本文主要是介绍机器学习实战14-在日本福岛核电站排放污水的背景下,核电站对人口影响的分析实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是微学AI,今天给大家介绍一下机器学习实战14-在日本福岛核电站排放污水的背景下,核电站对人口影响的分析实践。
近日,日本政府举行内阁成员会议,决定于2023年8月24日启动福岛核污染水排海。当地时间2023年8月24日13时,日本福岛第一核电站启动核污染水排海。福岛第一核电站的核污水中含有多种放射性物质。对人体存在伤害,其中,锶-90可导致骨组织肉瘤、引发白血病;铯-137会引起软组织肿瘤与癌症;碘-129容易导致甲状腺癌;碳-14可能会损害人类DNA。

一、放射性物质
放射性物质 存在着三种主要的射线类型,它们分别是阿尔法射线(α)、贝塔射线(β)和伽马射线(γ):
1.阿尔法射线( α \alpha α射线):阿尔法射线是由氦原子核组成的带电粒子束。由于它们包含两个质子和两个中子,因此具有正电荷。阿尔法射线的穿透能力较弱,一般只能穿透数厘米的空气或者几个微米的固体,因此阿尔法射线通常不能通过人体或纸张等薄材料。然而,如果被内部摄入或吸入,则可能对人体造成较大的伤害。
2.贝塔射线( β \beta β射线):贝塔射线是由带电的高速电子或正电子组成的粒子束。电子射线称为 β − \beta^- β−射线,而正电子射线称为 β + \beta^+ β+射线。贝塔射线比阿尔法射线具有更强的穿透能力,可以穿透空气和一些较薄的固体物质。然而,贝塔射线的穿透能力仍然相对有限,在适当的屏蔽下可以有效地阻挡。
3.伽马射线( γ \gamma γ射线):伽马射线是高能电磁辐射,类似于X射线。与阿尔法射线和贝塔射线不同,伽马射线不携带任何电荷或粒子,因此不受电场或磁场的影响。伽马射线具有很强的穿透能力,可以穿透大部分常见物质,包括人体组织。为了有效屏蔽伽马射线,通常需要使用较厚的铅、混凝土或其他密度较高的材料。
二、三种射线的核反应
以下是三种射线的典型核反应方程式的示例:
1.阿尔法射线 ( α \alpha α) 反应方程:
Z A X → Z − 2 A − 4 Y + 2 4 α \begin{equation} _{Z}^{A}X \rightarrow _{Z-2}^{A-4}Y + _{2}^{4}\alpha \end{equation} ZAX→Z−2A−4Y+24α
这里 X X X 代表起始元素, Y Y Y 代表产生的元素, Z A _{Z}^{A} ZA 表示原子序数为 Z Z Z,质量数为 A A A 的核。
2.贝塔射线 ( β \beta β) 反应方程:
