本文主要是介绍【案例篇】DataOps崛起:数据治理需要重建!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 * 福利:关注公众号,后台回复【风扇】,包邮免费领手持风扇!
* 福利:关注公众号,后台回复【风扇】,包邮免费领手持风扇!
来源 | AI前线
作者 | Ryan Gross
译者 | 王强
导读:机器学习时代,以往的数据治理模式已经摇摇欲坠。我们应该重建数据治理,将其发展为一套工程规范来实现数量级的效率提升。
企业明知道自己需要数据治理,但并没有为此付诸任何行动
如今高管们都对数据治理感兴趣,下面这些文章就是证据:
最近 Gartner 的一篇研究发现,组织认为糟糕的数据质量平均每年会带来 1500 万美元的损失。
GDPR 的第一个罚款大单是法国数据管理局对谷歌的 5700 万美元罚金。
Equifax 数据泄露已使公司损失了 14 亿美元(总额还在统计中),而且 泄漏的数据都没有被找到。
但相对应的是,绝大多数数据治理计划都没有付诸实施;Gartner 还将 84% 的公司归到数据治理成熟度较低的分类。尽管几乎所有组织都认识到自己需要数据治理,但许多公司甚至没有启动相应的计划,因为这一术语在管理领域有着很强的负面含义。

现有的数据治理“最佳实践”已千疮百孔
其实,这一领域缺乏进展的原因在于 我们一直在以错误的方式进行数据治理,结果方案一见光就死。Stan Christiaens 在他为福布斯撰写的文章中指出了这一事实,我同意他的观点,过去数据治理失败的主要原因是技术尚未做好准备,并且组织没法激励人们遵循一套流程来弥补技术的不足。但现代数据目录工具就是技术层面的终极答案(尽管它们是朝着正确方向迈出的一步)。
如果答案不是数据目录工具,那又是什么?
数据湖工具的一系列进展(特别是大规模版本化数据的能力)将引发一场变革,让我们可以重新构想数据管理的方式(例如通过文化、架构和流程来改进治理模式,降低风险和成本)。变革完成后,数据治理将更像 DevOps,其中数据管理员、数据科学家和数据工程师紧密合作,在整个数据分析生命周期中共同制定治理策略。早早拥抱这些变革的公司将获得巨大的竞争优势。
这个结论是怎样得出来的呢?我们先来回顾一下软件工程的历史。过去有两项核心技术创新引发了企业流程乃至文化的变革,将编程从一种爱好转变为影响世界的革命。接下来的创新主要是 DevOps 运动,它在云时代也为 IT 基础设施带来了类似的革新。最后,我们来看这些创新将如何在数据治理领域推动类似的流程和文化变革。
背景:源代码控制和编译是怎样塑造软件工程产业的
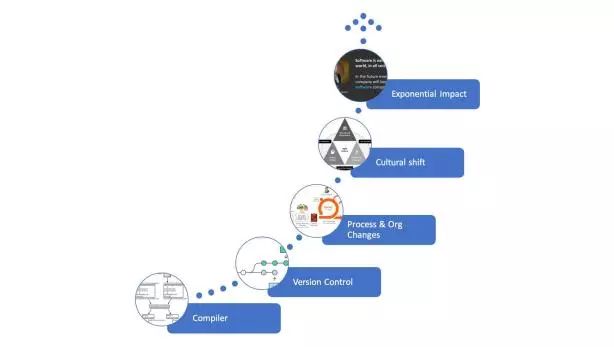
形成软件工程规范的核心创新包括:
将一组输入编译为可执行输出的能力
用于跟踪输入的版本控制系统
20 世纪 60 年代,在这些系统诞生之前的软件开发就是一种手艺,一名开发工匠必须独立建立整个工作体系。而这些创新使软件开发产业迎来了新的组织结构和流程,让编程成为一套工程规范。这并不是说编程艺术没那么重要,只不过它不是本文要谈的主题。
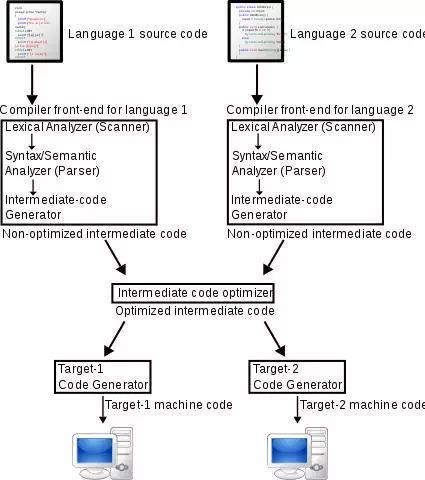
从手艺转向工程的第一步就是引入编译器,从而能够以更高级的语言来编写程序。这使程序变得更容易理解,还可以分解为多个文件,更容易由团队中的多名成员一同编写。此外,随着编译器愈加先进,编译器也可以通过中间代码来为原始代码添加许多自动优化。
