初汽车燃油效率的模型(详解,提供数据集),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章较长,可以跳转查看需要的部分
- 回归的目的
- 数据集(提供网盘下载)
- 网盘下载(如果无法直接下载数据集)
- 基本实现结构的分析(数据部分)
- 首先引入需要的模块or包
- 获取数据集(本地数据集读取)
- 设置数据标签
- 补充data文件类型:
- 使用panda读取数据集
- 对数据进行处理(一)
- 对数据进行处理(二)
- 对数据进行处理(三)
- 数据归一化
- 模型分析
- 模型构建
- 模型检测
- 数据拟合
- 训练结果数据展示(建议使用jupyter notebook)
- 模型日志的查看
- 模型训练的日志信息-可视化
- 创建绘图函数
- 可视化展示(发现训练多了反而出问题了——过拟合)
- 模型改进
- 模型评估
- 使用完整的测试数据预测(最后阶段可视化)
- 预测MPG的数据可视化
- 误差分布可视化
- 总结
QQ:3020889729 小蔡
这是一个学习例程的学习分享,希望对tensorflow的学习和理解有所帮助,当然还有API-keras本身的认识提升。
(本博客提供数据集下载(备份),是因为原官方数据集在下载时,出现链接超时的失败问题。)
(建议使用jupyter notebook)
(文章较长,还望根据需要合适的阅读——有效利用学习时间。)
回归的目的
与其说什么是回归来促进理解,我觉得了解回归的目的是什么会更有效。
回归是为了,预测出如价格或概率以及某种这样连续值/信息的输出。
比如,我给一段连续时间的食品销售量,然后在相同的条件下去预估接下来一段时间或下一次可能的结果。(这和我们上学时,接触的数学回归问题,得到一个回归方程展示其在具体问题中的实际意义是一样的。)
与分类相比,它的目的是为了预测下一段时间/空间最可能出现的结果,不同于分类需要具体的图像或者感知才进行预测是什么。
数据集(提供网盘下载)
本次使用的数据集是Auto MPG数据集——我们将利用它来构建一个用于预测70年代末到80年代初汽车燃油效率的模型。
该数据集包含信息:气缸数,排量,马力以及重量。
网盘下载(如果无法直接下载数据集)
数据集下载:https://pan.baidu.com/s/13fCzCHk3Myhdv0X70QL0Fw
提取码:bnoz
基本实现结构的分析(数据部分)
首先引入需要的模块or包
- import pathlib # 引入文件路径操作的模块
- import pandas as pd # 引入panda科学数据处理包
- import seaborn as sns # 引入seaborn——绘图包,在pycharm中使用,需要调用pyplot的show()
- import matplotlib.pyplot as plt # 标准绘图包
- import tensorflow as tf # 引入tensorflow包
- from tensorflow import keras # 引用tf包下的keras——这就是我们将用使用的高级API
- from tensorflow.keras import layers # 引出layers模块,这是网络层相关的模块
关于下载包/模块,需要说明几点(这里默认下载好了tensorflow):
- pathlib无需下载——内置
- seaborn需要下载,最好用pip,conda可能会有问题
- keras可能在一开始下载tensorflow后没有,那你需要单独下载keras——如果是2.0.0及以上的tensroflow只需要安装比较新的keras即可(也就是直接pip)。
代码:
import pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
获取数据集(本地数据集读取)
无论是否是去Auto MPG下载的数据集,都还是调用以下方法加载数据集本地路径:
keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
如果是通过网盘下载的数据集,我们都需要将数据集放在C盘的user文件夹下的.keras文件夹里的datasets下:即:C->user(也就是用户根目录)->.keras->datasets
如果没有文件就user目录下,创建对应的文件,然后存放数据集。
代码:
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path # 可查看数据——jupyter notebook可直接显示,pycharm需要print
效果:(我已经下载放在指定目录,所以没有下载步骤的显示)

设置数据标签
由于读取的数据是是一个data文件,本身就类似于表格,所以我们需要为其读取前,设置好对应的列名-标签。
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight','Acceleration', 'Model Year', 'Origin']
数据标签含义:
- MPG:每加仑燃料所行英里数
- Cylinders:气缸数
- Displacement:排量
- Horsepower:马力
- Weight:重量
- Acceleration:加速能力
- Model Year:车型年份——即生产(研发)年份
- Origin:产源地
代码:
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight','Acceleration', 'Model Year', 'Origin']
补充data文件类型:
DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
使用panda读取数据集
需要说明以下主要参数:依次为路径,索引名,空(无效)值设置,指定注释行,分隔符,是否考虑为False的数据
raw_dataset = pd.read_csv(dataset_path, names=column_names,na_values = "?", comment='\t',sep=" ", skipinitialspace=True)
参数含义对应展示:
- dataset_path——读取路径
- names——数据读取后的列索引名
- na_values——空(无效)值设置,这里设置为?
- comment——指定‘\t’对应的行为注释行,不读取
- sep——数据分隔符
- skipinitialspace——是否考虑为False的数据,即数据中存在False的bool值是被允许的
代码:
raw_dataset = pd.read_csv(dataset_path, names=column_names,na_values = "?", comment='\t',sep=" ", skipinitialspace=True)dataset = raw_dataset.copy() # 复制读取的数据,避免修改元数据
dataset.tail() # 显示表格数据——jupyter自显,pycharm需要print
效果:

