本文主要是介绍【RabbitMQ】RabbitMQ 集群的搭建 —— 基于 Docker 搭建 RabbitMQ 的普通集群,镜像集群以及仲裁队列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、集群分类
- 1.1 普通模式
- 1.2 镜像模式
- 1.3 仲裁队列
- 二、普通集群
- 2.1 目标集群
- 2.2 获取 Erlang Cookie
- 2.3 集群配置
- 2.4 启动集群
- 2.5 测试集群
- 三、镜像模式
- 3.1 镜像模式的特征
- 3.2 镜像模式的配置
- 3.2.1 exactly 模式
- 3.2.2 all 模式
- 3.2.3 nodes 模式
- 3.3 测试镜像模式
- 四、仲裁队列
- 4.1 添加仲裁队列
- 4.2 测试仲裁队列
- 4.3 使用 Spring AMQP 声明仲裁队列
一、集群分类
在RabbitMQ中,有不同的集群模式,包括普通模式、镜像模式和仲裁队列。每种模式具有不同的特点和应用场景。
1.1 普通模式
普通集群,也称为标准集群(classic cluster),具备以下特征:
- 在集群的各个节点之间共享部分数据,包括交换机和队列的元信息,但不包括队列中的消息。
- 当访问集群中的某个节点时,如果队列不在该节点上,请求会从数据所在节点传递到当前节点并返回响应。
- 如果队列所在节点宕机,队列中的消息将会丢失。
这种模式适用于一些不需要消息高可用性的场景,或者对于消息丢失不是很敏感的应用。
1.2 镜像模式
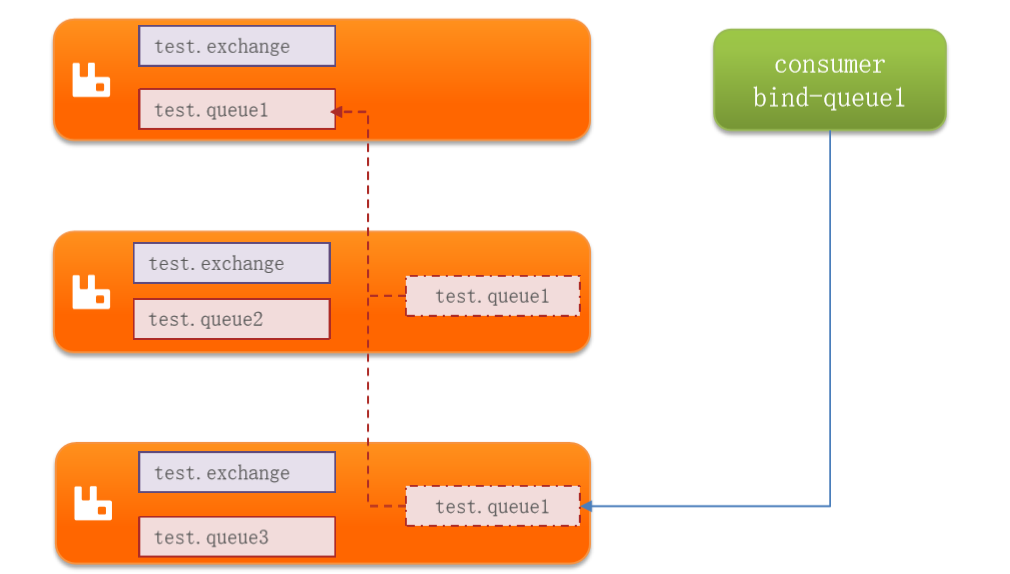
镜像集群,本质上是一种主从模式,具备以下特征:
- 交换机、队列以及队列中的消息会在集群的各个节点之间进行同步备份。
- 创建队列的节点被称为该队列的主节点,而备份节点被称为该队列的镜像节点。
- 一个队列的主节点也可能是另一个队列的镜像节点,这样可以实现主节点的复用。
- 所有的操作都是由主节点执行,然后同步给镜像节点,确保数据的一致性。
- 如果主节点宕机,镜像节点将会接替成为新的主节点,确保高可用性。
这种模式适用于需要消息高可用性的应用场景,因为数据会在主节点和镜像节点之间进行同步备份,即使主节点宕机,数据仍然可用。
1.3 仲裁队列
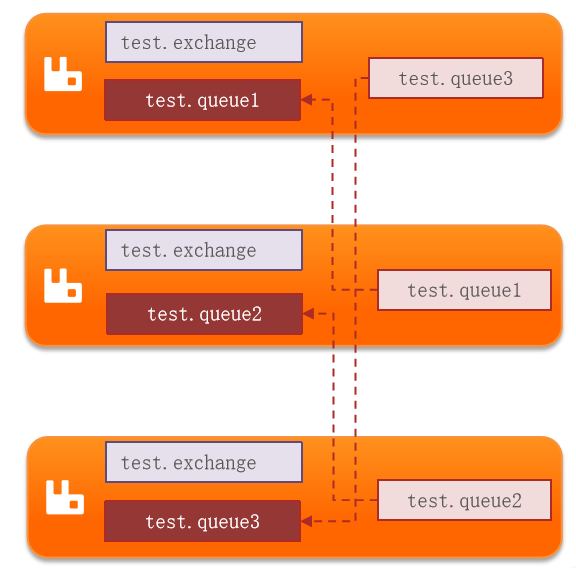
仲裁队列是 RabbitMQ 3.8 版本以后引入的新功能,用来替代镜像队列,具备以下特征:
- 仲裁队列同样采用主从模式,支持主从数据同步。
- 仲裁队列的配置非常简单,没有复杂的设置和配置项。
- 主从数据同步基于Raft协议,实现强一致性,确保数据的可靠性和一致性。
仲裁队列是一种更现代化和可靠的集群模式,适用于要求高可用性和数据强一致性的应用场景。
二、普通集群
2.1 目标集群
