本文主要是介绍从学术角度论Uber的人工智能预测醉酒专利,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

【数据猿导读】Uber这套预测醉酒的人工智能专利模型,其架构包括所需求的数据、算法和结果,数据方面主要包括用户请求数据、用户当前活动数据、用户特征数据、行程特征等数据
作者 | 傅志华
官网 | www.datayuan.cn
微信公众号ID | datayuancn
近日公布的美国专利申请记录显示,Uber(优步,类似滴滴打车)申请了一个非常有意思的专利,即用人工智能来识别醉酒乘客。Uber 申请的这项专利名为“Predicting User State Using Machine Learning”,即“以机器学习预测用户状态”,由 Uber 的信任和安全团队提交。在专利描述中,Uber称他们将研发一个协调系统,该系统使用关于过去在Uber上的行程和行为数据来训练计算机预测提交行程请求的用户的状态(原文提到:The system uses the data about past trips to train a computer model to predict a user state of a user submitting a trip request)。
简单来说,Uber会根据用户使用 Uber App 的方式来识别异常行为,预测用户是否处于醉酒(不清醒)状态。比如,假设周末的凌晨 1 点,你站在酒吧街区域打车,输入目的地时缓慢且多次出错,跟平常工作日的雷厉风行完全不一样,那么系统将可以判定你处于不清醒状态。

当Uber的这套系统识别出“不清醒状态”,这个系统将因此调整 Uber 所提供的服务。比如为这些用户安排经过培训、有相关经验的司机,并提前告知司机乘客的状态。另外,还可以将上下车地点改在光线较足的地方,并关闭拼车功能保证安全等。而Uber在专利描述中称,希望通过这个系统,可以减少人身安全或嘴角、冲突等让人不快的乘车体验。但这个模型如果使用不当,也会产生负面的影响,其中一个担心是人工智能可能会被部分居心叵测的司机所利用。
数据显示,过去 4 年里在美国至少有 103 名 Uber 司机被指控对乘客进行性侵犯,其中不少受害者就是在醉酒情况下乘车的。目前,这项专利还未投入使用。
本文不打算从伦理道德来分析这个专利的影响,毕竟这个专利还没有正式投入使用,本文只是从学术角度来研究模型实现的原理。下图是整个模型的架构,包括所需求的数据、算法和结果。
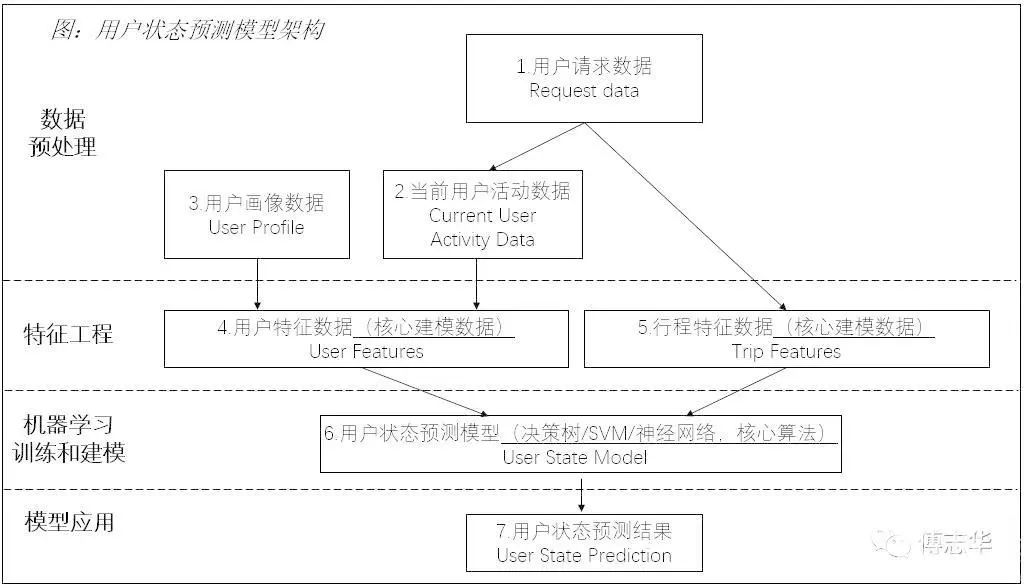
模型整体的架构如下:当用户输入信息将乘坐请求(Request data,图中1)生成到用户设备(即手机)中时,系统同时收集关于用户设备上的用户活动的信息(Current User Activity Data,图中2),系统同时同步已经自动生成好的用户画像数据(User Profile,图中3)。基础数据准好了以后,并进入特征工程模块,即系统会基于数据用户画像数据(图中3)和当前用户活动数据(图中2)构建用户特征数据(图中4),同时实时收集行程特征数据(Trip Features,图中5)。用户特征数据和行程特征数据是特征工程中重要的两类模型输入(Input)。
