本文主要是介绍Hoplite: Efficient and Fault-Tolerant Collective Communication for Task-Based Distributed Systems,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 问题
- 设计
- workflow
- Object Directory Service
- Receiver-Driven Collective Communication
- Broadcast
- Reduce
- Fault-Tolerant Collective Communication
- Broadcast
- Reduce
问题
首先介绍基于任务的分布式系统,其有两个优势。第一,表达异步动态计算通信模式比较简单。一个基于任务的系统实现了一个动态的任务模型:调用者动态地调用任务 A,任务 A 直接返回一个 object future (一个对最终返回值的引用)。通过传递 future 作为参数,调用者能够在 A 完成之前指定一个使用 A 的返回值的任务 B。基于任务的系统负责调用工作节点执行任务 A 和任务 B,并在对应的工作节点之间把 A 的结果传输给 B。第二,错误容忍性能够被透明地提供。当一个任务失败时,基于任务的系统快速地重新构造失败任务的状态并且恢复执行。其他运行良好的节点不需要回滚,所以恢复代价很低。在这种系统中,有效率的集合通信非常关键。
在传统的集合通信中,分布式应用必须在运行时之前指定通信模式。但是对于基于任务的分布式系统,在运行时之前,参与集合通信的任务集合和数据对象都是未知的。而且,在同步的集合通信中,一个进程失败会导致其他进程悬挂。
此论文设计了 Hoplite,实现了基于任务的分布式系统中的高效集合通信。
设计
作者设计了 Hoplite,核心点有两个:1) Hoplite 在任务和对象到达时实时计算数据传输调度,并利用细粒度流水线高效地执行数据传输调度。2) Hoplite 在检测到故障时动态调整数据传输调度,以减轻故障任务对集合通信的影响。
workflow
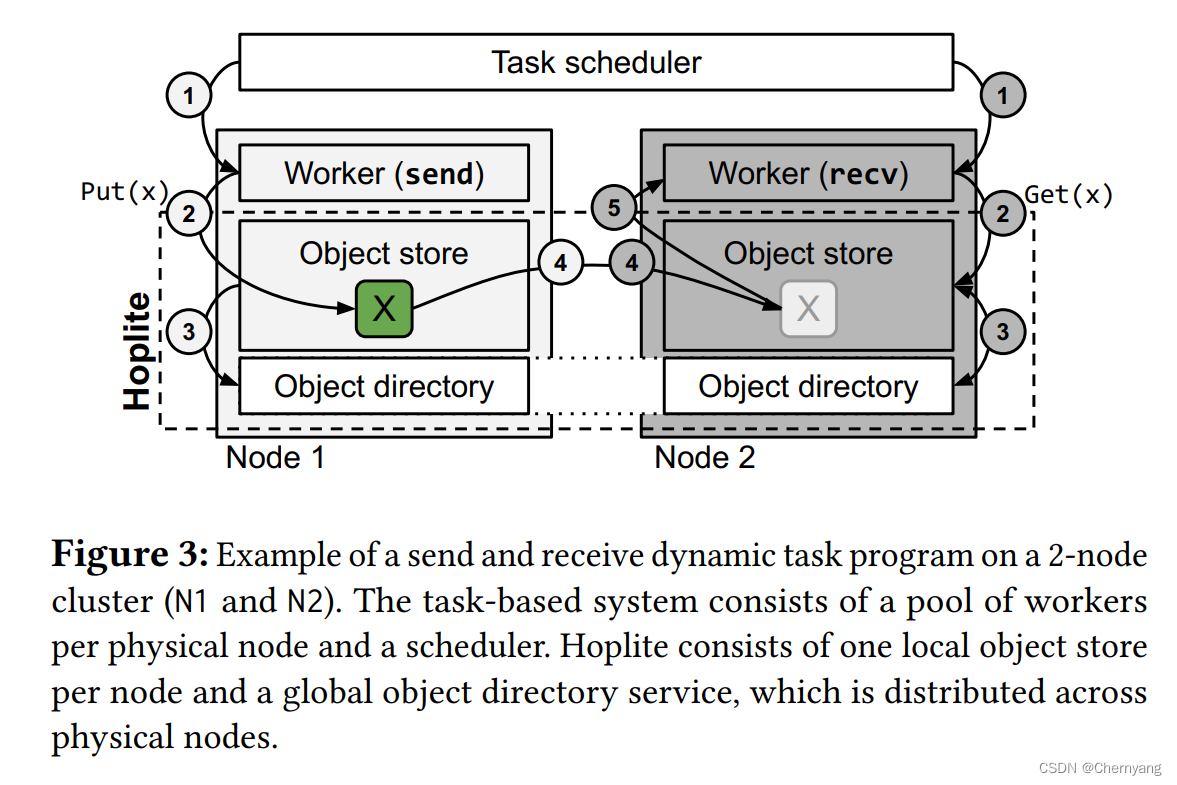
- 调度器选择发送节点和接收节点开始工作
- 发送节点调用Put函数将传输对象放入Object store,接收节点调用Get接收对象(当前阻塞)
- 发送节点的Object store将传输对象的位置发到Object directory中,接收节点在Object directory中查询该对象的位置(只要Put函数被调用,发送节点就发送位置,方便下面的流水线操作)
- 传输对象开始在发送节点和接收节点之间传输(流水线执行:当发送节点的Object store仅有一部分对象内容时,就可开始向接收节点的Object store发送)
- 接收节点开始从其Object store中获取对象(同上,也可以流水线执行)
Object Directory Service