下面,我将详细描述如何设置普通模式集群。在本示例中,计划在 Docker 容器上部署一个由3个节点组成的RabbitMQ集群。每个节点都具有特定的主机名和端口设置,如下所示:
| 主机名 | 控制台端口(HTTP) | AMQP 通信端口 |
|---|---|---|
| mq1 | 8081 —> 15672 | 8071 —> 5672 |
| mq2 | 8082 —> 15672 | 8072 —> 5672 |
| mq3 | 8083 —> 15672 | 8073 —> 5672 |
每个节点的标识默认为:rabbit@[主机名],因此,上述三个节点的名称分别为:
rabbit@mq1rabbit@mq2rabbit@mq3
在接下来的步骤中,我将介绍如何在 Docker 容器中配置和启动这三个节点,从而创建一个 RabbitMQ 集群。这将使它们能够协同工作,共享队列和数据。
2.2 获取 Erlang Cookie
RabbitMQ 底层依赖于 Erlang,Erlang 虚拟机是一种面向分布式系统的编程语言,它默认支持集群模式。在集群模式中,每个 RabbitMQ 节点使用一个称为Erlang cookie的共享秘钥来确定它们是否允许相互通信。
为了使两个节点能够互相通信,它们必须具有相同的共享秘密,即Erlang cookie。Cookie只是一个包含最多255个字母数字字符的字符串。每个集群节点必须具有相同的cookie,以确保它们可以相互通信。RabbitMQ实例之间也需要共享相同的cookie以实现相互通信。
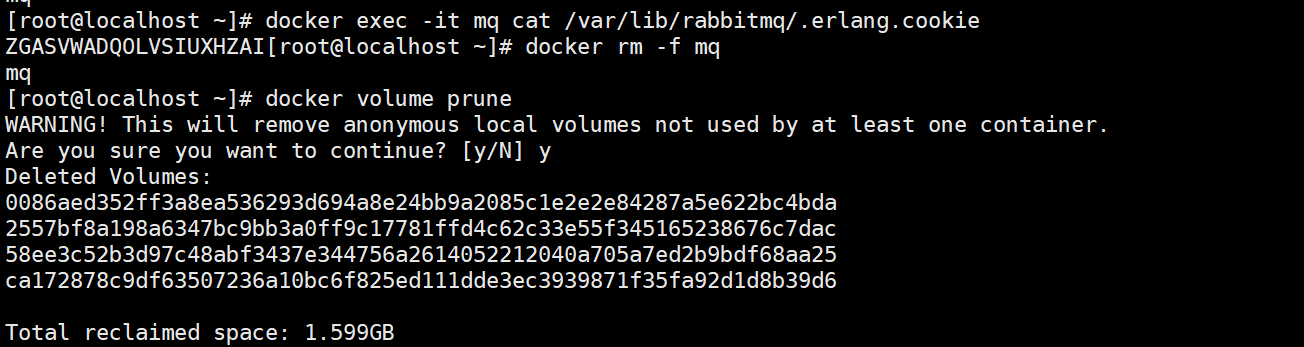
首先,在之前启动的MQ容器中获取一个cookie值,然后将其用作集群的cookie。执行以下命令来获取cookie值:
docker exec -it mq cat /var/lib/rabbitmq/.erlang.cookie
执行此命令后,将获得一个类似下面的Erlang cookie值:

获取了cookie值后,可以停止并删除当前的MQ容器,然后重新构建集群:
docker rm -f mq
请注意,可能还需要删除相关的数据卷:
docker volume prune
这将确保RabbitMQ集群在配置中使用相同的cookie值,以确保节点之间的通信。
2.3 集群配置
在/rabbitmq-cluster目录中,需要创建一个名为 rabbitmq.conf 的配置文件,可以按照以下步骤操作:
-
切换到
/rabbitmq-cluster目录:cd /rabbitmq-cluster -
创建配置文件
rabbitmq.conf:touch rabbitmq.conf这个配置文件用于设置RabbitMQ集群的各种参数,包括节点信息和端口设置。
-
编辑
