本文主要是介绍精选 | 认清纷繁世界的 10 大数据法则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我用数据分析思维来深度解读《拼凑真相》这本书,副标题是:认清纷繁世界的 10 大数据法则,作者是英国的蒂姆·哈福德。

在目不暇接的数据海洋中,如何看清纷繁世界的真相?
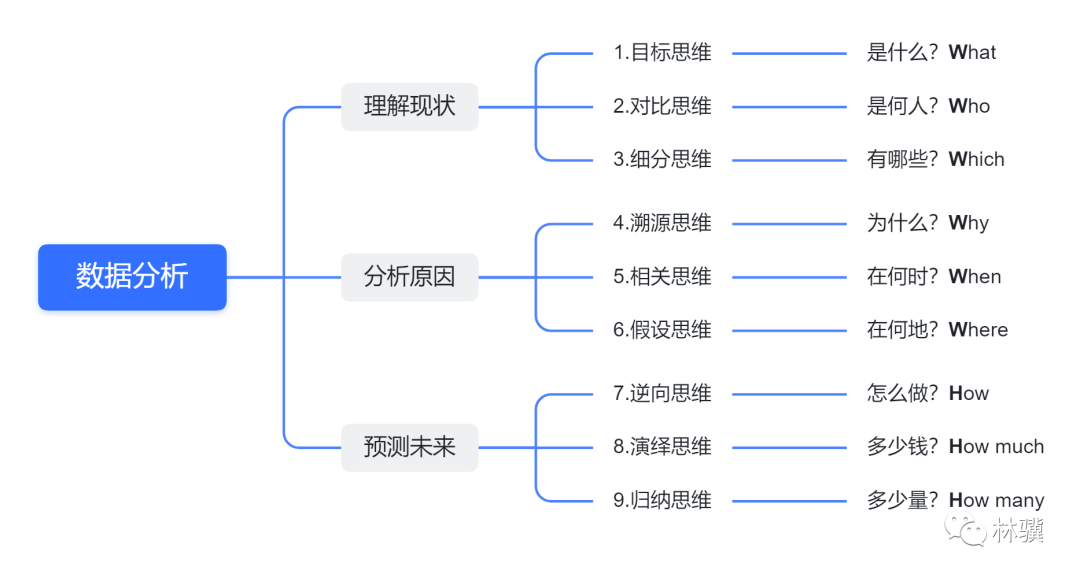
我们不妨运用数据分析的 9 种思维,来学习书中介绍的 10 大数据法则(顺序有调整),以便提升洞察事物本质的能力。
 理解现状
理解现状
 1.目标思维
1.目标思维
数据分析的目标,是为了能够更好地理解和应用数据,从数据中挖掘出可靠的信息,学到对工作和生活有用的知识,从而能够做出更加明智的决策,获得洞察真相的智慧。
法则一:不乱于心,不困于情
当你看到一个数据的时候,第一反应是什么?
点赞?驳斥?或者忽略?
此时,你不妨先停下来,观察一下自己的情绪反应,想一想:我内心真正的目标是什么?为什么会产生这样的情绪?
