本文主要是介绍Python批量下载ERA5数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. ERA5数据简介
ERA5是第五代ECMWF大气再分析全球气候数据(ECMWF),该数据集的第一部分现在可以公开使用(1979年到3个月内)。ERA5数据提供每小时的大气、陆地和海洋气候变量的估计值,地球数据精确到了30km网格,包括了137层的大气数据。
网址:ERA-5
2. 下载数据的准备工作
(1) 注册CDS账号
可使用邮箱直接注册,注册网址如下:https://cds.climate.copernicus.eu/user/register?destination=%2F%23!%2Fhome
注册完后查看自己的邮箱,会给个链接设置密码。
(2) 获取API key
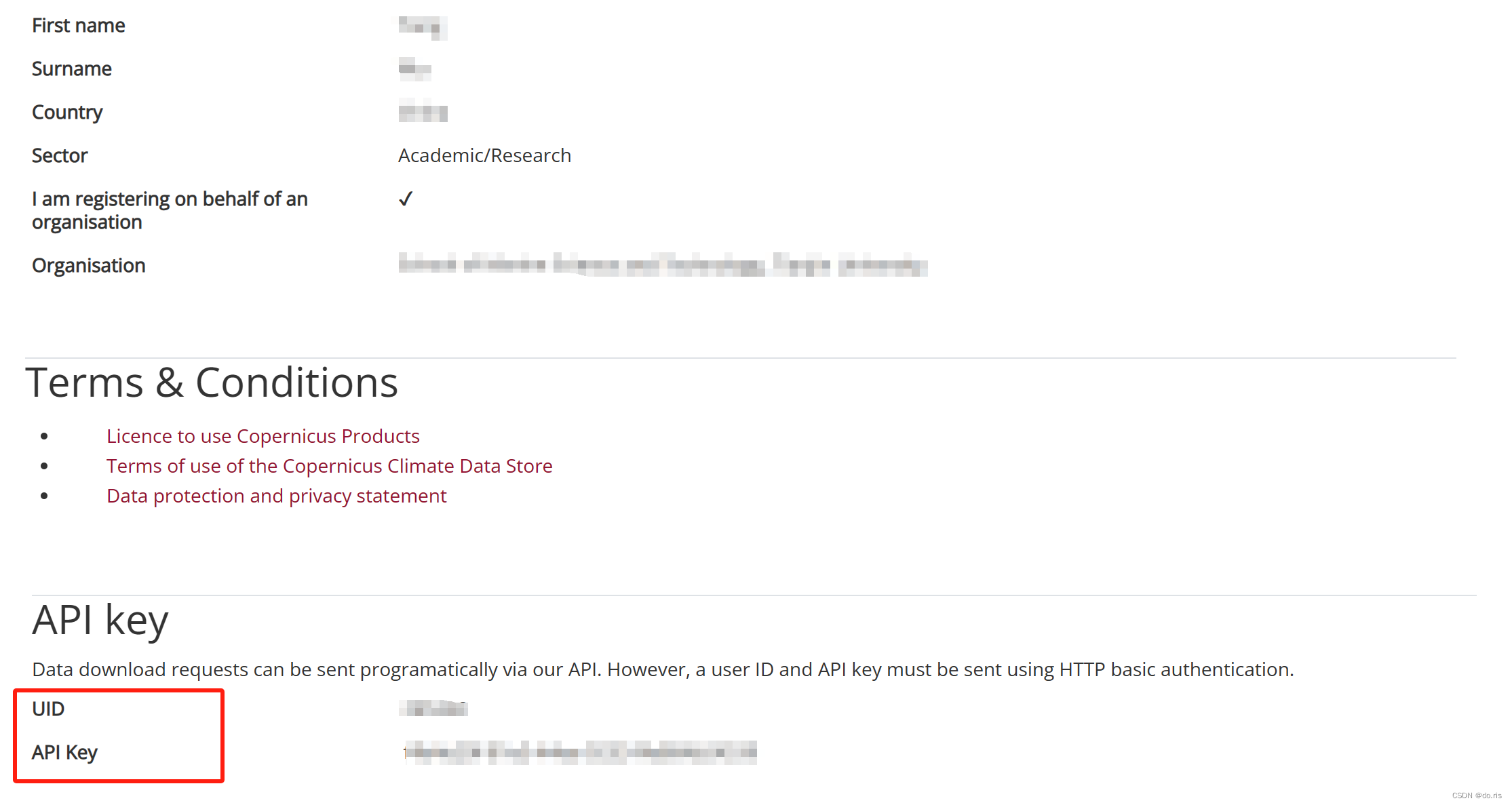
- 注册完成后,进行登录,点击右上角的用户,查看用户信息,找到下图框出的API key:
(3) 创建".cdsapirc"文件
- 在路径 “C:\Users\用户名” 底下创建 “.cdsapirc” 文件(打开文本文档,输入下面内容后,另存为,选择文件类型-”所有文件“,文件名: “.cdsapirc”),在 “.cdsapirc” 文件输入的内容如下:
url: https://cds.climate.copernicus.eu/api/v2
key: UID:API Key
其中UID替换为上图红框给出的UID的数字,API key也替换为红框框住部分的数字。
(4) 安装cdsapi第三方库
pip install cdsapi