rabbitmq.conf文件并将以下内容添加到文件中:loopback_users.guest = false listeners.tcp.default = 5672 cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config cluster_formation.classic_config.nodes.1 = rabbit@mq1 cluster_formation.classic_config.nodes.2 = rabbit@mq2 cluster_formation.classic_config.nodes.3 = rabbit@mq3这些配置项用于设置RabbitMQ集群的行为,包括禁用默认的
guest用户,指定AMQP通信端口(5672),以及配置集群的节点信息。 -
创建一个文件用于存储Erlang Cookie,并设置正确的权限:
touch .erlang.cookie echo "ZGASVWADQOLVSIUXHZAI" > .erlang.cookie chmod 600 .erlang.cookieErlang Cookie是用于节点之间认证的共享秘密。确保Cookie在所有节点上具有相同的值。
-
创建三个不同的目录,分别命名为
mq1、mq2和mq3:mkdir mq1 mq2 mq3这些目录将用于存储每个RabbitMQ节点的配置文件和Cookie。
-
将
rabbitmq.conf和.erlang.cookie文件复制到三个节点的目录中,以确保它们共享相同的配置和Cookie信息:cp rabbitmq.conf mq1 cp .erlang.cookie mq1 cp rabbitmq.conf mq2 cp .erlang.cookie mq2 cp rabbitmq.conf mq3 cp .erlang.cookie mq3
这些步骤确保了RabbitMQ集群的每个节点都有相同的配置和认证信息,以便节点之间可以顺利通信,并实现集群功能。
2.4 启动集群
要启动 RabbitMQ 集群,首先需要创建一个网络以确保集群中的不同节点能够相互通信。然后,需要逐个启动每个 MQ 节点,确保它们使用相同的配置和 Erlang Cookie 来实现集群协同工作。以下是详细的步骤:
步骤1:创建网络
首先,创建一个Docker网络,以便集群中的不同节点可以进行网络通信。使用以下命令创建名为 mq-net 的网络:
docker network create mq-net
步骤2:启动第一个MQ节点(mq1)
现在,我们将启动第一个MQ节点 mq1。请运行以下命令:
docker run -d --net mq-net \
-v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=lisi \
-e RABBITMQ_DEFAULT_PASS=123456 \
--name mq1 \
--hostname mq1 \