目标会影响一个人思考的方向,而情绪会影响一个人决策的质量。情绪越激动,就越难理性地思考问题。
所以,在解读数据的时候,专业知识和技术固然重要。但是如果目标不明确,就像出发没有目的地,就容易迷失方向;如果不控制好自己的情绪,就会像野马没有缰绳,容易马失前蹄。
 2.对比思维
2.对比思维
虽然统计数据会撒谎,但是,与没有统计数据相比,撒谎会更容易。
更为重要的是,如果没有统计数据,我们就更不可能了解世界的真相,就像没有显微镜,我们看不到细菌,没有望远镜,我们无法探索遥远的星空。
法则二:对标个人经验
如果没有统计数据,我们的认知很有可能会出现偏差,恐怕连知道真相的机会都没有。
然而,人们很容易被表面的数据蒙蔽了双眼,自以为看到的是真相,但事实往往并非如此。
我们也许只看到了冰山一角,水面上看见的部分远远小于水下的部分,所以要格外小心,以免撞到冰山而倾覆。
在看完数据之后,要带着好奇心,去探索和感受真实的世界。一旦我们看清了世界的真相,也就能更好地理解数据背后的信息。
从鸟瞰视角看到的数据枯燥乏味,但更加全面;而蠕虫视角看到的数据鲜活有趣,但较为片面。
我们要把鸟瞰视角与蠕虫视角、宏观数据与个人经验有机地结合起来,二者相辅相成,相互纠偏,才能更好地洞察事物的本质。
法则九:不要被漂亮的信息图迷了眼
南丁格尔的故事至今仍广为流传,因为她巧妙地使用了「玫瑰图」,通过对比分析,向人们灌输了正确的观点。
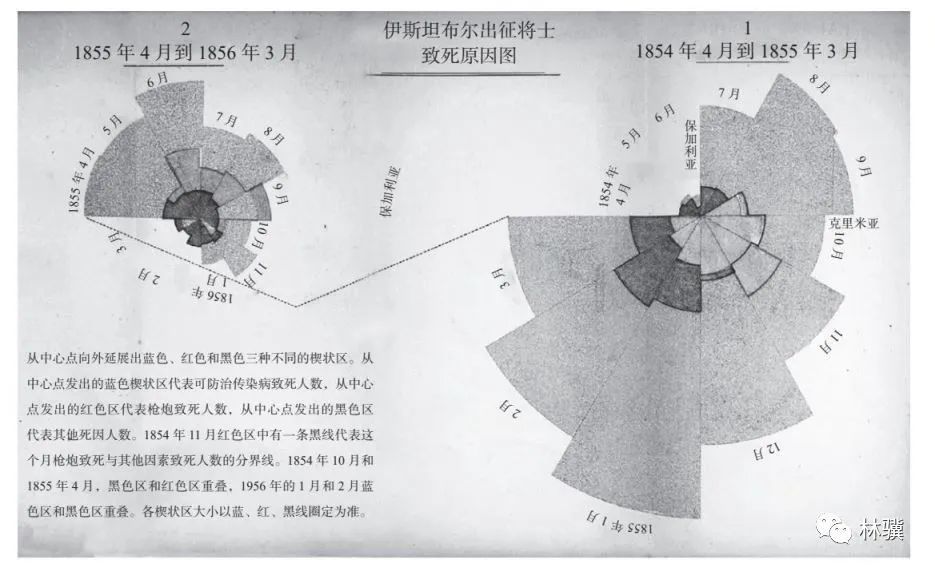
(图片来源:美国国家医学图书馆)
但是,许多滥用信息图的人,可能正在做着相反的事,做出了一些美丽的图表,却反而让人越看越糊涂。
当你看到一张漂亮的信息图表时,要知道是有人在输出观点,不要被漂亮的外观迷了眼。
当然,如果图表说的内容确实有道理,我们也不要故步自封,而要以图为镜,矫正自己的错误认知。
制作图表是为了传递有效的信息,可以动之以情,也可以晓之以理,但不能混淆视听,更不能颠倒是非。
 分析原因
分析原因
 3.细分思维
3.细分思维
唐朝诗人王之涣在《登鹳雀楼》中说:
白日依山尽,黄河入海流。
欲穷千里目,更上一层楼。
大致意思是:夕阳依着山峦慢慢落下,黄河之水朝着大海奔流而去。要想看到千里之外的风景,那就要登上更高的楼层。
看风景是这样,看数据就更是如此。
比如,分析一家具体公司的价值,既要运用细分思维,对数据的细节进行分析,也要运用 PEST 等模型,对它所处的宏观环境进行分析。
法则四:从宏观层面看数据
拉开距离看数据,才能让你有更加宏观的感受。当你把数据放到应有的背景中去看,从宏观层面去观察的时候,才能更好地理解数据的真实含义。
比如,一个国家的基尼系数为 0.3,这个数字大吗?