我们重点分析重要的数据源:
1、“用户请求数据”和“用户当前活动数据”。“用户请求数据”是指用户在uber的个中使用请求数据,这些数据生成“用户当前活动数据”。“用户当前活动数据”指用户对手机用户设备的输入,以及用户设备本身的移动行为。用户当前活动数据可以包括设备处理特性、接口交互特性和文本输入特性数据。这些数据可能会通过手机中的运动传感器、设备角度传感器、GPS和内置在屏幕中的触摸传感器等方式来收集。如设备处理特性数据,包括用户在请求提交时或接近该请求时的速度、用户在请求时保持用户设备的角度、设备移动速度。文本输入特性数据如用户输入文本的准确性、选择搜索结果之前被删除的字符数等行为数据。接口交互特性数据如在生成uber行程单请求时,用户可以与多个用户界面交互,例如设置行程的起始点位置、选择行程的设置、输入搜索字符串以确定行程的目的地等等;系统会采集用户与这些接口交互的速度(例如,在特定输入屏幕上的平均时间、交互之间的时间),以及用户与搜索查询接口的交互速度。
2、“用户特征数据”,通过统计和分析“用户画像数据”和“当前用户活动数据”而得来。“用户特征数据”是特征工程的一个重要部分,目标是构建更有预测能力的变量。比如文本输入速度以及文本输入速度的变化率、用户平均步行速度以及用户平均步行速度的变化率、点击行为速度和点击行为速度的变化率等等。例如,用户平均步行速度是指在过去的一段时间内步行速度的平均值;而用户平均步行速度的变化率,是指用户在当前一段时间内的速度与用户在过去一段时间内的平均步行速度的比值。
3、“行程特征数据”。“行程特征数据”是从用户请求数据提取出行特征的数据,例如与请求的位置、地理和时间特征。行程特征可以包括用户位置、天气状况、一天的时间和请求提交是在星期几。某些行程特征由系统确定,而不是由请求数据确定,例如时间和星期几、天气条件等。
“用户特征数据”和“行程特征数据”都是特征工程的两类重要数据。特征工程中,构建这两类数据目标是构建更有预测能力的变量。我们利用这两类数据的历史数据,通过监督机器学习模型来对数据训练建模。所谓监管学习就是给定一组学习样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类,这样的机器学习就被称之为监督学习。
Uber的专利中提到核心算法主要是分类算法如决策树、支持向量机或神经网络。用户状态预测模型一旦建立了并通过相关的模型检验后,即可以对实时的用户数据进行分析,并利用模型预测用户的状态是否为“清醒”状态。
由于篇幅关系,本文对Uber专利提到的三个算法进行原理性的介绍:
1、决策树(decision tree)是一类常见的机器学习方法,目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。决策树学习是采用自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树;