-p 8071:5672 \
-p 8081:15672 \
rabbitmq:3.8-management
这个命令的解释如下:
docker run -d: 启动一个后台容器。--net mq-net: 将容器连接到名为mq-net的网络,以便容器之间可以相互通信。-v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf: 挂载mq1目录中的rabbitmq.conf配置文件到容器中。-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie: 挂载Erlang Cookie文件到容器中。-e RABBITMQ_DEFAULT_USER=lisi -e RABBITMQ_DEFAULT_PASS=123456: 设置RabbitMQ的默认用户和密码。--name mq1: 为容器指定一个名称。--hostname mq1: 设置容器的主机名。-p 8071:5672 -p 8081:15672: 映射容器的5672端口(AMQP通信端口)和15672端口(RabbitMQ控制台)到主机上。
步骤3:启动第二个MQ节点(mq2)
接下来,我们将启动第二个MQ节点 mq2。请运行以下命令:
docker run -d --net mq-net \
-v ${PWD}/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=lisi \
-e RABBITMQ_DEFAULT_PASS=123456 \
--name mq2 \
--hostname mq2 \
-p 8072:5672 \
-p 8082:15672 \
rabbitmq:3.8-management
这个命令与启动 mq1 的命令类似,只是容器名称、主机名和端口映射不同。
步骤4:启动第三个MQ节点(mq3)
最后,我们将启动第三个MQ节点 mq3。请运行以下命令:
docker run -d --net mq-net \
-v ${PWD}/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=lisi \
-e RABBITMQ_DEFAULT_PASS=123456 \
--name mq3 \
--hostname mq3 \
-p 8073:5672 \
-p 8083:15672 \
rabbitmq:3.8-management
这个命令与启动 mq1 和 mq2 的命令类似,只是容器名称、主机名和端口映射不同。
步骤5:验证容器运行
当这些命令成功执行后,可以使用以下命令来验证容器是否在运行:
docker ps
运行这个命令看到三个运行中的容器,它们代表了三个RabbitMQ节点。
 这样,RabbitMQ 集群的节点已经成功启动,它们将能够相互通信和协同工作。