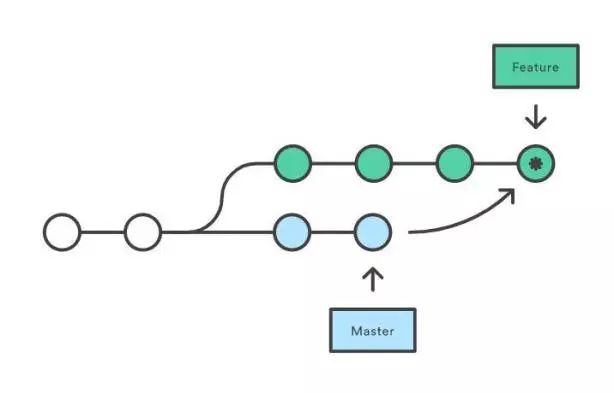
接下来是为生成最终系统的代码所做的所有更改添加统一的版本管理系统,从而让编程艺术逐渐变得“可测量”(就像 Peter Drucker 的名言所说的那样:“无法测量的内容也没法管理“)。从那之后又有了很多渐进式创新,如自动化测试、代码质量的静态分析、重构、持续集成等等,这些创新又定义了许多新的指标。最重要的是,团队可以针对特定版本的代码提交更改并跟踪错误,并对他们所提供软件的特定层面 作出保证。显然,还有许多其他创新为软件开发带来了改进,但那些创新都在某种程度上依赖编译器和版本控制两大源头。
一切皆代码:将软件工程的核心创新应用到所有领域
近年来,这些核心创新正在不断应用于新的领域,这种运动得到了一个称号:一切皆代码。70 年代的软件开发者看到第一个版本的 SVN 的时候肯定满腹狐疑。类似的,一切皆代码运动波及的许多新领域也对此报以怀疑的态度,有些行业甚至声称他们的规范永远不会被简化为几行代码。结果只用了几年时间,那些规范就被完全简化成代码了,并且为“传统”的行为方式带来了一系列改进。
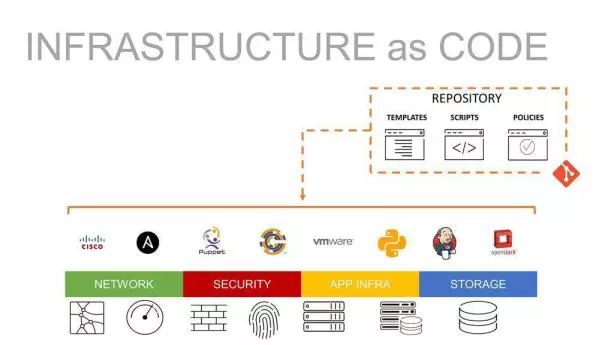
使用虚拟化和配置管理的“编译”层将代码转换为基础架构
这个运动扩张的第一个领域是基础设施管理。在这一案例中,代码指的是一组配置文件和脚本,用于指定跨环境的基础架构配置;编译在云平台内进行,通过云服务 API 读取并执行配置和脚本,从而创建并配置虚拟基础架构 。虽然基础设施即代码运动似乎在一夜之间就席卷了所有基础设施团队,但其实是先有了大量重大创新(虚拟机、软件定义网络、资源管理 API 等),才为“编译”这一步打好了基础。
一开始可能只有 VMWare 和 Chef 等公司的专有解决方案,之后当公有云服务商在他们的平台上免费提供相应的核心功能后,这种方案就得到了广泛普及。在变革之前基础架构团队很难重新创建环境,所以需要 管理 他们的环境以确保一致性和质量。于是团队需要一系列治理层级来在开发过程中控制各个检查点。如今,DevOps 团队会 设计 他们的环境,控件可以构建到“编译器”中。这使得团队部署变更的能力提高了几个数量级,从几个月或几周变为几小时或几分钟。
于是人们就能彻底从头考虑基础设施的改进思路了。团队开始开发从零开始创建系统的各个阶段,使编译、单元测试、分析、设置、部署、功能和负载测试成为一个完全自动化的过程(也就是持续交付)。此外,团队开始测试系统在部署前后是否安全可靠(DevSecOps)。每当一项新组件进入版本控制系统后,该组件的发展轨迹就可以被一系列指标测量了;这样自然就带来了持续改进的能力,因为我们现在可以对提供的环境的特定层面 作出保证 了。
切入重点:这样的故事也会发生在数据治理领域
这一运动将改造的下一个领域就是数据治理 / 数据管理。不好说对应的运动名称应该叫什么(DataOps、数据即代码和 DevDataOps 似乎都有点偏差),但它的影响可能比 DevOps/ 基础设施即代码运动更为深远。
将数据管道用作编译器
“通过机器学习技术,你的数据就能写成代码。”——AWS 机器学习部门主管 Kris Skrinak

机器学习技术的迅速发展为复杂软件的构建提供了一种新的途径(一般是分类或预测事物的软件,但随着时间的推移会扩张到更多领域)。这种将数据视为代码的新思路会是将数据治理转换为工程规范的关键的第一步。换句话说:
