本文主要是介绍YOLO-Fastest训练自己的数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
YOLO-Fastest训练自己的数据
继续yolo-fastest的学习,上一篇已经基本跑通了yolo-fastest,接下来开始训练,本次代码依旧是:https://github.com/dog-qiuqiu/Yolo-Fastest
吐槽一句,这个代码里面怎么啥都有,感觉好乱啊!刚开始看的时候一脸懵逼,反复确认才明白没下载错代码。
然后作者官方Readme只要简简单单的一两句话介绍训练,估计是要逼死小白!

一、配置环境
1.win10
2.cuda10.2+cudnn
3.opencv451
4.vs2015
5.cmake
二、数据集制作
(1)制作工具
labelImg(这个就不展开说了),标注完成后获得一大堆标注文件(xml格式)。
(2)数据格式转换
上一步中,获得的数据是满足voc数据要求的,但是对于yolo系列,需要做一些处理。
1)新建mydata文件夹,在该文件下继续新建data文件夹,data文件下继续新建Annotations、images、ImageSets(里面再建Main文件夹)、labels。如图
继续新建脚本文件makedata.py文件
import os
import randomtrainval_percent = 0.2 #可自行进行调节
train_percent = 1
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)#ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
#fval = open('ImageSets/Main/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:#ftrainval.write(name)if i in train:ftest.write(name)#else:#fval.write(name)else:ftrain.write(name)#ftrainval.close()
ftrain.close()
#fval.close()
ftest.close()
继续新建脚本voc_label.py,这个脚本文件和data文件夹同级。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import joinsets = ['train', 'test']classes = ['QR'] #自己训练的类别def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('data/Annotations/%s.xml' % (image_id))out_file = open('data/labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
for image_set in sets:if not os.path.exists('data/labels/'):os.makedirs('data/labels/')image_ids = open('data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()list_file = open('data/%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write('data/images/%s.jpg\n' % (image_id))convert_annotation(image_id)list_file.close()
注意:1.修改一下自己的训练类别,我的只有一个类别QR
2.倒数第三行,图像格式需要对应
依次运行上面两个脚本,既可获得满足yolo的数据格式。

第一个数值是类别编号,后面四个值分别是左上点和右下点的归一化后的坐标。
三、yolo-fastest准备工作
(1).复制数据集
将上面获得的data文件夹直接复制到Yolo-Fastest-master\build\darknet\x64文件下。
(2).修改配置文件
在Yolo-Fastest-master\build\darknet\x64\cfg文件夹下找到yolo-fastest-1.1.cfg(也可以是其他的,后面对应修改就行)。
1.修改batch和subdivisions参数。
[net]
batch=16
subdivisions=8
width=320
height=320
channels=3
2.filters参数,只需要修改两处的,千万别全改了!