这样,RabbitMQ 集群的节点已经成功启动,它们将能够相互通信和协同工作。
2.5 测试集群
成功启动了MQ集群之后,我们可以通过浏览器访问MQ的控制台,例如,访问 mq1:
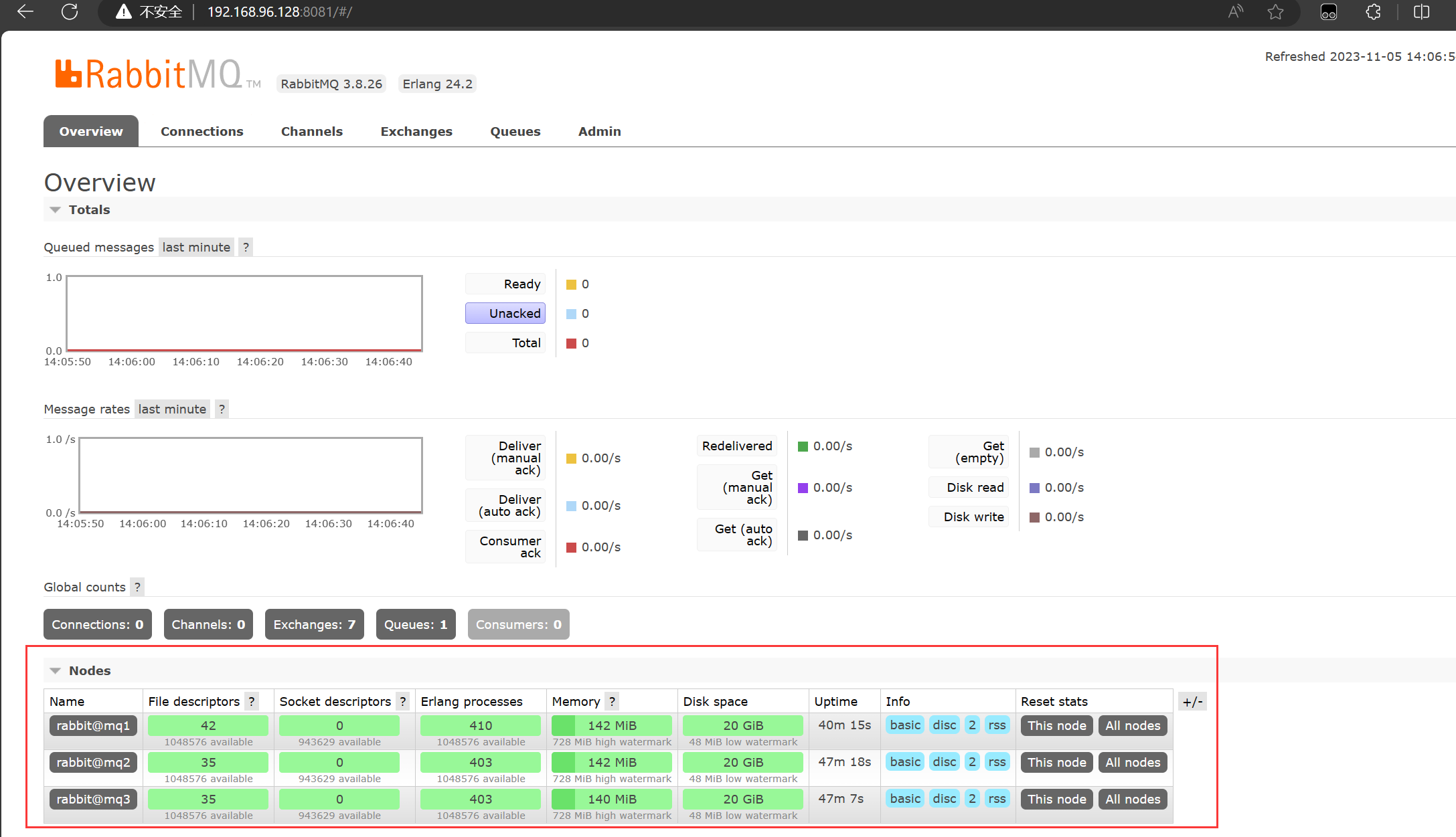 此时就可以看到集群中的三个节点的信息。
此时就可以看到集群中的三个节点的信息。
然后,在mq1这个节点上添加一个 simple.queue 的队列:
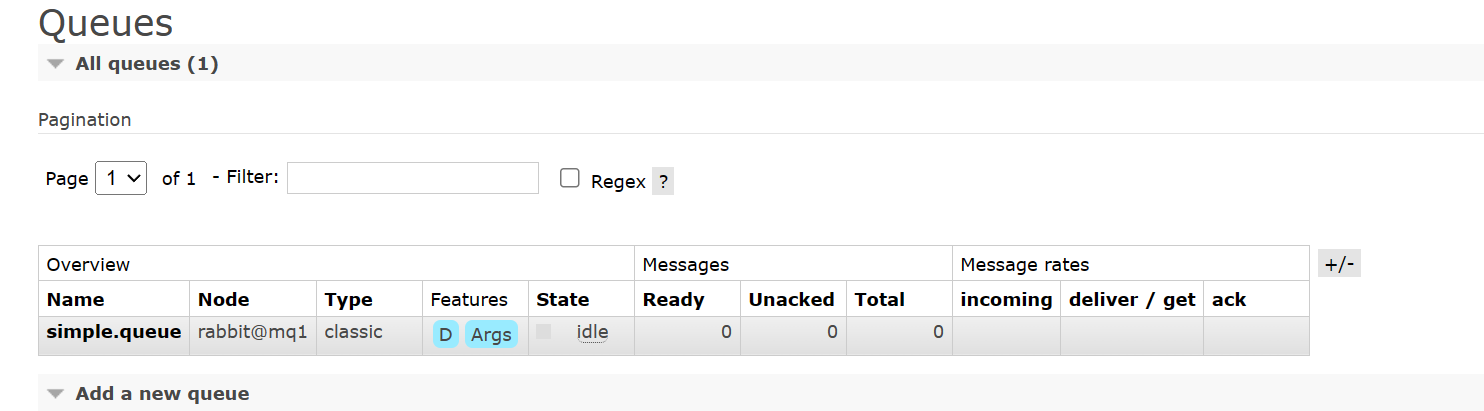
此时,访问 mq2 和 mq3 的控制台,也能看到这个队列,并且能够看到这个队列是属于节点 mq1 的:
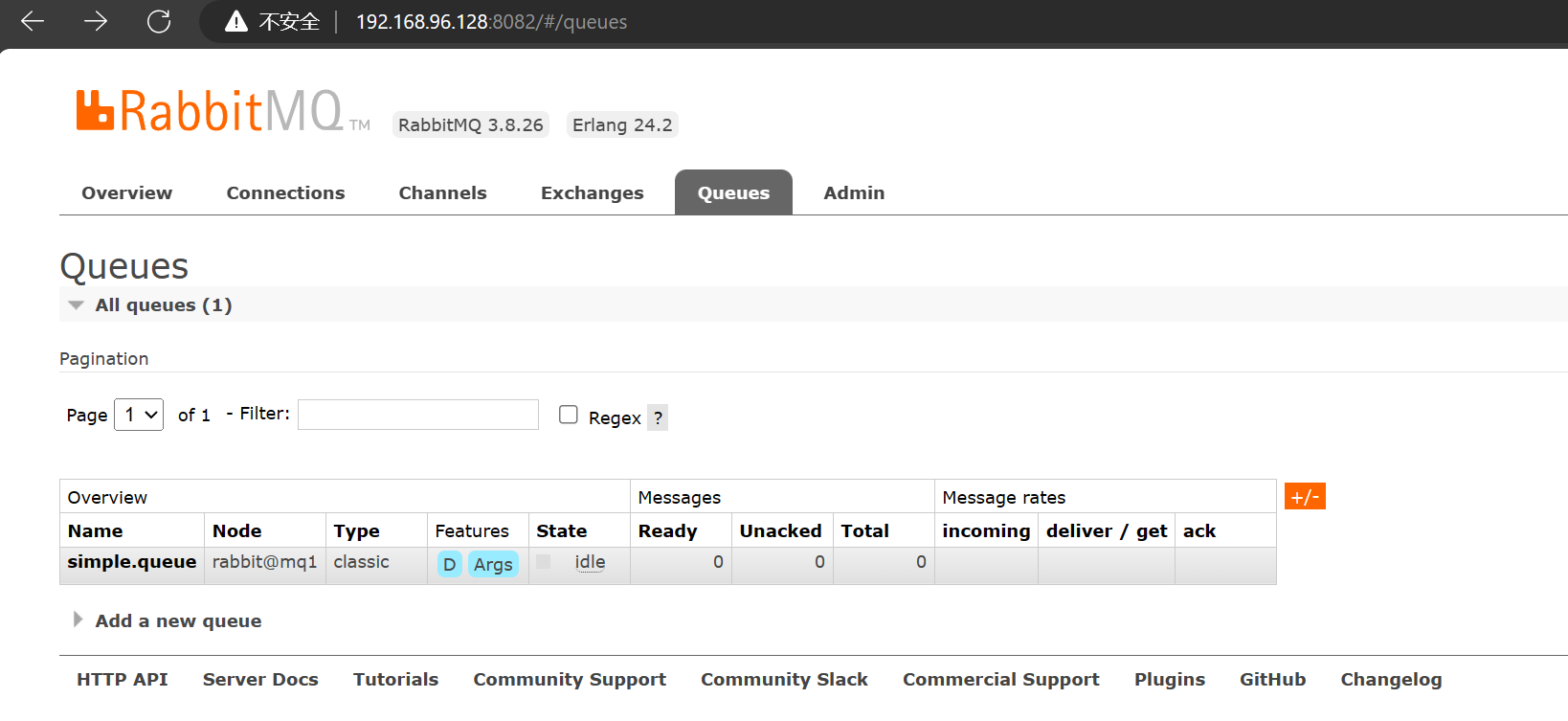
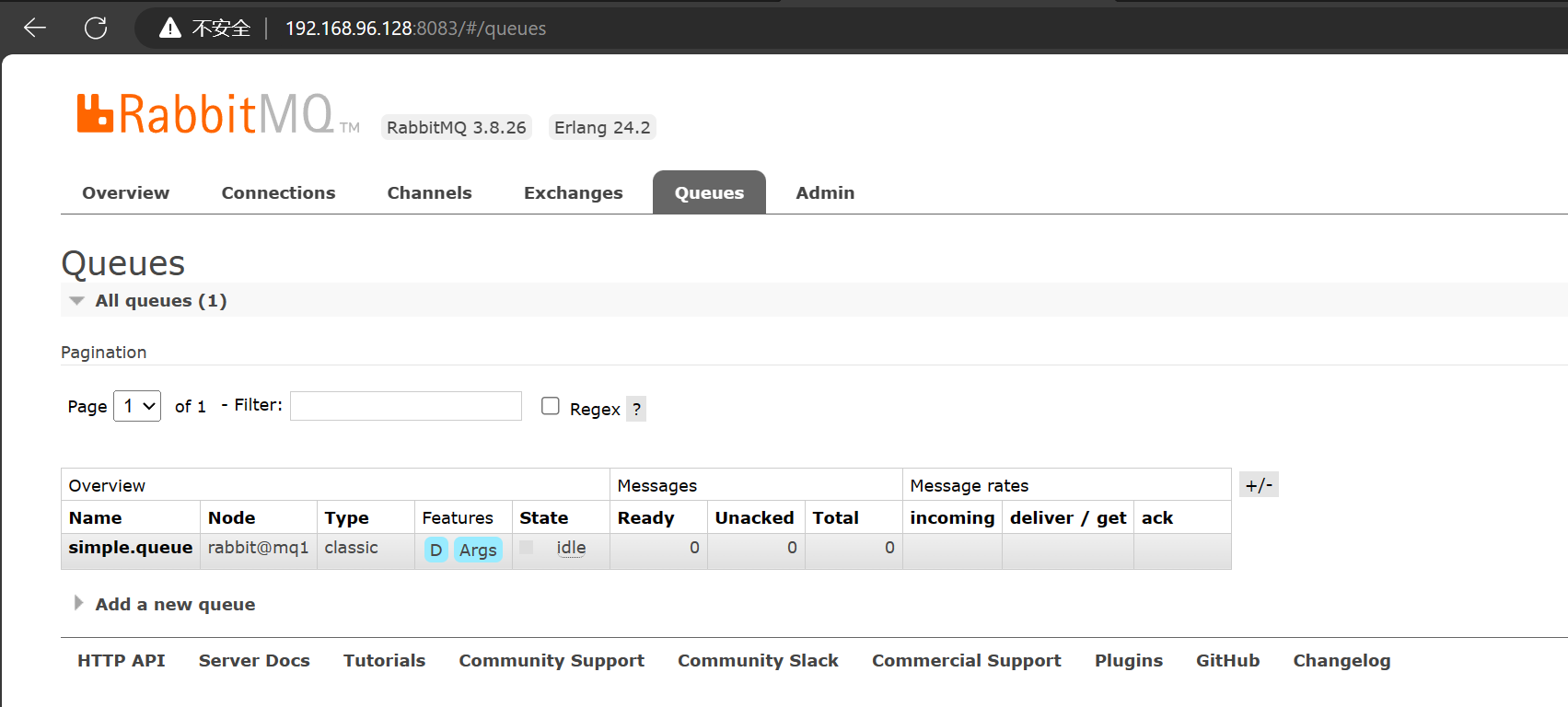
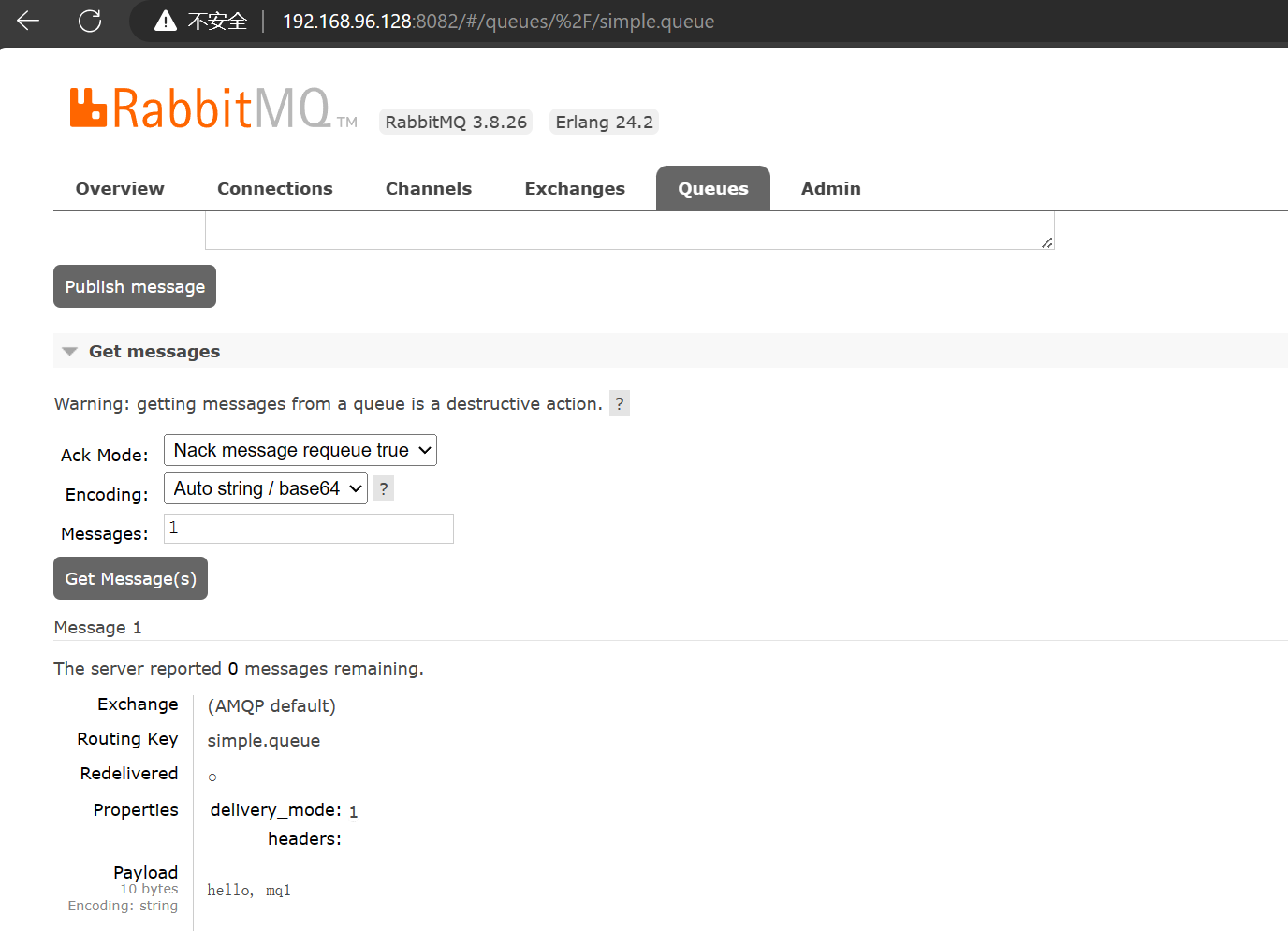
另外,我们可以尝试在 simple.queue 中新增一条消息:

同样的,其他两个节点也可以看到这个消息:
 如果此时,将
如果此时,将 mq1 节点停止了:

其中两个节点看到 simple.queue 的状态就变成了 Down :

三、镜像模式
在上面介绍的普通集群中,存在一个问题,即一旦创建队列的主机宕机,队列就会不可用,无法实现高可用性。为了解决这个问题,RabbitMQ提供了镜像集群方案。
3.1 镜像模式的特征
镜像模式具有以下特征:
-
默认情况下,队列只保存在创建该队列的节点上。在镜像模式下,创建队列的节点被称为该队列的主节点,并且队列会被拷贝到集群中的其他节点,这些节点被称为该队列的镜像节点。
-
不同队列可以在集群中的任意节点上创建,因此不同队列的主节点可以不同。甚至,一个队列的主节点可能是另一个队列的镜像节点。
-
用户发送给队列的所有请求,例如发送消息或消息回执,默认都会在主节点上完成。如果请求在镜像节点上接收到,它也会路由到主节点以执行操作。镜像节点主要起到备份数据的作用。
-
当主节点接收到消费者的ACK(确认)时,所有镜像节点都会删除节点中的数据,以保持数据的一致性。
总结一下镜像模式的特点:
- 镜像队列结构是一主多从,即一个主节点和多个镜像节点。
- 所有操作都由主节点完成,然后同步到镜像节点。
- 如果主节点宕机,镜像节点可以接替成为新的主节点,确保高可用性。但在主从同步完成之前,宕机可能导致数据丢失。
- 镜像模式不具备负载均衡功能,因为所有操作都由主节点完成。然而,不同队列可以有不同的主节点,这可以提高系统的吞吐量。
镜像模式通过数据同步和主节点切换提供了更高的可用性和数据冗余,适用于对数据可用性要求较高的应用场景。
3.2 镜像模式的配置
镜像模式的配置有三种模式,使用不同的参数来定义镜像策略:
-
exactly 模式:使用