对数据进行处理(一)
主要是删除无效值和数据分类操作。
- 数据清洗——首先是无效数据查看:isna()会返回为包含无效值的表单,再追加一个sum()实现计算无效值的和;其次,对无效数据进行处理:dropna()清除无效数据后返回一个新数据表单。
- 将需要的产源地分类序号从表中提取出来,使用pop(‘Origin’)提取Origin列的数据
- 将Origin进行one-hot转换——即Origin不同的值仅对应一个数据有效:
dataset['USA'] = (origin == 1)*1.0dataset['Europe'] = (origin == 2)*1.0dataset['Japan'] = (origin == 3)*1.0——如此,仅当对应的标号时,某一列中的数据才为1,满足one-hot定义:[0,0,1,0,0……1,0],只有有效数据为1,其余为零。
代码:
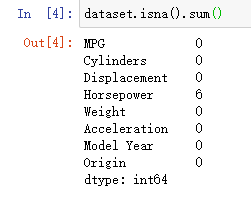
dataset.isna().sum() # 显示无效数据分布情况
效果:
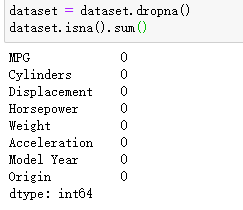
dataset = dataset.dropna() # 移除无效数据
效果:
origin = dataset.pop('Origin') # 获取分类序号——以供one-hot转换需要
效果:

dataset['USA'] = (origin == 1)*1.0
# one-hot转换:只有当列数据中值为1时,才设为1,否则为0,也就相当于一整列数据按 (origin == 1)条件转换为1 or 0dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail() # 显示表格数据
效果:

对数据进行处理(二)
主要是拆分数据集和获取数据状况分析信息。
- 采用sample(frac=0.8,random_state=0)——随机拆分80%的panda的DataFrame数据作为训练集
- 采用drop(train_dataset.index)——移除已经取出的数据下标包含的数据并返回。
- describe()用于观察一系列数据的范围,大小、波动趋势等等。(会存到train_stats)
- 补充说明,描述信息需要pop(‘MPG’)——因为这是我们需要单独处理的数据。
代码:
train_dataset = dataset.sample(frac=0.8,random_state=0) # 拆分获得训练数据
test_dataset = dataset.drop(train_dataset.index) # 拆分获得测试数据
效果:


train_stats = train_dataset.describe() # 获取数据的一系列描述信息
train_stats.pop("MPG") # 移除MPG的数据列
train_stats = train_stats.transpose() # 行列转换——也就是相当于翻转
train_stats # 显示描述信息——jupyter自显
效果:

对数据进行处理(三)
主要是分离训练数据的标签——从获得的数据中。
- 同样采用pop(‘MPG’)——获取指定列的数据
代码:
train_labels = train_dataset.pop('MPG') # 将移除的MPG列数据返回,赋值给train_labels
test_labels = test_dataset.pop('MPG')
train_labels # 显示数据
test_labels
效果:


数据归一化
在这次的数据中,虽然说只是一些简单数据的分析,但是数据归一化,特征归一化还是很有必要的。这样有助于数据收敛,得到更好的训练结果。
采用的计算方式如下:x为需要归一化的数据,train_stats为当前表格的描述信息——通过以下运算就实现了归一化。(0 or 1)
(x - train_stats['mean']) / train_stats['std']
这样获得的归一化数据,应该是被保留下来用与后边的其它运算。
代码:
(采用函数,方便多次调用,避免公式重复导致可读性,降低人为失误)
def norm(x):return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset) # 获取训练数据中的归一化数据
normed_test_data = norm(test_dataset) # 获取测试归一化数据
效果:


模型分析
模型构建
本模型采用线性模型——包含两个紧密相连的隐藏层,以及返回单个、连续值得输出层。
为了代码结构,采用函数式编程:执行模型——网络层结构创建,以及模型编译。
# 第一层Dense的input_shape为输入层大小,前边的64为该全连接层的输出层(隐藏层)——只有最后的全连接层 layers.Dense(1)输出才是输出层,否则为隐藏层。
# activation为激活函数——这里是线性激活
def build_model():model = keras.Sequential([layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),layers.Dense(64, activation='relu'),layers.Dense(1)])optimizer = tf.keras.optimizers.RMSprop(0.001)model.compile(loss='mse',optimizer=optimizer,metrics=['mae', 'mse'])return model
model = build_model() # 创建一个模型
model.summary() # 展示模型结构
效果:

