本文主要是介绍HRBU_20211119训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
HRBU_20211119训练
E - Justifying the Conjecture
题意
判断一个数是否有一个素数和一个合数组成
思路
当n<=5时,不符合要求,当n>5时,当n是奇数时,是3和n-3,当n是偶数时,是 n-2.
代码
#include<stdio.h>
#include<iostream>
using namespace std;
int main()
{int t;cin>>t;while(t--){int n;cin>>n;if(n<=5)puts("-1");else{if(n&1)cout<<"3 "<<n-3<<endl;elsecout<<"2 "<<n-2<<endl;}}
}
F - Keeping Rabbits
题意
已知有n只兔子,一段时间后兔子后长肉,是按照一开始的体重的权重来求后来的兔子的权重
思路
遍历每只兔子加上相应权重的体重求得答案。
AC代码
#include<stdio.h>
#include<iostream>
using namespace std;
double a[2000010];
int main()
{int t;scanf("%d",&t);while(t--){int n,k;double sum=0;scanf("%d %d",&n,&k);for(int i=1;i<=n;i++){scanf("%lf",&a[i]);sum+=a[i];}double temp=(double) k/sum;for(int i=1;i<=n;i++){double ans=a[i]+a[i]*temp;printf("%.6lf ",ans);}puts("");}
}B - Fixing Banners
题意
从六个字符串各取出一个字母,判断是否能组成’‘harbin’’,若能输出YES,否则输出NO
思路
在数组中记录每个字母的大小,利用全排列
代码
#include<stdio.h>
#include<iostream>
#include<string.h>
#include<algorithm>
using namespace std;
bool num[10][28];
int a[10];
string c="0harbin";
char str[2000010];
void solve()
{for(int i=1;i<=6;i++){a[i]=i;for(int j=1;j<=28;j++){// scanf("%s",&str);num[i][j]=false;}}for(int i=1;i<=6;i++){scanf("%s",str+1);int len=strlen(str+1);for(int j=1;j<=len;j++){num[i][str[j]-'a'+1]=true;}}do{bool flag=true;for(int i=1;i<=6;i++){if(num[a[i]][c[i]-'a'+1]==false){flag=false;break;}}if(flag){puts("Yes");return ;}}while(next_permutation(a+1,a+7));puts("No");}
int main()
{int t;scanf("%d",&t);while(t--){solve();}}
D - Interesting Permutation
题意
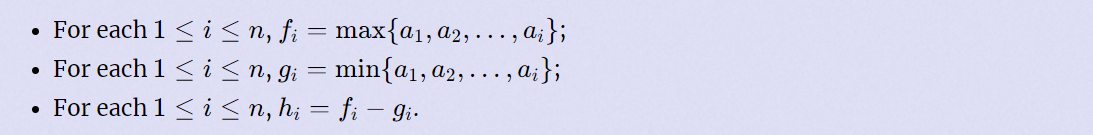
给定h,问有多少组合法的数组
思路
首先数组的开始是0,第二,数组的最后一个的数n-1,第三数组是递增数列,当h[i]>h[i-1]时,ans=ans2%mod,否则ans=anscnt%mod
代码
#include<bits/stdc++.h> using namespace std;
typedef long long ll;
const int mod=1e9+7;
int h[100010];
void solve(){int n;scanf("%d",&n);for(int i=1;i<=n;i++){scanf("%d",&h[i]);}if(n==1){if(h[1]==0){puts("1");}else{puts("0");}return;}if(h[1]!=0||h[n]!=n-1){puts("0");return;}if(h[2]==0){puts("0");return;}for(int i=2;i<=n;i++){if(h[i]<h[i-1]){puts("0");return;}}ll ans=1;ll cnt=0;for(int i=2;i<=n;i++){if(h[i]>h[i-1]){ans=ans*2%mod;cnt+=(h[i]-h[i-1]-1);}else{ans=ans*cnt%mod;cnt--;}}printf("%lld\n",(ans+mod)%mod);
}int main(){int t;scanf("%d",&t);while(t--){solve();}return 0;
}总结
加油,一切可期
这篇关于HRBU_20211119训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