ha-mode设置为 “exactly”,并使用ha-params设置队列的副本数量(count)。ha-mode: 设置为 “exactly”。ha-params: 队列的副本数量(count)。
这种模式下,可以精确地控制队列在集群中的副本数量(主节点和镜像节点的总数,count = 镜像数量 + 1)。例如,如果将
ha-params设置为 2,表示每个队列将有两个副本,其中一个是主节点,另一个是镜像节点。如果集群中的节点数不足以维护所需的副本数量,队列将被镜像到所有节点。如果有足够多的节点,但其中的某些节点出现故障,将在其他节点上创建新的镜像。 -
all 模式:使用
ha-mode设置为 “all”。ha-mode: 设置为 “all”。ha-params: (none)
这种模式下,队列将在集群中的所有节点之间进行镜像。队列将镜像到任何新加入集群的节点。然而,要注意的是,将队列镜像到所有节点会增加额外的压力,包括网络I/O、磁盘I/O和磁盘空间的使用。因此,建议在使用此模式时谨慎设置,通常可以考虑使用 “exactly” 模式并根据需要设置适当的副本数量。
-
nodes 模式:使用
ha-mode设置为 “nodes”,并使用ha-params指定节点名称。ha-mode: 设置为 “nodes”。ha-params: 节点名称,指定队列创建在哪些节点上。
在这种模式下,你可以明确指定队列应该创建在哪些节点上。如果指定的节点全部存在,队列将在这些节点上创建。如果指定的节点在集群中存在,但某些节点暂时不可用,队列将在当前客户端连接到的节点上创建。如果指定的节点在集群中不存在,可能会引发异常。
下面是设置这三种模式的命令:
3.2.1 exactly 模式
配置命令如下:
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
rabbitmqctl set_policy:用于设置策略的RabbitMQ命令。ha-two:策略的名称,可以自定义。"^two\.":用正则表达式匹配队列的名称,这个策略将应用于所有以 “two.” 开头的队列。'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}':策略的具体配置,包括:"ha-mode":"exactly":指定策略的模式,这里是 “exactly”,表示要设置队列的副本数量。"ha-params":2:指定副本的数量,这里设置为2,表示一个主副本和一个镜像副本。"ha-sync-mode":"automatic":同步策略,这里设置为 “automatic”,表示新加入的镜像节点会同步主节点中的所有消息,以确保消息的一致性。
3.2.2 all 模式
配置命令如下:
rabbitmqctl set_policy ha-all "^all\." '{"ha-mode":"all"}'