Z A X → Z + 1 A Y + e − + ν e ˉ \begin{equation} _{Z}^{A}X \rightarrow _{Z+1}^{A}Y + e^{-} + \bar{\nu_e} \end{equation} ZAX→Z+1AY+e−+νeˉ
这里 X X X 代表起始元素, Y Y Y 代表产生的元素, Z A _{Z}^{A} ZA 表示原子序数为 Z Z Z,质量数为 A A A 的核。 e − e^{-} e− 表示负电子(电子), ν e ˉ \bar{\nu_e} νeˉ 表示反中微子。
3.伽马射线 ( γ \gamma γ) 反应方程:
Z A X ∗ → Z A X + γ \begin{equation} _{Z}^{A}X^{*} \rightarrow _{Z}^{A}X + \gamma \end{equation} ZAX∗→ZAX+γ
这里 X ∗ X^{*} X∗ 表示激发态的核, X X X 表示基态的核, γ \gamma γ 表示伽马射线。
三、核电站的数据加载
数据下载地址:链接:https://pan.baidu.com/s/1wz5L2ykpjUNlKs2icTWkNg?pwd=2j0r
提取码:2j0r
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as pltdf = pd.read_csv('nuclear.csv', delimiter=',')countries_shortNames = [['UNITED STATES OF AMERICA', 'USA'], \['RUSSIAN FEDERATION', 'RUSSIA'], \['IRAN, ISLAMIC REPUBLIC OF', 'IRAN'], \['KOREA, REPUBLIC OF', 'SOUTH KOREA'], \['TAIWAN, CHINA', 'CHINA']]
for shortName in countries_shortNames:df = df.replace(shortName[0], shortName[1])
三、核电站的世界分布
import folium
import matplotlib.cm as cm
import matplotlib.colors as colorslatitude, longitude = 40, 10.0
map_world_NPP = folium.Map(location=[latitude, longitude], zoom_start=2)viridis = cm.get_cmap('viridis', df['NumReactor'].max())