########修改858行和926行
########filters=(cls_num+5)*3
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
(3).新建.data和.names文件。
在Yolo-Fastest-master\build\darknet\x64\data文件夹中新建data和names文件。
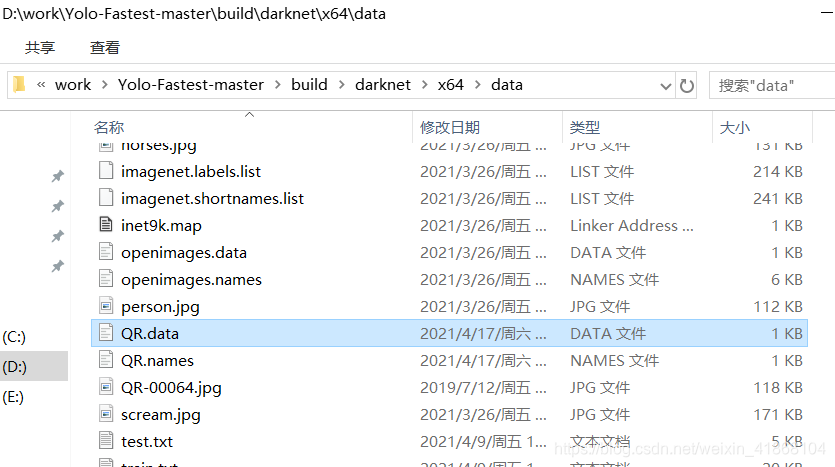
我的是QR.data和QR.names。data文件如下
classes= 1
train = data/train.txt
valid = data/test.txt
#valid = data/coco_val_5k.list
names = data/QR.names
backup = backup/
只要找到你的train.txt和test.txt文件就行。这两个txt文件实际上也是图像的引索路径。
names文件里面换成自己的类别就行
四、训练yolo-fastest
(1)生成预训练模型
Yolo-Fastest-master\build\darknet\x64文件夹下新建pretrained_model文件夹,之后在该文件夹下会生成预训练模型。新建一个QR.bat文件,写入如下指令后双击既可(话说这样子运行指令感觉还不错)
darknet partial cfg\yolo-fastest-1.1.cfg cfg\yolo-fastest-1.1.weights pretrained_model\yolo-fastest-1.1.conv.109 109
pause