ha-all:策略的名称,可以自定义。"^all\.":用正则表达式匹配队列的名称,这个策略将应用于所有以 “all.” 开头的队列。'{"ha-mode":"all"}':策略的具体配置,包括:"ha-mode":"all":指定策略的模式,这里是 “all”,表示要将队列镜像到集群中的所有节点。
3.2.3 nodes 模式
配置命令如下:
rabbitmqctl set_policy ha-nodes "^nodes\." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
rabbitmqctl set_policy:用于设置策略的RabbitMQ命令。ha-nodes:策略的名称,可以自定义。"^nodes\.":用正则表达式匹配队列的名称,这个策略将应用于所有以 “nodes.” 开头的队列。'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}':策略的具体配置,包括:"ha-mode":"nodes":指定策略的模式,这里是 “nodes”,表示要指定队列创建在哪些节点上。"ha-params":["rabbit@nodeA", "rabbit@nodeB"]:指定了队列应该创建在哪些节点上,这里设置了节点名称列表,例如 “rabbit@nodeA” 和 “rabbit@nodeB”。如果指定的节点都存在,队列将在这些节点上创建。如果某些节点暂时不可用,队列将在当前客户端连接的可用节点上创建。如果指定的节点在集群中不存在,可能会引发异常。
这些命令用于设置不同的镜像模式的策略,具体根据你的需求和集群拓扑来选择合适的策略配置。
3.3 测试镜像模式
下面是我将演示使用 exactly 模式的镜像。因为此时集群的节点数量为 3,因此这里的镜像数量就设置为 2,运行下面的命令:
# 进入 mq1 容器内部
docker exec -it mq1 bash
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'

然后查看任意一个 MQ 节点的控制台,通过 Admin 选项中的 Policies,就可以看到刚才使用命令创建的策略了:
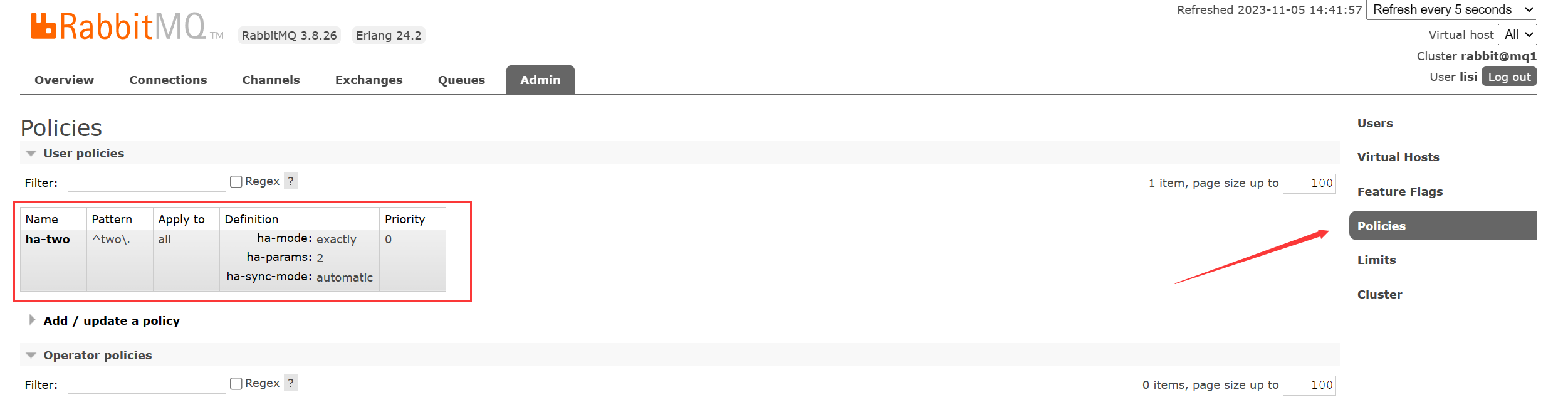
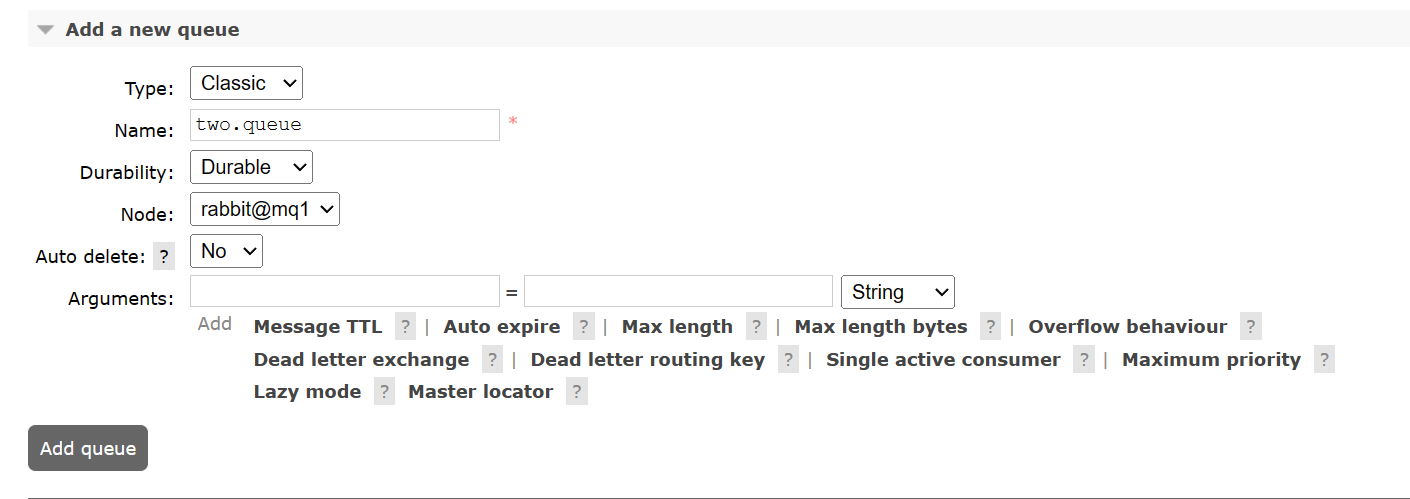
以后创建的所有以two.开头的队列都会采用这个策略。我们可以创建一个新的队列 two.queue:
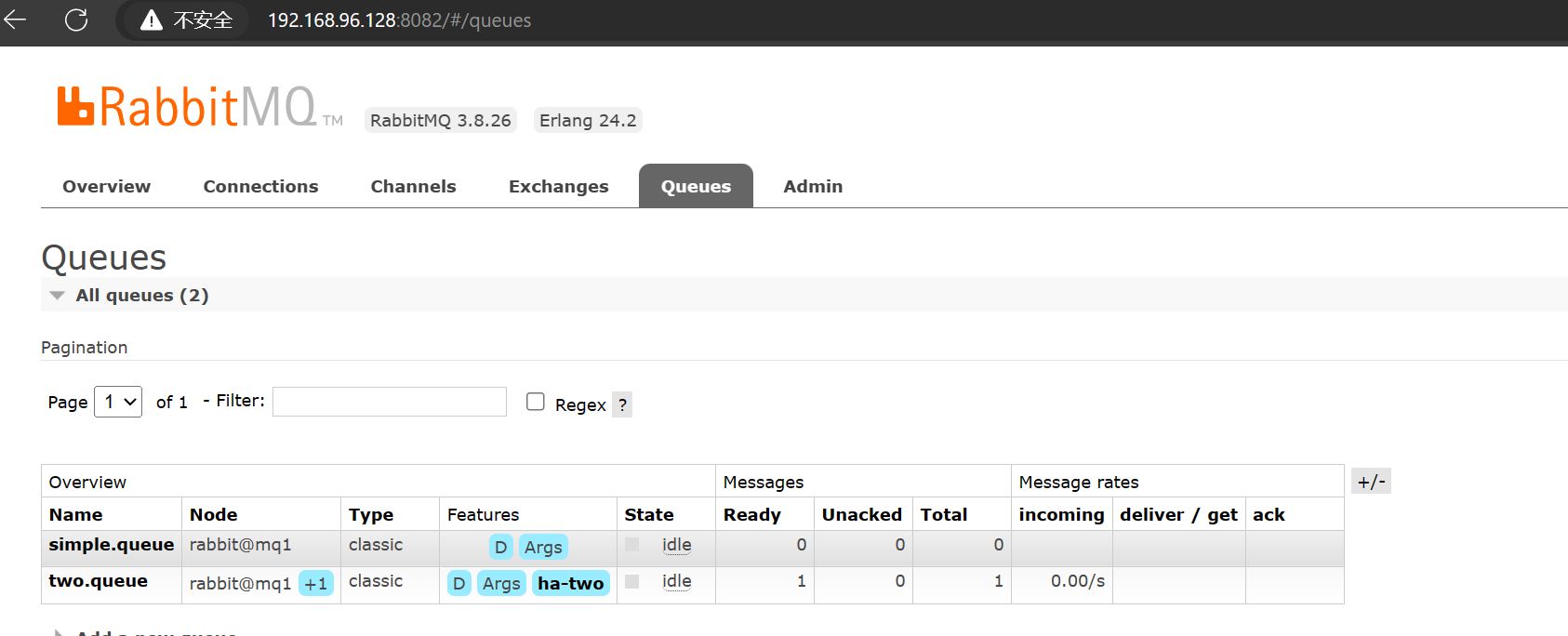
可以发现这个队列的 Node 信息表明是属于 mq1 节点的,并且后面有一个 +1,将鼠标放在上面可以看到这个队列的镜像是 mq3:
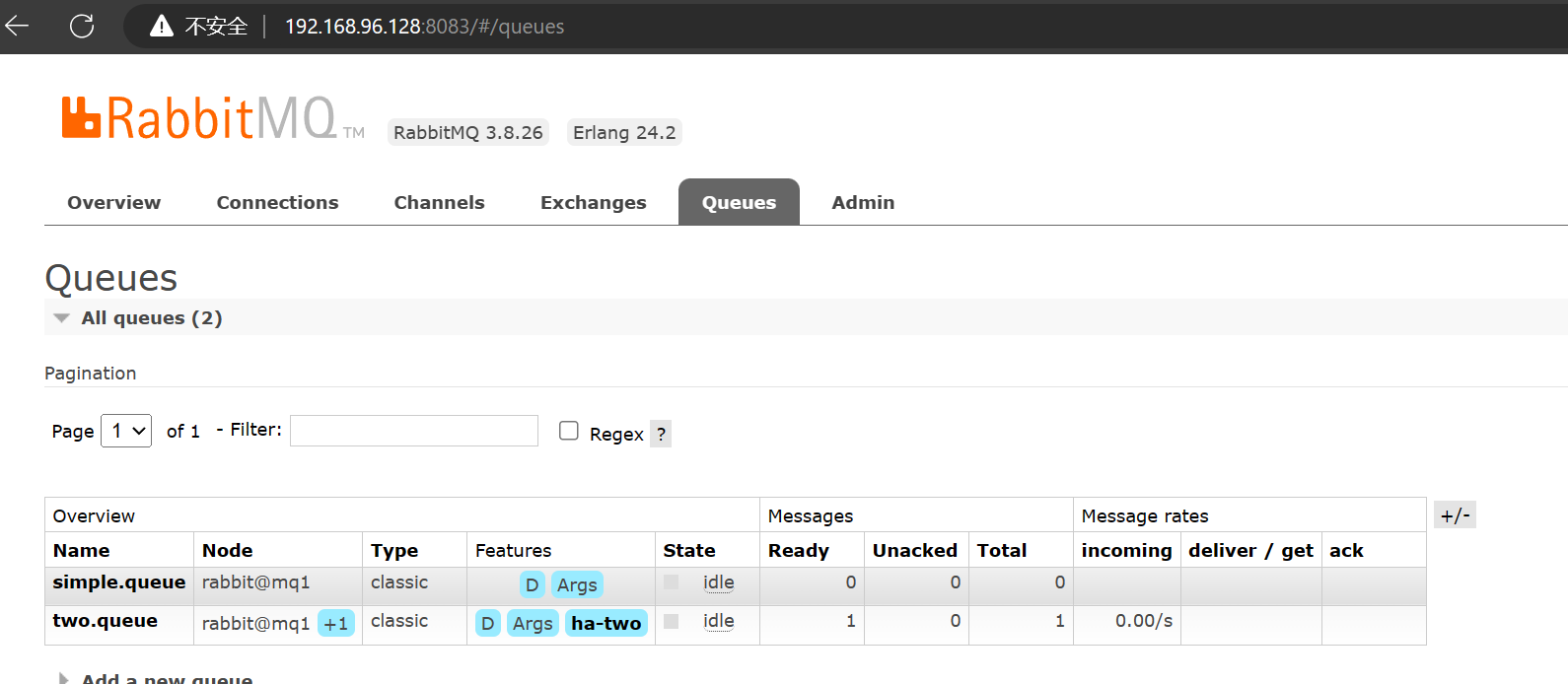
 如果此时在这个队列中新增一条消息,在