“数据管道就是将数据作为源代码的编译器。”
与软件或基础设施使用的编译器相比,这些“数据编译器”有三点不同,也更加复杂:
数据团队既有数据处理代码也有底层数据。但是如果数据就是源代码,那样数据团队都得编写自己的编译器来从数据中构建可执行的程序。
对于数据而言,我们一直通过元数据来手动定义数据结构,因为这有助于编写数据编译器的团队了解每个步骤的操作。但软件和基础设施编译器通常会通过输入形成结构。

我们不明白数据如何变成代码
我们还是不太明白数据是怎么变成代码的。所以要让 数据科学家 做实验来弄清楚编译器的逻辑,然后 数据工程师 来构建优化器。
现有的数据管理技术平台(Collibra、Waterline、Tamr 等)就是为了实现这一工作流程而构建的,并且它们做得非常好。但它们支持的工作流程仍然需要一系列审查会议来为数据治理手动制定规范,这样就很难出现像 DevOps 和基础设施即代码变革那样的一系列进化了。
缺少的桥梁:数据版本控制
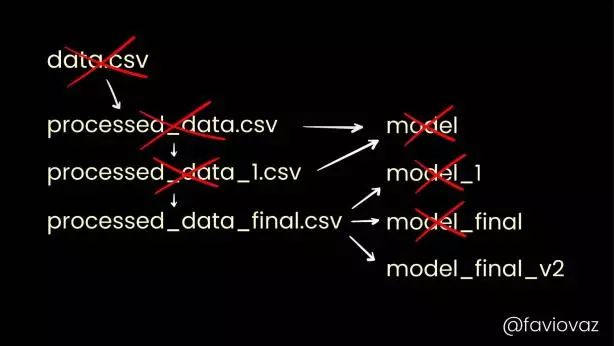
数据版本控制。来源:DVC 项目(https://dvc.org/)
由于数据是“在现实世界中”生成的,而不是由数据团队生成的,因此数据团队专注于控制描述它们的元数据。这就是数据治理(试图管理你无法直接控制的东西)和数据工程(实际上是设计数据编译器而非数据本身)之间的分界线所在。现在数据治理团队正在尝试在很多点上应用手动控制来控制数据的一致性和质量。如果对数据引入版本跟踪功能,数据治理和数据工程团队就能共同 设计 数据、针对各个数据版本提交错误报告、对数据编译器实施质量控制检查等等。这样数据团队就能对从数据中生成的系统组件 作出保证;一旦有了这种保证,历史证明将随之而来的就是数据驱动系统的可靠性和效率飞速提升。
数据版本控制技术已经来到了临界点
像 Palantir Foundry 这样的平台已经开始像开发者处理代码版本一样对待数据管理流程了。在这些平台中,数据集可以通过版本化的代码进行版本化、分支和一系列操作,从而创建新的数据集。这就为数据驱动测试打下了基础,其中测试数据本身的方法与对修改数据的代码做单元测试的方法基本是一样的。当数据以这种方式流过系统时系统会自动跟踪数据的谱系,每个数据管道在各个阶段产生的数据产品也会被这样跟踪。
这些转换步骤都可以被视为编译步骤,其将输入的数据转换为中间代码,最后由机器学习算法将最后一步的中间代码(数据团队通常称之为特征工程数据集)转换为可执行形式以进行预测工作。如果有人手里有 1000 万到 4000 万美元想购买这样一套流程,那么可以考虑一下 Foundry,他们做出来的这套流程令人印象非常深刻。
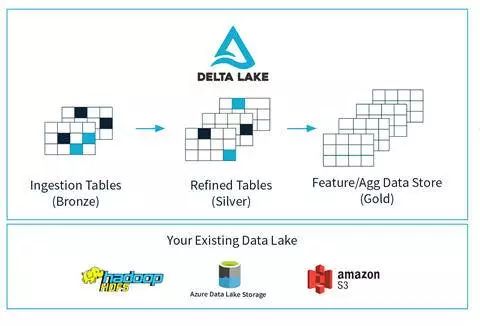 DataBricks Delta Lake 开源项目实现了数据湖的数据版本控制
DataBricks Delta Lake 开源项目实现了数据湖的数据版本控制
其他人手里可能没那么多钱可花,还好现在也有开源的替代品。数据版本控制项目(https://dvc.org/)是一个专为数据科学家用户打造的选择。针对大数据负载,DataBricks 已经向数据湖的完整开源版本控制系统迈出了第一步,并发布了他们的开源 Delta Lake 项目。 这些项目刚诞生不久,因此还没有加入分支、标记、谱系跟踪、错误归档等功能。