2、支持向量机。支持向量机(Support Vector Machine,SVM)是一个常见的分类器,核心思路是通过构造分割面将数据进行分离,一个支持向量机构造一个超平面,或在高或无限维空间,其可以用于分类;
3、神经网络。神经网络的作用本质上也是一个分类器,人工神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。人工神经网络由大量的节点(或称神经元)之间相互联接构成,每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。目前神经网络算法已经有几十种,最近流行的深度学习也属于神经网络的发展方向。
我们用一个简单的示例来更直观的阐述上述过程。在uber的专利文献中提到一个例子,见以下表“用户状态预测模型数据示例”。
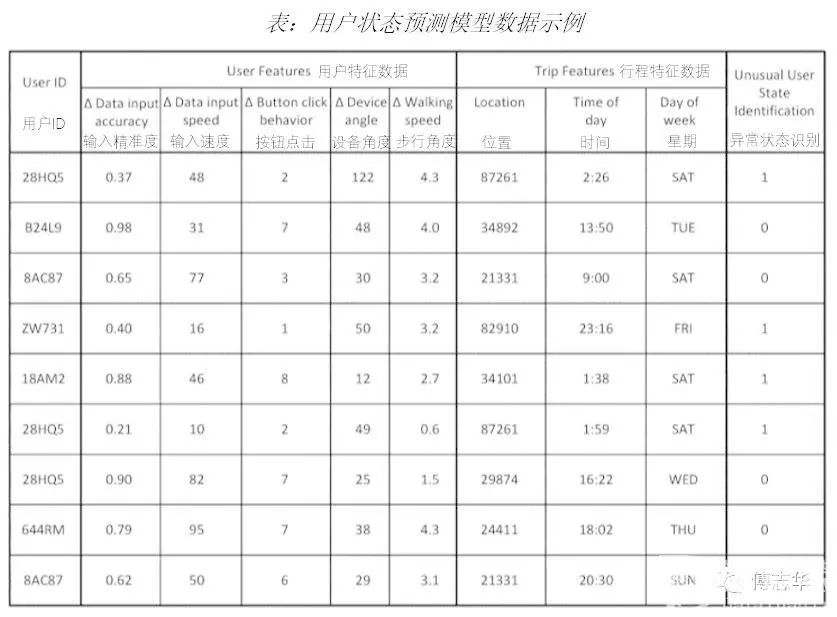
表格中,每一行代表一条用户记录数据。第一列是加密后的用户ID,用来唯一区分每个用户。第二列至第六列是用户特征数据(User Features),包括用户文本的输入精度、用户数据输入速度、按钮点击行为、设备的角度、步行速度。第七至第八列是“行程特征数据(Trip Features)”,包括位置、时间和星期。值得大家注意的是,用户特征数据和行程特征数据只是列了部分变量,并没有列全,只是为了举例方便。最后一列“异常状态识别”是通过模型预测的用户异常状态,1代表异常,0代表正常。正如上文提到,用户的“异常状态预识别”是通过基于用户特征数据(User Features)和行程特征数据(Trip Features)进行训练,通过有监督学习的机器学习算法(上文提到的三种算法),建立“用户状态识别预测模型”计算得出。
从预测结果我们可以看到,第一列用户(用户ID为28HQ5)为预测为异常用户,即醉酒的可能性很大。第二列用户(用户ID为B24L9)为预测正常用户。这两位用户的差异在于数据输入精准度(异常用户精准度更低)、按钮点击次数(异常用户点击次数更多)、设备角度(异常用户角度更倾斜)、位置的差异、时间(异常用户在凌晨两点多打车)、星期的差异(异常用户在周末)。从典型的用户分析也能看到正常和异常用户的用户特征数据和行程特征数据有显著的差异。
Uber通过其APP收集到的数据,利用机器学习算法实现的是否处于醉酒状态的预测,在其他领域也有非常多的应用场景,包括保险、交通安全、金融、安防等领域。在保险领域,如果我们了解到某个用户经常酗酒,那么该用户很可能出险的概率就高,对于保险公司来说,并不是最优质的客户;在交通安全领域,畅想一下,相关的交通管理机构联合大型互联网企业做用户不清醒状态的预测,如果某用户醉酒的可能性很大,那么可以通过互联网应用来提醒该用户酒后不要驾驶;在金融领域,以小额贷款为例,如果发现某个用户老是醉酒,其征信得分应该有所降低,贷款审核也应该更加慎重。
这篇关于从学术角度论Uber的人工智能预测醉酒专利的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[Day 73] 區塊鏈與人工智能的聯動應用:理論、技術與實踐](/front/images/it_default2.jpg)