colors_array = viridis(np.arange(df['NumReactor'].min() - 1, df['NumReactor'].max()))
rainbow = [colors.rgb2hex(i) for i in colors_array]for nReactor, lat, lng, borough, neighborhood in zip(df['NumReactor'].astype(int), df['Latitude'].astype(float),df['Longitude'].astype(float), df['Plant'], df['NumReactor']):label = '{}, {}'.format(neighborhood, borough)label = folium.Popup(label, parse_html=True)folium.CircleMarker([lat, lng],radius=3,popup=label,color=rainbow[nReactor - 1],fill=True,fill_color=rainbow[nReactor - 1],fill_opacity=0.5).add_to(map_world_NPP)# 在地图上显示
map_world_NPP.save('world_map.html') # 保存为 HTML 文件
# 然后打开world_map.html 文件 可以看到
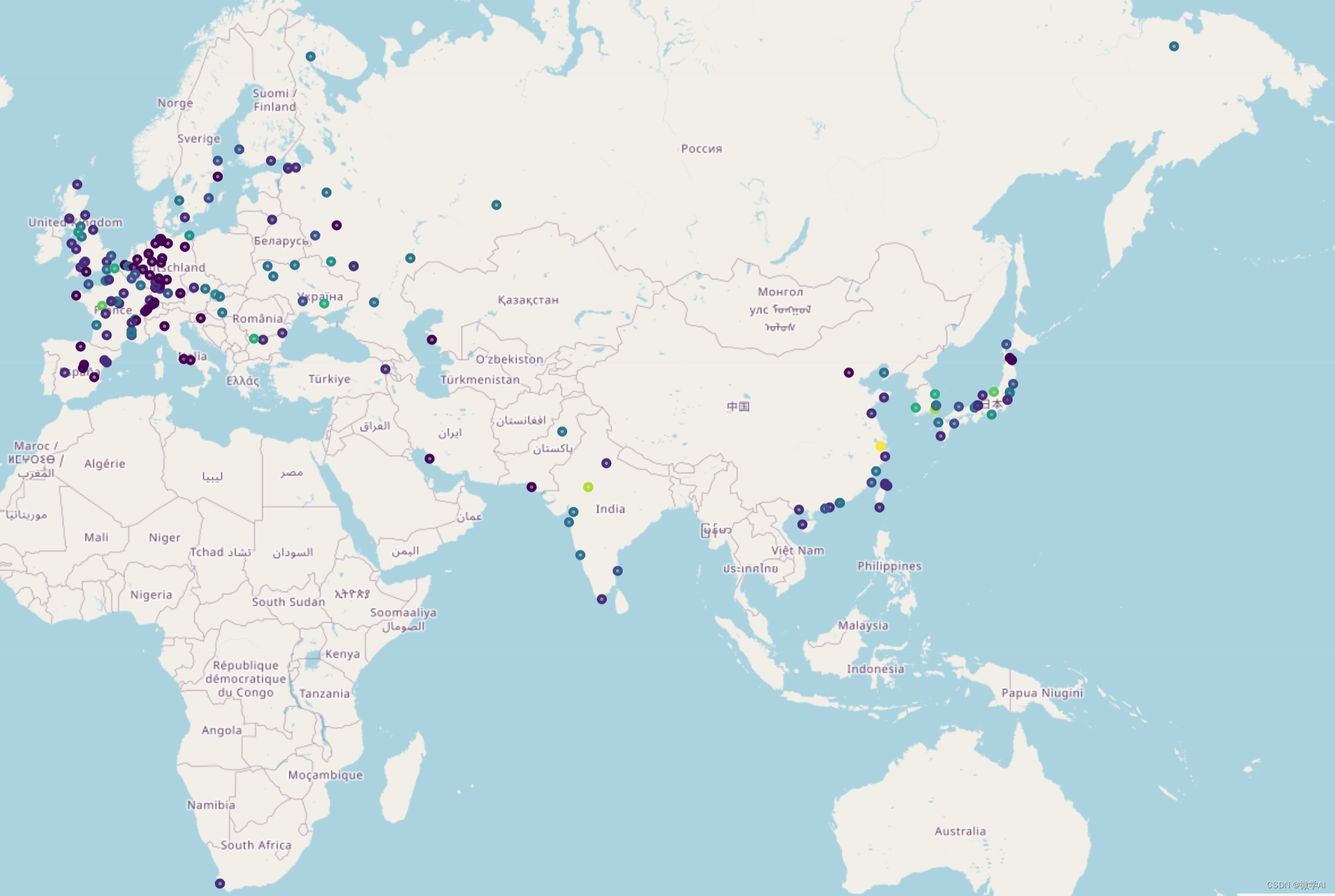
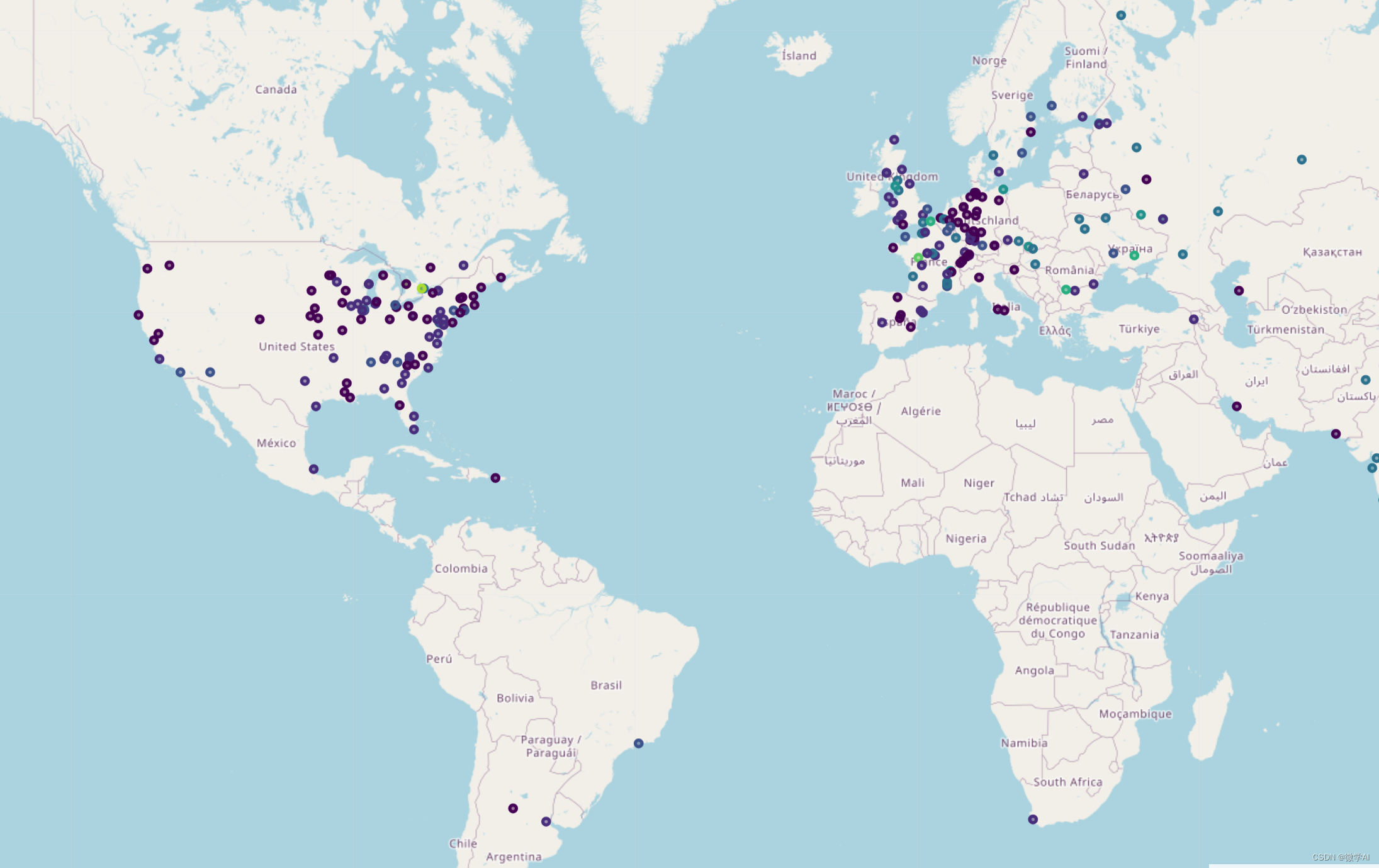
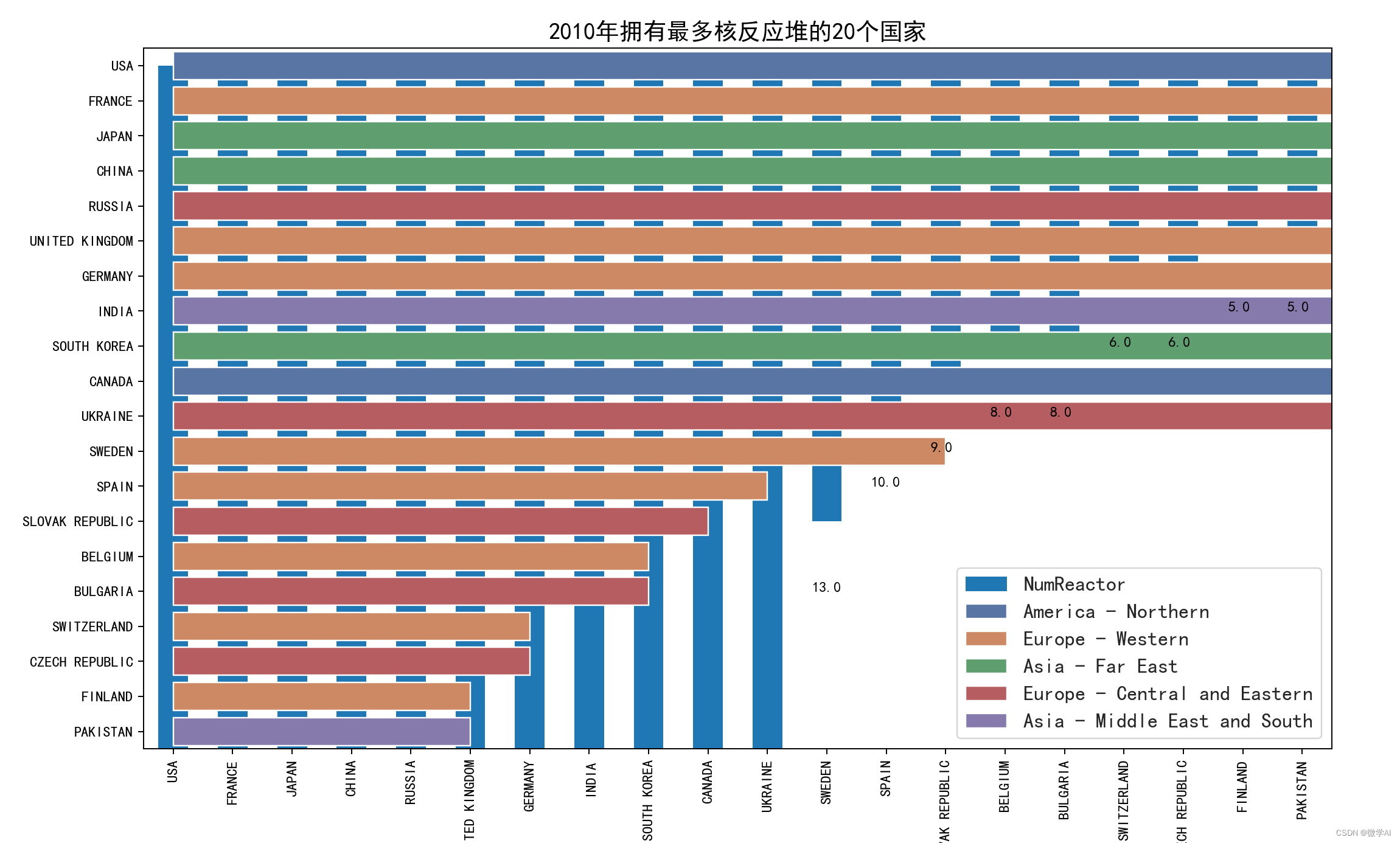
四、拥有最多核反应堆的20个国家对比
countries = df['Country'].unique()
df_count_reactor = [[i, df[df['Country'] == i]['NumReactor'].sum(), df[df['Country'] == i]['Region'].iloc[0]] for i incountries]
df_count_reactor = pd.DataFrame(df_count_reactor, columns=['Country', 'NumReactor', 'Region'])
df_count_reactor = df_count_reactor.set_index('Country').sort_values(by='NumReactor', ascending=False)[:20]