根据黄金分割律,基尼系数的「警戒线」是 0.382(等于 1 - 0.618),当基尼系数大于 0.382 时,就代表收入分配差距较大,社会收入不平等。
从宏观层面来看,影响基尼系数的因素有很多,包括经济发展水平、政治经济制度,等等。
如果政策制定者希望刺激经济的活力,就有可能制定一些激励政策,让一部分人先富起来,导致基尼系数变大。
如果政策制定者注重薪酬保障,希望先富带动后富,促进社会稳定,最终走向共同富裕,那么就会让基尼系数变小。
我们只有不断拉开距离,才能高瞻远瞩,也才能改变关注的焦点。
《高屋建瓴》的作者安德鲁·埃利奥特在书中建议说:我们想问题时,应该在头脑中带上几个“标尺性数字”,以便比较。
比如,一张床的长度大约 2 米,地球的周长大约 4 万公里。也就是说,从太空的视角来看,大约用 2000 万张床,可以绕地球一圈。
 4.溯源思维
4.溯源思维
苏轼在《题西林壁》中说:
横看成岭侧成峰,远近高低各不同。
不识庐山真面目,只缘身在此山中。
大致意思是:我们所处的位置不同,看到的景物也各不相同。当你身在庐山之中,看到的就只是局部而已,因此容易出现「当局者迷」的现象。
游山所见是这样,观察世界上的很多事物也是如此。
法则三:看清数据是如何定义的
一旦你看清了数据是如何定义的,那么技术反而是相对比较简单的事情。
但是,如果你没有看清数据是如何定义的,那么就难以看出所以然。
因为只有方向对了,技术才能更好地发挥作用。
可悲的事情在于,如果一开始数据的定义就不对,犯了方向性的错误,那么无论技术如何高深莫测,都无法得出正确的答案。
当你看到一个数据时,不妨思考一下:自己能否理解数据的内涵和外延?
世界是错综复杂的,我们不要指望看一个统计数据,就能给出一个非黑即白的结论。
只有当我们怀着一颗追根溯源的心,开始学会提问,在正确的方向上不断追问「为什么」,才找到世界的真相。
 5.相关思维
5.相关思维
法则六:查看统计样本是否覆盖全面
如果统计样本不能代表整体,那么算法再怎么先进,得出的结论也是跑偏的。
比如,某项实验只针对男性有效,但研究人员并没有说明这一点。
要是把女性也包含进来,是否还能得出有效的结论呢?让人意外的是,药效因男女性别不同而不同的现象很普遍。
我们对待统计样本,一定要谨慎,不妨多问一问自己:数据中少了谁?漏了什么没有?
只有把相关的要素都考虑进来,得出的结论才会更加可靠。
相关性不等于因果关系,对于相关数据,我们不可轻信,但也不能拒绝相信一切。
人们往往选择性地相信自己愿意相信的东西,对自己好的就信,对自己坏的就不信。比如,有些人相信喜鹊能带来好运,却不相信吸烟有害健康。
 6.假设思维
6.假设思维
法则五:看看硬币的另一面
假如有 1024 个人分别做抛硬币实验,每个人一次性抛出 10 个硬币,其中有一个人抛出了 10 个都是正面朝上的结果,从数学概率上来看,这是完全有可能的。
类似地,假设一个人做了 1024 次抛硬币实验,每次同时抛出 10 个硬币,其中有一次是 10 个都正面朝上,但他只展示这 1 次实验的结果,让人误以为他有什么魔法,却隐藏了另外 1023 次实验的结果。
当然,还存在一种可能性,就是看看硬币的另一面,其实也是正面。
中国古代有一个带兵打仗的将军,他为了鼓舞士气,铸造一批正反面都是相同的硬币,在出征之前表演给士兵看,让士兵们以为这是天意。
类似这样的故事还有很多,这也提醒我们,一定要注意看看:在硬币的另一面,是否还有其他的故事?
