本文主要是介绍手推广告论文(二)Wide Deep 推荐系统算法Wide Deep Learning for Recommender Systems,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Wide & Deep Learning for Recommender Systems
论文地址https://arxiv.org/pdf/1606.07792.pdf
摘要
广义线性模型结合非线性特征转换,在处理具有大规模稀疏输入的回归和分类问题中已被广泛应用。通过一系列交叉积特征转换来记忆特征交互既有效又具有解释性,然而要实现更好的泛化性能,需要投入更多的特征工程工作。相较于此,深度神经网络能够通过为稀疏特征学习低维度密集嵌入,以较少的特征工程来更好地泛化至未见过的特征组合。但是,在用户与项目互动稀疏且高秩的情况下,具有嵌入的深度神经网络可能过度泛化,导致推荐的项目相关性较低。
为了解决这一问题,本文提出了一种名为Wide & Deep学习的方法,它联合训练宽线性模型和深度神经网络,将记忆与泛化的优势结合到推荐系统中。我们将该方法应用于Google Play商店,这是一个拥有超过10亿活跃用户和100万应用的商业移动应用平台,并对其进行了评估。在线实验结果表明,与仅使用宽模型或深模型相比,Wide & Deep方法显著提高了应用的下载量。同时,我们还在TensorFlow框架中开源了我们的实现方法。
CCS概念: • 计算方法 → 机器学习;神经网络;监督学习; • 信息系统 → 推荐系统;
关键词: Wide & Deep学习,推荐系统。
引言
推荐系统可以看作是一种搜索排名系统,它接收一组包含用户和上下文信息的输入查询,然后输出一个按照相关性排序的项目列表。在给定查询的情况下,推荐任务的目标是在数据库中找到相关的项目,并依据一定的目标(例如点击率或购买率)对这些项目进行排序。
与普通搜索排名问题类似,推荐系统面临的一个挑战是实现记忆和泛化的平衡。记忆可以简要地定义为学习项目或特征之间频繁共现的模式,并从历史数据中挖掘潜在的相关性。相对而言,泛化是基于相关性的传递性,旨在探索过去从未出现或很少出现的新特征组合。基于记忆的推荐通常更贴近用户兴趣,并与用户过去互动过的项目具有更直接的相关性。而与记忆相比,泛化更能够提高推荐项目的多样性,从而增加用户发现新内容的可能性。
本文主要关注Google Play商店的应用推荐问题,但所提出的方法同样适用于其他通用的推荐系统。
在实际应用中的大规模在线推荐和排名系统,广义线性模型(如逻辑回归)因其简单性、可扩展性和可解释性而被广泛采用。这些模型通常采用独热编码处理稀疏特征。以二进制特征“user_installed_app=netflix”为例,当用户安装了Netflix时,其值为1。有效地记忆特征可以通过在稀疏特征上进行交叉乘积转换来实现,例如AND(user_installed_app=netflix, impression_app=pandora)”,在用户安装了Netflix且后来安装了Pandora的情况下,其值为1。这表明特征对的共现与目标标签之间存在关联。通过使用较为宽泛的特征,例如AND(user_installed_category=video, impression_category=music),可以实现泛化,尽管可能需要进行手动特征工程。交叉乘积转换的局限在于,它们无法泛化到训练数据中未出现过的查询-项目特征对。
基于嵌入的模型,如因子分解机或深度神经网络,通过为每个查询和项目特征学习低维密集嵌入向量,减少了特征工程的负担,从而使模型能够泛化到之前未见过的查询-项目特征对。然而,在查询-项目矩阵稀疏且高秩的情况下(例如具有特定喜好的用户或只吸引少数人的小众项目),学习有效的低维表示可能会变得困难。在这种情况下,大部分查询-项目对之间实际上不存在交互,但密集嵌入可能导致所有查询-项目对都产生非零预测,从而导致过度泛化和不够相关的推荐结果。相比之下,采用交叉乘积特征转换的线性模型可以用更少的参数捕捉到这些“特殊规则”,从而更好地处理这种情况。
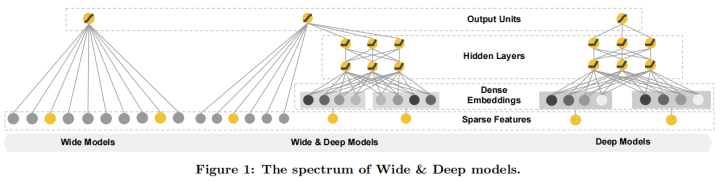
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在本文中,我们提出了一种名为“Wide & Deep”学习框架&#
这篇关于手推广告论文(二)Wide Deep 推荐系统算法Wide Deep Learning for Recommender Systems的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