模型检测
采用上边创建好的模型进行预测——查看效果。
example_batch = normed_train_data[:10] # 获取十个数据来预测
example_result = model.predict(example_batch)
example_result
效果:(看起来似乎它已经可以用来直接使用了,但其实这还不够,我们一定记得要进行拟合数据才算是一个完整的学习模型的构建完全。)

数据拟合
在这里添加一个输出点的函数——目的是显示训练的进程(提示:本次训练拟合周期(次数)为1000,你也可以进行更多的尝试)
# 通过为每个完成的时期打印一个点来显示训练进度
class PrintDot(keras.callbacks.Callback):def on_epoch_end(self, epoch, logs):if epoch % 100 == 0: print('')print('.', end='')
EPOCHS = 1000 # 拟合次数# 返回的history为一个对象,内包含loss信息等
history = model.fit(normed_train_data, train_labels,epochs=EPOCHS, validation_split = 0.2, verbose=0,callbacks=[PrintDot()])
拟合fit函数的参数依次为:
- 训练所需的归一化数据,训练数据对应的标签;
- 拟合次数
- validation_split用于在没有提供验正集的时候,按一定比例从训练集中取出一部分作为验证集
- 日志显示配置:verbose = 0 为不在标准输出流输出日志信息
verbose = 1 为输出进度条记录
verbose = 2 为每个epoch输出一行记录
注意: 默认为 1 - callbacks——简单的说就是提供训练中的操作
效果:

训练结果数据展示(建议使用jupyter notebook)
模型日志的查看
hist = pd.DataFrame(history.history) # 返回一个DataFrame对象,包含history的history数据
hist['epoch'] = history.epoch # 末尾添加一列数据包含epoch信息
hist.tail() # 展示表单数据
效果:


模型训练的日志信息-可视化
创建绘图函数
def plot_history(history):hist = pd.DataFrame(history.history)hist['epoch'] = history.epochplt.figure() # 创建新窗口plt.xlabel('Epoch') # x轴标签(名字)plt.ylabel('Mean Abs Error [MPG]') # y轴标签(名字)plt.plot(hist['epoch'], hist['mae'],label='Train Error') # 绘图,label为图例plt.plot(hist['epoch'], hist['val_mae'],label = 'Val Error') # 绘图,label为图例plt.ylim([0,5]) # y轴长度限制plt.legend() # 展示图例plt.figure()plt.xlabel('Epoch')plt.ylabel('Mean Square Error [$MPG^2$]')plt.plot(hist['epoch'], hist['mse'],label='Train Error')plt.plot(hist['epoch'], hist['val_mse'],label = 'Val Error')plt.ylim([0,20])plt.legend()plt.show() # 必须要有show才能显示绘图
可视化展示(发现训练多了反而出问题了——过拟合)
有一个问题:也许你的图形不一样,这可能是数据训练和机器相关。

模型改进
以下模型改进——在jupyter notebook中可以直接进行,而使用pycharm的朋友需要在原来的位置进行替换(early_stop添加在原fit前)
model = build_model() # 重新定义模型# patience 值用来检查改进 epochs 的数量
# 定义callbacks的操作设置,这里采用了每10次fit,进行一次判断是否停下,判断依据是当val_loss不改变甚至降低。
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10) history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])plot_history(history)
效果:(看得出,模型有效准确值稳定在了一定范围后,训练就停止了。)

模型评估
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2) # 返回第一个数据loss为损失值
print("Testing set Mean Abs Error: {:5.2f} MPG".format(mae)) # mae为我们构建网络归回预测的值——即预测的MPG
打印结果:说明MPG稳定在2.00左右

使用完整的测试数据预测(最后阶段可视化)
预测MPG的数据可视化
test_predictions = model.predict(normed_test_data).flatten()
# 预测信息会被flatten()平铺展开后以一维数据返回plt.scatter(test_labels, test_predictions) # 绘制散点图
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100]) # 画一条y = x的直线,方便分析
效果:(MPG数据基本集中于该直线)

误差分布可视化
error = test_predictions - test_labels # test_labels 是原始的MPG值序列,所以相减得到误差。
plt.hist(error, bins = 25) # 画矩形图——bins表示每次绘图的最大矩形数目
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel("Count")
效果:误差主要分布在-2~2之间,0最多。说明训练模型较为合适。

总结
- 常见的回归指标是平均绝对误差(MAE)。
- 均方误差(MSE)是用于回归问题的常见损失函数(分类问题中使用不同的损失函数)。
- 当数字输入数据特征的值存在不同范围时,每个特征应独立缩放到相同范围。(归一化,一般采用one-hot编码形式)
- 早期停止是一种防止过度拟合的有效技术。
这篇入门讲解到这里就全部结束了。也许我的文章写得不是很好,还有点长长的——希望对阅读到这里的你有所帮助。
如果对函数参数,或者函数方法有疑惑,需要解答的,可以评论,我尽量回答。如果有需要,我后边可以补写一篇关于这部分参数和函数的讲解。(因为这篇文章实在有点太长了。)
这篇关于Tensorflow回归入门实践-预测70年代末到80年代初汽车燃油效率的模型(详解,提供数据集)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