不要被成功者的故事带偏了,因为我们看到的东西,并不能代表真实的世界,它们很有可能是被过滤的、有偏差的东西。
老子在《道德经》中说:道可道,非常道。对这句话有一种理解:对于违反常识的现象,需要小心求证,用非常的手段来证明。
 预测未来
预测未来
 7.逆向思维
7.逆向思维
法则七:要求用算法统计透明
大数据正在改变我们周围的世界,人工智能变得越来越聪明,比如 AlphaGo 在围棋方面已经能够碾压人类,背后的算法就像一个神秘的黑匣子,让人难以看透。
在《大数据时代》出版后,很多人以为只要知道相关关系就够了。
但是,反过来想一想,也有很多人并不看好,因为如果大数据使用不当,反而可能让人深受其害。比如,凯西·奥尼尔在《算法霸权:数学杀伤性武器的威胁与不公》中告诉我们:大数据加剧不平等,威胁民主。
两本书看大数据的视角不同,得出的结论也不同。《大数据时代》看到人们怎么利用数据,而《算法霸权》则看到人们怎么被数据利用。这就好比一把锤子,对木匠来说,它是有用的工具,但对于钉子来说,它就是敌人。
大数据刚开始流行的时候,人们以为自己是木匠,觉得可以利用大数据。但是,后来逐渐有人意识到,自己其实是颗钉子,不断为算法提供数据,逃不出大数据的掌控。就像有些人看算法推荐的短视频,结果一发不可收拾。
大家都想成为算法的主人,但有些人会禁不住诱惑,结果反而成为算法的奴隶。
我们不能盲目地信奉大数据和人工智能算法,如果算法不具有透明性,那么信任度就要打折扣。
 8.演绎思维
8.演绎思维
法则八:统计数据来之不易
当统计的数据越具有代表性,就越能反映实际情况,也就越能赢得人们的信任。
尽管官方统计局的数据可能存在种种问题和缺点,但这些数据来之不易。如果它们辜负了人们的信任,就会受到人们的鞭挞。
统计人员应该有捍卫数据真实性的职业操守,也有捍卫数据公信力的责任。
对于使用统计数据的人来说,无论是出于个人目的,还是以监督为目的,通常都会从权威的机构提供的数据开始,比如国家统计局。
但作为相对独立的统计机构,他们有义务让民众看到数据的真相。统计数据的价值,在于让人可以利用统计数据,更加高效地做出正确的决策。
 9.归纳思维
9.归纳思维
法则十:适时而变,识势而变
数据的收集和分析,是为了帮助我们了解世界的真相。在科学实验中,先收集数据,再摸索寻找规律,然后构建一个假设模型,这种做法本身没有错。
但是此后,你必须重新获得新的数据,来小心检验这个假设。有些人经常搞错了方向,不是因为没有数据,而是因为拒绝接受数据呈现出来的结果。
对许多人来说,拒绝接受数据结果的原因,是因为他们拒绝承认世界已经变了,时代已经不同了,而他们却还在原地打转。
关于收集什么数据,以及如何分析这些数据,每做一个决定,都类似于站在迷宫里的一个分岔路口,选择一条路,很快就会产生连锁反应,引发后面无数种不同的可能。做一组选择,你会得出一个结论;做另一组选择,未见得不合理,但你可能会得到完全相反的结果。
所以,始终保持开放的心态,带着一颗好奇心,审时度势,与时俱进,对未来的趋势做出适当的预判,不拘泥于单一的方法,不墨守成规,虚心接受不同的意见,不断根据事实矫正自己的错误,有错就改,这是提升认知水平的黄金法则。
以上 10 条数据法则,与其说是戒律,不如说是经验法则,或者说是作者从经验教训中养成的思维习惯。
当你看到对自己很重要的数据时,不妨用这些方法去实践尝试一下。
如果你觉得这 10 条法则太多了,那么就记住这一条:保持好奇心。
因为好奇心可以帮助你突破局限,找到数据背后的真相。
请你睁大好奇的眼睛,按「数」索骥,直到你能够熟练地问出数据分析的 9 个经典问题,并运用数据分析的 9 种思维,那么就能更好地理解现状、分析原因和预测未来。
请你勇敢地拿起数据分析的「显微镜」和「望远镜」,仔细观察周围的世界,理解数据背后的逻辑,穿越逻辑错误、情感因素和认知偏见的障碍,最终到达真相的彼岸,你会惊讶地发现,原来世界是如此清晰。
- END -这篇关于精选 | 认清纷繁世界的 10 大数据法则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