ax = df_count_reactor.plot(kind='bar', stacked=True, figsize=(10, 3),title='The 20 Countries With The Most Nuclear Reactors in 2010')
ax.set_ylim((0, 150))
for p in ax.patches:ax.annotate(str(p.get_height()), xy=(p.get_x(), p.get_height() + 2))
df_count_reactor['Country'] = df_count_reactor.index
sns.set(rc={'figure.figsize': (11.7, 8.27)})
sns.set_style("whitegrid")
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
ax = sns.barplot(x="NumReactor", y="Country", hue="Region", data=df_count_reactor, dodge=False, orient='h')
ax.set_title('2010年拥有最多核反应堆的20个国家', fontsize=16)
ax.set_xlabel('Reactors', fontsize=16)
ax.set_ylabel('')
ax.legend(fontsize='14')plt.show()
五、核电站暴露人口的分析
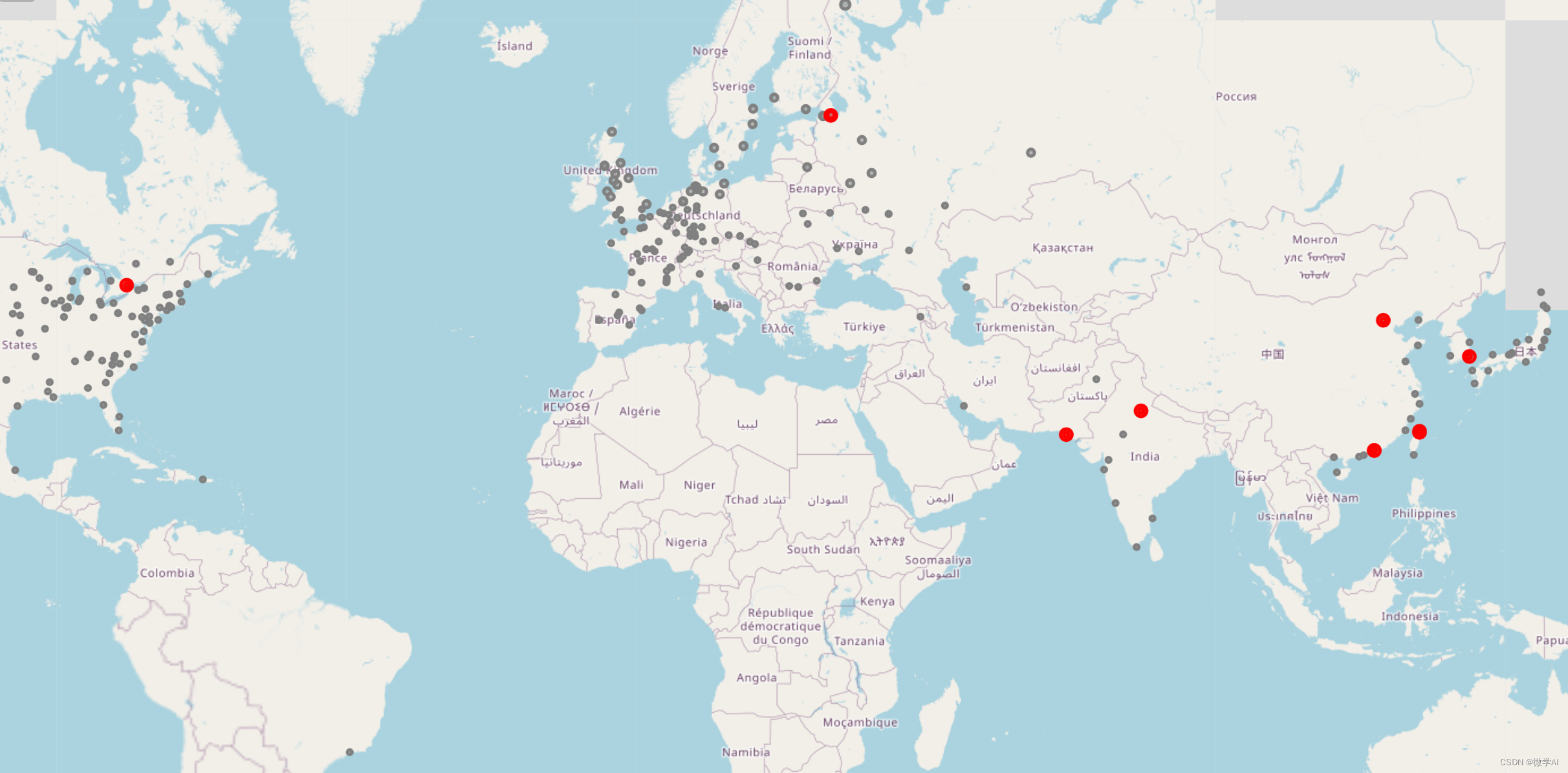
def getMostExposedNPP(Exposedradius):df_pop_sort = df.sort_values(by=str('p10_' + str(Exposedradius)), ascending=False)[:10]df_pop_sort['Country'] = df_pop_sort['Plant'] + ',\n' + df_pop_sort['Country']df_pop_sort = df_pop_sort.set_index('Country')df_pop_sort = df_pop_sort.rename(columns={str('p90_' + str(Exposedradius)): '1990', str('p00_' + str(Exposedradius)): '2000',str('p10_' + str(Exposedradius)): '2010'})df_pop_sort = df_pop_sort[['1990', '2000', '2010']] / 1E6ax = df_pop_sort.plot(kind='bar', stacked=False, figsize=(10, 4))ax.set_ylabel('Population Exposure in millions', size=14)ax.set_title('Location of nuclear power plants \n with the most exposed population \n within ' + Exposedradius + ' km radius',size=16)print(df_pop_sort['2010'])getMostExposedNPP('30')latitude, longitude = 40, 10.0
map_world_NPP = folium.Figure(width=100, height=100)
map_world_NPP = folium.Map(location=[latitude, longitude], zoom_start=2)for nReactor, lat, lng, borough, neighborhood in zip(df['NumReactor'].astype(int), df['Latitude'].astype(float),df['Longitude'].astype(float), df['Plant'], df['NumReactor']):label = '{}, {}'.format(neighborhood, borough)label = folium.Popup(label, parse_html=True)folium.Circle([lat, lng],radius=30000,popup=label,color='grey',fill=True,fill_color='grey',fill_opacity=0.5).add_to(map_world_NPP)Exposedradius = '30'
df_sort = df.sort_values(by=str('p10_' + str(Exposedradius)), ascending=False)[:10]for nReactor, lat, lng, borough, neighborhood in zip(df_sort['NumReactor'].astype(int),df_sort['Latitude'].astype(float),df_sort['Longitude'].astype(float), df_sort['Plant'],df_sort['NumReactor']):label = '{}, {}'.format(neighborhood, borough)label = folium.Popup(label, parse_html=True)folium.CircleMarker([lat, lng],radius=5,popup=label,color='red',fill=True,fill_color='red',fill_opacity=0.25).add_to(map_world_NPP)for nReactor, lat, lng, borough, neighborhood in zip(df_sort['NumReactor'].astype(int),df_sort['Latitude'].astype(float),df_sort['Longitude'].astype(float), df_sort['Plant'],df_sort['NumReactor']):label = '{}, {}'.format(neighborhood, borough)label = folium.Popup(label, parse_html=True)folium.Circle([lat, lng],radius=30000,popup=label,color='red',fill=True,fill_color='red',fill_opacity=0.25).add_to(map_world_NPP)
# 在地图上显示
map_world_NPP.save('world_map2.html') # 保存为 HTML 文件
六、总结
如果核电站靠近人口密集区,核污染水排海可能对周边人口产生一些严重影响:
1.健康风险:放射性物质对人体健康产生潜在威胁。如果核污染水排入海洋,有可能通过海洋食物链的途径进入人类的食物供应链中,从而增加食物中放射性物质的摄入风险。不当接触或摄入这些物质可能导致慢性疾病,如癌症和其他与放射性物质相关的健康问题。
2.社会心理影响:核事故可能引发社会心理压力和不安感。居住在福岛核电站附近的居民可能面临被迫疏散、失去家园、生活不稳定等问题,这对他们的心理健康和社会适应能力造成挑战。
3.经济影响:核事故对当地经济造成了持续的冲击。核电站事故导致了大量的停工和疏散措施,对当地居民和企业的生计和经济活动造成了严重影响。此外,核事故还对当地旅游业、农业和渔业等行业带来负面影响,进一步加剧了经济困难。
这篇关于机器学习实战14-在日本福岛核电站排放污水的背景下,核电站对人口影响的分析实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