下一步就是重建数据治理
版本控制和编译数据的技术诞生后,数据团队开始思考他们的流程该如何利用这些新技术。那些能够积极利用这种能力来作出保证的人们可能会为他们的组织创造巨大的竞争优势。第一步将是取消基于检查点的治理流程,变为让数据治理、数据科学和数据工程团队紧密合作,通过在数据管道中编译成可执行文件来实现数据的持续治理。接下来是将分别由数据与单纯软件编译的组件和基础设施集成为同一个单元;虽然我还没看到实现它的技术出现。随着时间推移,其它创新也将陆续出现,从而改造治理文化,解决许多现有的关键问题,同时加快机器学习技术普及实用的步伐。我知道这听起来像是吹牛,但数据治理真的要迎来激动人心的时代了。
以数据为驱动,云原生DataOps数据中台解决方案
能读到这里,你可能已经对数据治理感兴趣了,所以请在评论区写下你的看法。如果你恰好在寻找企业数据治理以及更多数据驱动的方法,那么现在可以来看看智领云科技这家公司。
武汉智领云科技有限公司成立于2016年8月,专注于云计算、大数据领域前沿技术的研发。公司创始团队成员来自于推特(Twitter)、苹果(Apple)和艺电(EA)等硅谷知名企业,是硅谷最早一批从事云计算和大数据研究与实践的技术专家,拥有十多年的云计算、大数据系统的系统架构和系统开发经验。
公司为企业级客户提供以云原生DataOps为底座的大数据平台数据中台/大数据平台数据中台系统解决方案;帮助企业搭建数据和AI中台实现云原生DataOps,轻松打造业务数据能力闭环,掌握全面、及时、更多维度的业务现状,提升数据驱动应用的迭代和发布速度;实现系统资产(人/资源/数据/应用) 在同一系统中的统一管理,建立数字化运营体系,并最终完成数据驱动的数字化转型。
公司研发的BDOS(大数据操作系统)是业界第一个使用云计算和微服务技术将大数据底层技术架构进行标准化和产品化的整体技术解决方案。BDOS采用云原生Mesos技术作为底层数据中心管理系统,提供BDOS应用云平台和大数据平台两个子系统,为用户提供一个端到端的可直接用于生产环境的的大数据操作系统平台,大大降低了用户在基于云计算技术的基础上开发大数据应用的技术门槛。
以数据为驱动,BDOS为企业提供一站式的云原生DataOps数据中台解决方案,赋能企业用户的数字化运营建设。企业用户借助BDOS提供的数据资产管理系统、数据服务及模型服务管理系统、可视化算法平台等系统可以高效自助地构建企业数据中台,构建企业数字化运营体系,加速实现企业数字化转型。
查看英文原文:
https://towardsdatascience.com/the-rise-of-dataops-from-the-ashes-of-data-governance-da3e0c3ac2c4
- FIN -
文末抽奖
扫码关注公众号
后台回复关键字【风扇】
邀请10位好友领取奖品


更多精彩推荐
一文读懂大数据实时计算
Hudi 实践 | 使用 Apache Hudi 构建下一代数据湖 | 文末福利
【工具篇】41 款实用工具,数据获取、清洗、建模、可视化都有了
从Hadoop到云原生,谈如何消除程序员35岁危机
我们为什么需要云原生?看完这一篇就够了
????更多智领云科技详细内容,点击“阅读原文”
这篇关于【案例篇】DataOps崛起:数据治理需要重建!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






