本文主要是介绍Oracle三班倒分时段查询数据的一种实现方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现有库表如下:

需求:在任意时间显示上一班车间的库存率情况,并用class字段进行标识。
班次安排:
08:15:00~16:15:00
16:15:00~00:15:00
00:15:00~08:15:00
需求分析:
- 如何按照不同的时间段将目标数据筛选出来?
- 目标数据筛选出来后怎么拿到当前时间上个班次的数据?
需求实现:
由于仅仅考虑当前时间的上个班次,因此对当前时间来说,确定上个班次的时间段筛选数据即可,有三个班次,需要做大量判断。考虑到班次是固定的,时间跨度上来说凌晨的班次会指向昨天的下午班的班次数据,因此可以根据当前时间对三班的时间进行固定,每班8个小时,查出上一班,上上一班和上上上班次的数据,这样根据时间排序,取出最近班次的数据即可。
首先筛选三班的数据:
| SELECT ID, NAME, RATE * 100 RATE, DAY, TYPE, SG_WORKSHOP_CODE, 'class' AS "time_type" FROM LZ_CLASS_STOCK_REPORT WHERE day > to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 08:15:00', 'YYYY-MM-DD hh24:mi:ss' ) AND day <= to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 16:15:00', 'YYYY-MM-DD hh24:mi:ss' ) OR day > to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 16:15:00', 'YYYY-MM-DD hh24:mi:ss' ) AND day <= to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 00:15:00', 'YYYY-MM-DD hh24:mi:ss' ) OR day > to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 00:15:00', 'YYYY-MM-DD hh24:mi:ss' ) AND day <= to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 08:15:00', 'YYYY-MM-DD hh24:mi:ss' ) ) ORDER BY day DESC |
这样就查出了上一班,上上一班和上上上班次的数据。
接着查找符合目标查询条件以及控制筛选时间段(上一班)的数据:
| SELECT ID, NAME, RATE * 100 RATE, DAY, TYPE, SG_WORKSHOP_CODE, 'class' AS "time_type" FROM LZ_CLASS_STOCK_REPORT WHERE SG_WORKSHOP_CODE = '10005196' AND TYPE = 2 AND day > SYSDATE - 2 / 3 |
最后取两者交集,总的sql如下:
| SELECT * FROM ( SELECT ID, NAME, RATE * 100 RATE, DAY, TYPE, SG_WORKSHOP_CODE, 'class' AS "time_type" FROM LZ_CLASS_STOCK_REPORT WHERE SG_WORKSHOP_CODE = '10005196' AND TYPE = 2 AND day > SYSDATE - 2 / 3 INTERSECT SELECT ID, NAME, RATE * 100 RATE, DAY, TYPE, SG_WORKSHOP_CODE, 'class' AS "time_type" FROM LZ_CLASS_STOCK_REPORT WHERE day > to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 08:15:00', 'YYYY-MM-DD hh24:mi:ss' ) AND day <= to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 16:15:00', 'YYYY-MM-DD hh24:mi:ss' ) OR day > to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 16:15:00', 'YYYY-MM-DD hh24:mi:ss' ) AND day <= to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 00:15:00', 'YYYY-MM-DD hh24:mi:ss' ) OR day > to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 00:15:00', 'YYYY-MM-DD hh24:mi:ss' ) AND day <= to_date( to_char( SYSDATE - 1 / 3, 'YYYY-MM-DD' ) || ' 08:15:00', 'YYYY-MM-DD hh24:mi:ss' ) ) ORDER BY day DESC |
当前时间是
![]()
查询出的数据应该是08:15:00~16:15:00之间的数据,即当前班次上一班的数据。测试一下:
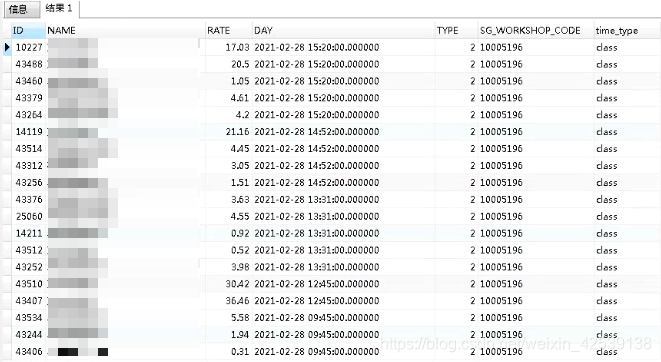
需求实现完成。
这篇关于Oracle三班倒分时段查询数据的一种实现方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