3. 批量下载
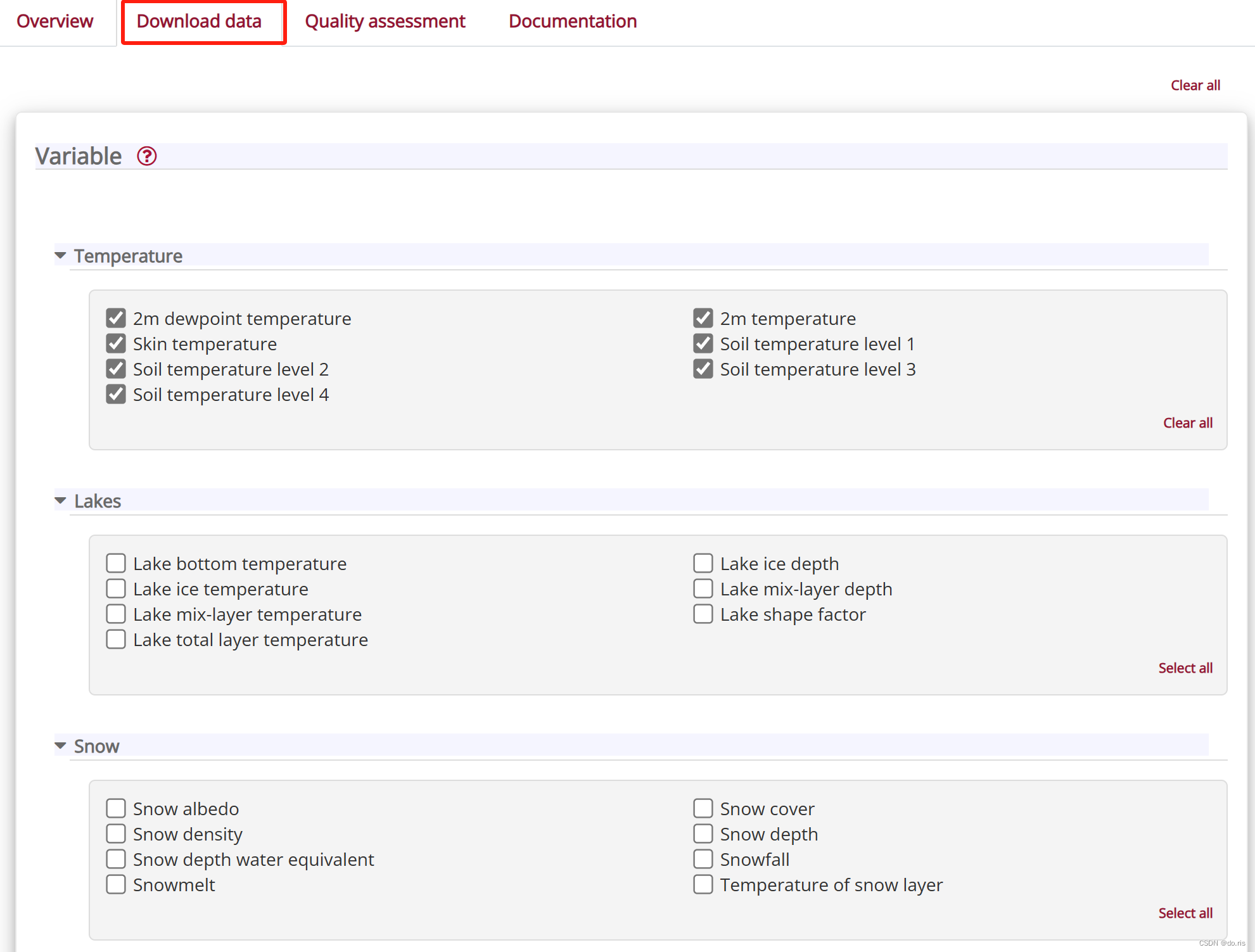
以下载ERA5-Land hourly data from 1950 to present中的数据举例:
- 选择自己需要的数据、年份、月份、天、时间、以及空间位置
- 然后下滑到最后,点击“Show API request” 选项,得到下面所示的图,其中“Terms of use”是一些条例,得先点击同意,才能下载。
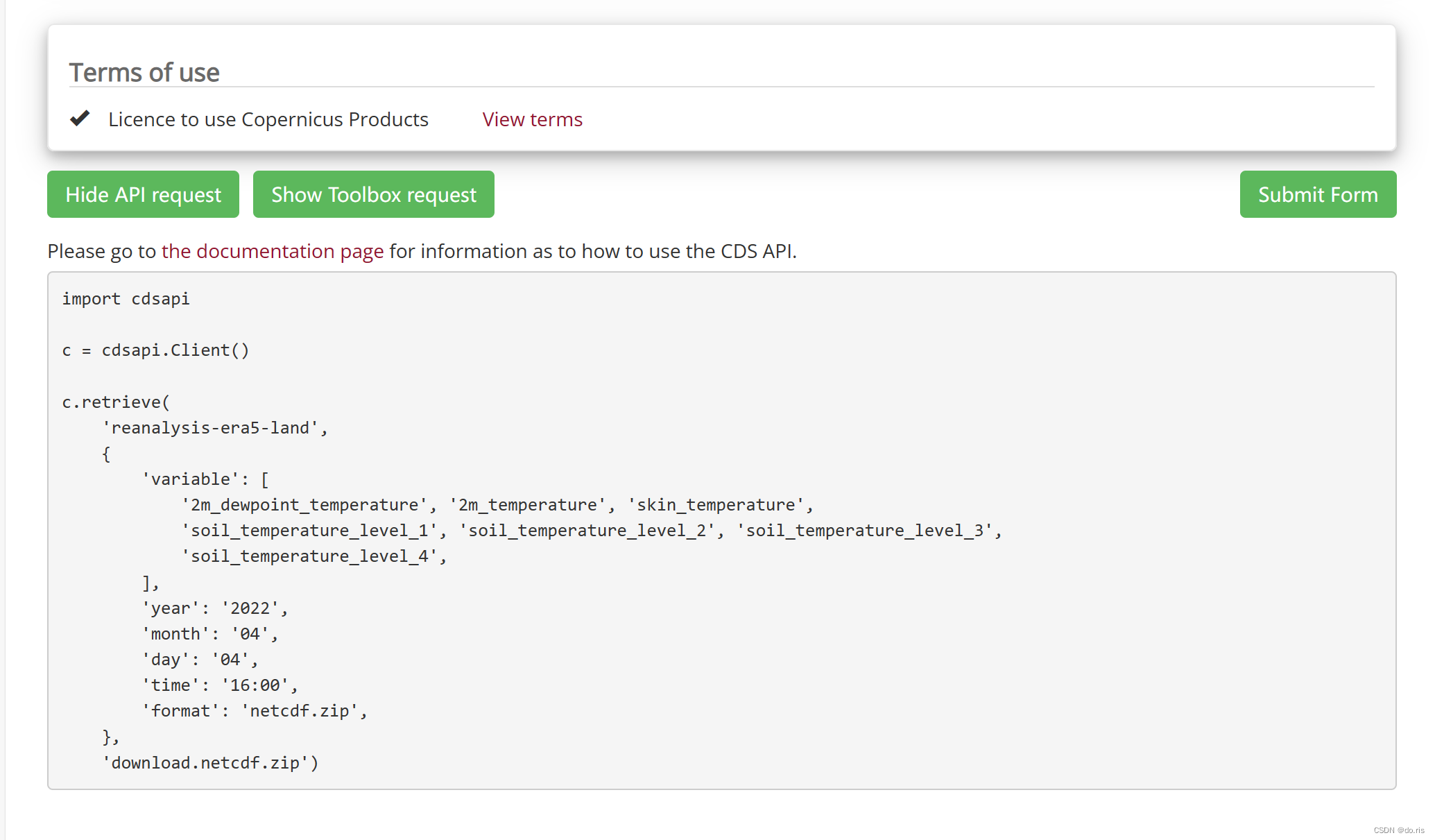
- 将上述代码复制到一个.py文件下,然后Python运行,即可下载再分析数据。
4. 批量下载数据
- 例如,要下载 “ERA5 hourly data on single levels from 1979 to present” 数据集中1979年到2020年每个月的全球2 m温度再分析数据,并保存为nc文件。
import cdsapi
import calendarc = cdsapi.Client() # 创建用户# 数据信息字典
dic = {'product_type': 'reanalysis', # 产品类型'format': 'netcdf', # 数据格式'variable': '2m_temperature', # 变量名称'year': '', # 年,设为空'month': '', # 月,设为空'day': [], # 日,设为空'time': [ # 小时'00:00', '01:00', '02:00', '03:00', '04:00', '05:00','06:00', '07:00', '08:00', '09:00', '10:00', '11:00','12:00', '13:00', '14:00', '15:00', '16:00', '17:00','18:00', '19:00', '20:00', '21:00', '22:00', '23:00']
}# 通过循环批量下载1979年到2020年所有月份数据
for y in range(1979, 2021): # 遍历年for m in range(1, 13): # 遍历月day_num = calendar.monthrange(y, m)[1] # 根据年月,获取当月日数# 将年、月、日更新至字典中dic['year'] = str(y)dic['month'] = str(m).zfill(2)dic['day'] = [str(d).zfill(2) for d in range(1, day_num + 1)]filename = 'E:\\Data\\ERA5\\1979-2020\\2m_temperature\\' + str(y) + str(m).zfill(2) + '.nc' # 文件存储路径c.retrieve('reanalysis-era5-single-levels', dic, filename) # 下载数据5. 可使用IDM加速下载
详情请参考:https://blog.csdn.net/qq_39373443/article/details/118086241
这篇关于Python批量下载ERA5数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