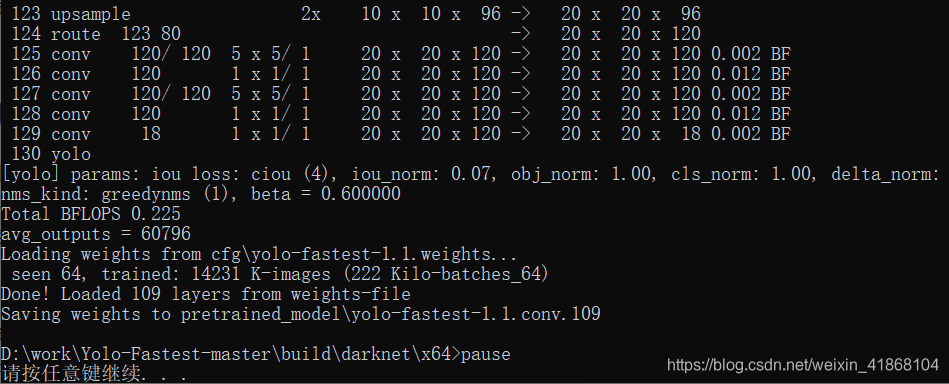
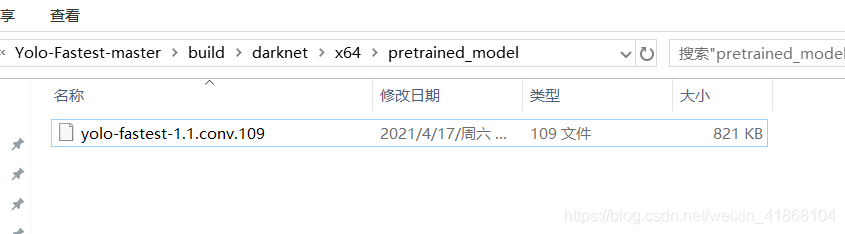
会在上述文件夹生成预训练权重文件(这文件真的是太小了,简直amazing)
(2)正式训练
继续在Yolo-Fastest-master\build\darknet\x64文件夹下新建QRtrain.bat文件,并写入
darknet detector train data\QR.data cfg\yolo-fastest-1.1.cfg pretrained_model\yolo-fastest-1.1.conv.109 backup\
pause双击QRtrain.bat既可开始训练,如图
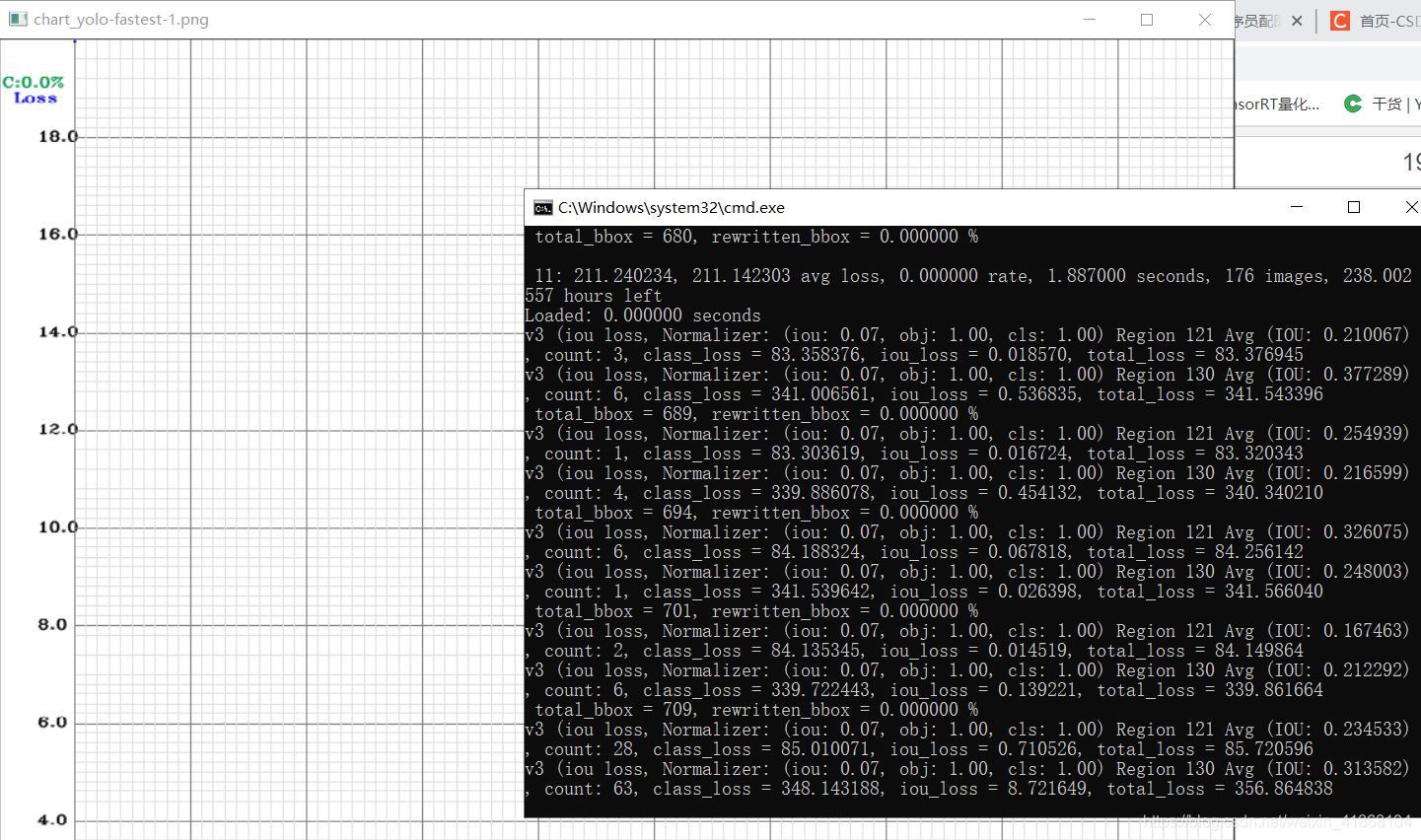
多说一句,旁边那个记录loss的图像,只有loss下降到了18后才会有数值,但是刚开始loss值很大,不会有动静,不要以为是模型有问题,等着loss下降既可。在backup中会生成权重文件。
接下来测试一下
darknet.exe detector test ./data/QR.data ./cfg/yolo-fastest-1.1.cfg ./backup/yolo-fastest-1_last.weights ./data/QR-00064.jpg

效果有点不好说,但是据说移动端会很快,所以接下来继续想着部署了。

看完了点个赞呗!
这篇关于YOLO-Fastest训练自己的数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