如果此时在这个队列中新增一条消息,在mq2 和 mq3 中都能看到,当然,这里的mq2 能看到的原因是引用了mq1。
最后,我们模拟mq1宕机,停止 mq1 节点:
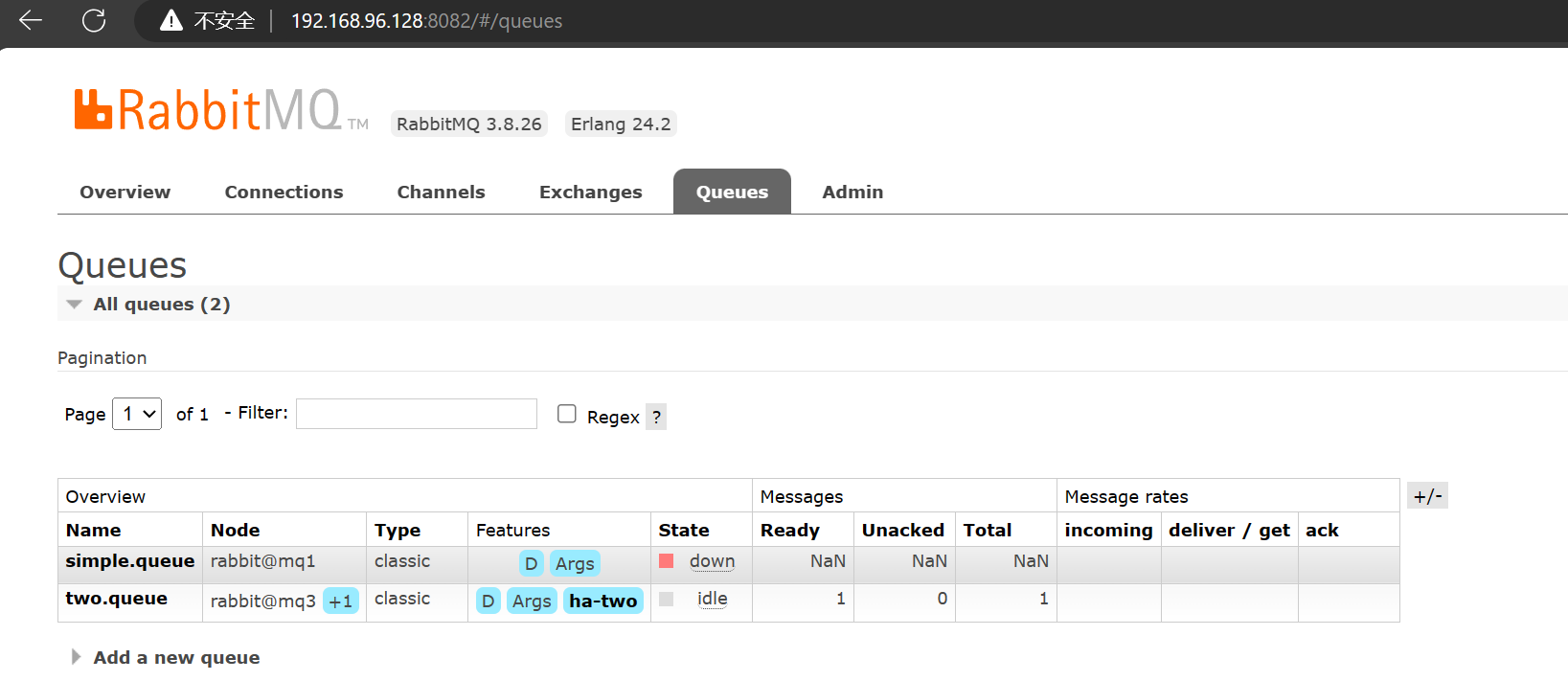 此时发现,原来
此时发现,原来tow.queue的镜像节点mq3 成为了主节点,而剩下的一个 mq2 节点成为了镜像节点。
四、仲裁队列
尽管镜像模式能够做主从复制,但是并不是强一致的,因此可能还是会导致数据的丢失。为了解决这个问题, RabbitMQ 3.8 版本以后引入了仲裁队列是,用来替代镜像队列,它同样是主从模式的,并且使用非常简单,底层的主从同步是基于 Raft 协议,具有强一致的特点。
4.1 添加仲裁队列
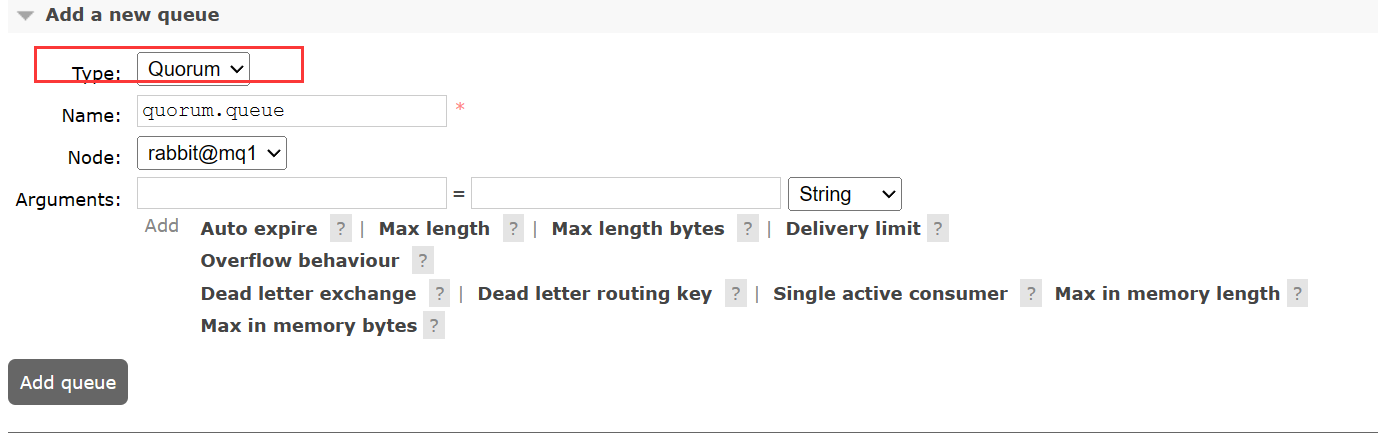
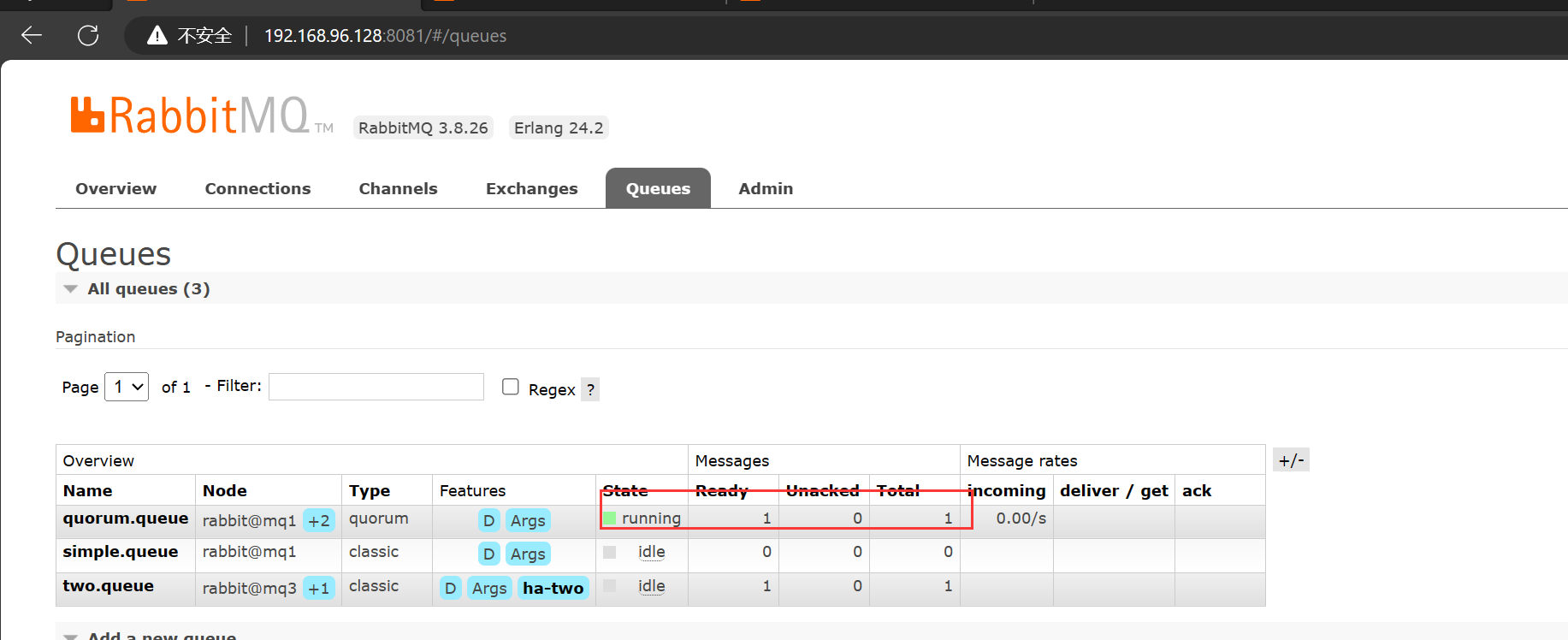
添加仲裁队列的方式非常简单,只需要在创建队列的使用指定队列的类型为 Quorum 即可,例如下面通过任意一个 MQ 节点的控制台创建仲裁队列:
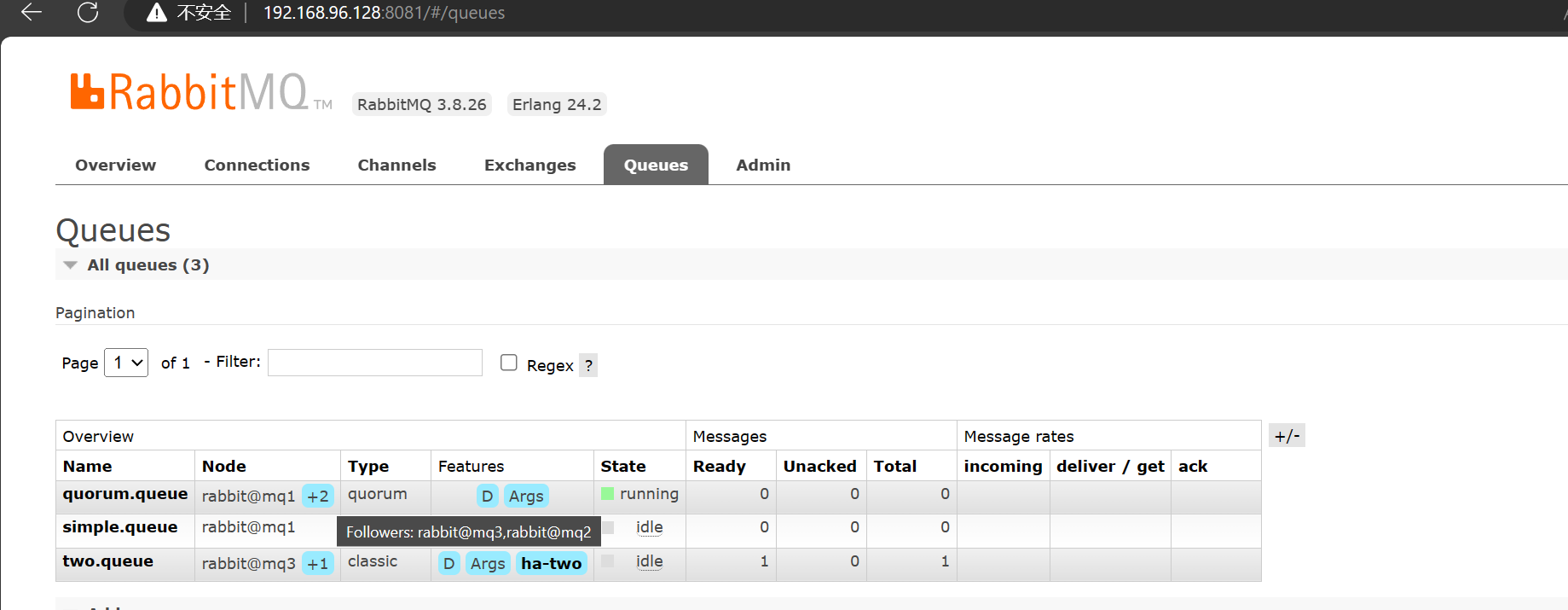
然后发现,其他两个节点都成为了 quorum 的镜像节点了:
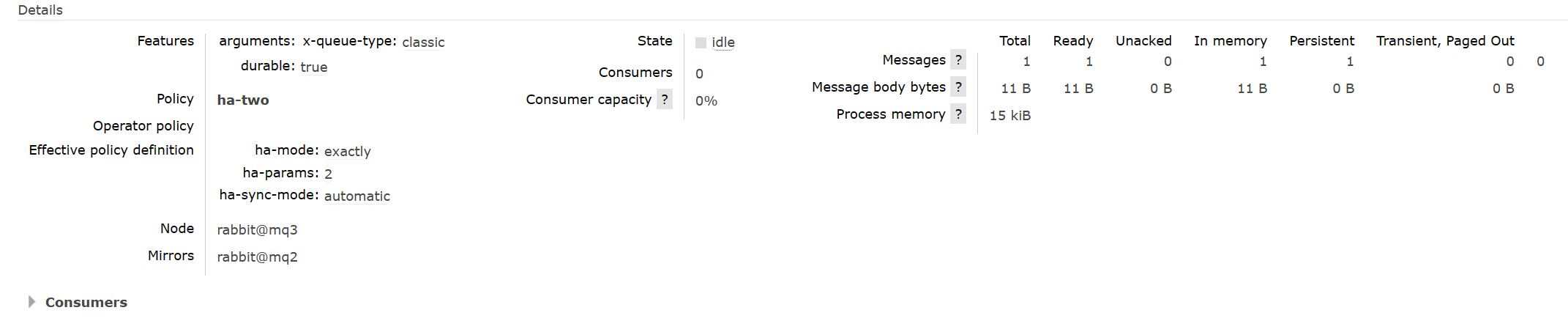
 并且可以查看这个队列的详细信息:
并且可以查看这个队列的详细信息:
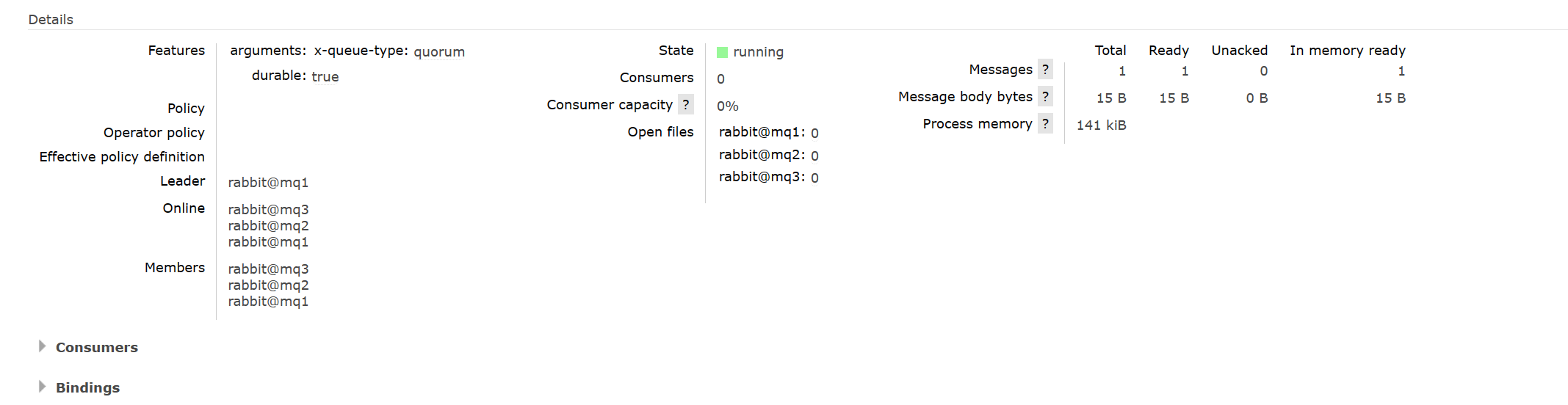
4.2 测试仲裁队列
此时,我们可以向 quorum.queue 队列中发送一条消息:
另外两个节点也都可以看到这条消息:

4.3 使用 Spring AMQP 声明仲裁队列
-
使用
@Bean注解声明仲裁队列@Bean public Queue quorumQueue() {return QueueBuilder.durable("quorum.queue") // 持久化.quorum() // 仲裁队列.build(); }
可以发现使用 Java 代码声明仲裁队列的方式也非常简单,只需要执行 quorum 方法即可。
- Spring AMQP 连接集群,只需要在
yal配置文件中修改为以下配置:
spring:rabbitmq:addresses: 192.168.96.128:8071, 192.168.96.128:8072, 192.168.96.128:8073 # MQ 集群username: lisipassword: 123456virtual-host: /
这篇关于【RabbitMQ】RabbitMQ 集群的搭建 —— 基于 Docker 搭建 RabbitMQ 的普通集群,镜像集群以及仲裁队列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