在Object Directory Service中保留对象的两个信息:1. 对象的大小,2. 位置信息:节点IP的列表和目前该节点中的对象的状态(单一位表示,指示节点是否有完整的对象)
在两种情况下,节点给object directory service发送位置,1. 节点通过Put创建对象时,2. 节点从远程节点拷贝对象时。每种情况下,节点通知object directory service两次,1. 对象将要在局部store中创建时,2. 完整对象准备好时。目的是,广播和归约时更偏向使用有完整对象的object store。
对于小于64KB的对象,由于查询对象位置会引入不小的开销,因此这些对象直接缓存在object directory service中。当有节点来查询时,直接返回该对象。
Receiver-Driven Collective Communication
Broadcast
基于任务的分布式系统中的广播具有挑战性,原因是不知道这些接收任务在哪里以及何时进行。此文使用较早收到对象的节点作为中间节点,构造一棵广播树。
当某个接收节点R想要得到一个远程对象时,首先检查本地是否已经存在此对象或者是否有正在运行的请求,如果存在,那么等待。否则,R请求object directory service获取位置,object directory service首先尝试返回一个有完整拷贝的位置,如果没有,那么返回一个持有局部拷贝的位置。
当位置查询返回时,R首先移除返回的位置,然后立刻把自己的位置加到directory中作为一个局部的拷贝(此时R可以作为发送者流水线地传输对象)。一旦数据传输完成,R把发送者的位置加回directory并把自己的位置标记为有完整拷贝的位置。这个操作确保一个节点一次只能发送给一个接收者,缓和了单一节点的瓶颈。
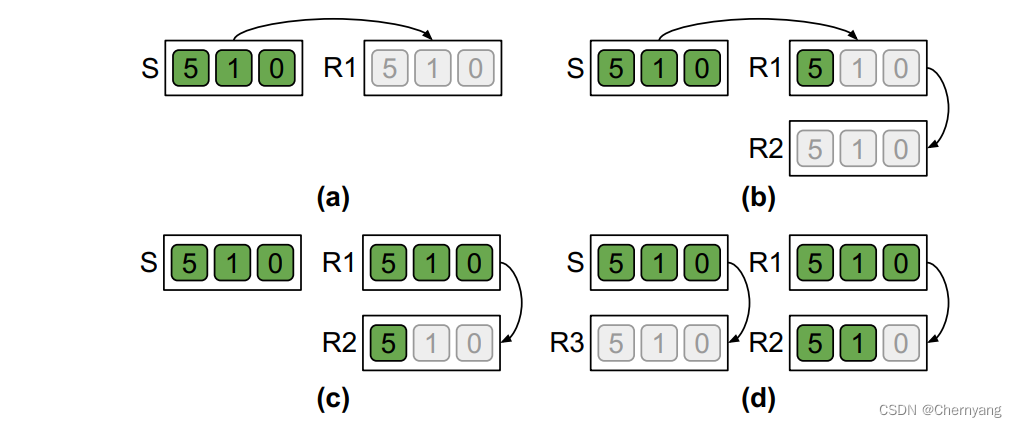
Reduce
Hoplite采用了一种树结构的归约算法,问题是使用什么类型的树(树的度是多少)。
根据计算,总的归约时间T可以总结成下面的公式:
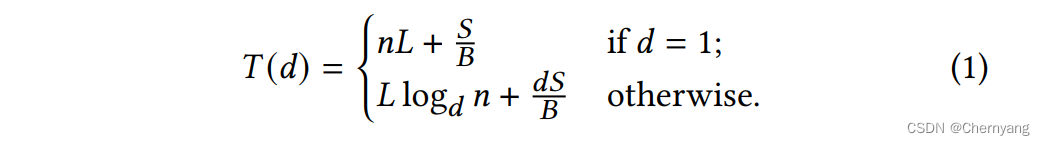
其中n时需要归约的对象数量,L是网络延迟,B是网络带宽,S是对象的大小,d是树的度。需要注意的是,归约也使用上文提到的流水线操作,即中间节点可以发送部分归约的对象给下一节点。总之,需要做的是,选择d来最小化总归约时间T(d)。
树的构造完全是动态的,考虑了对象的到达顺序。具体来说,构造树中的节点的中序遍历顺序,即为对象的到达顺序。
如果一个任务只想归约所有对象的一个子集(即所有对象中的num_objects个对象),当树中已经有num_objects个对象时,树构造进行即可终止。
与广播相同,归约的实现也是流水线的,例子如下:
Fault-Tolerant Collective Communication
容错的目的是:参与集合通信的一个节点故障不能阻塞整体的运行,在恢复后可以重新加入。
Broadcast
当一个发送者故障被接收者检测到后,接收者立刻找到另一个发送者,新的发送者只需发送接收者没有的对象内容。故障节点恢复后可以透明地加入广播,只需调用Get得到同样的对象即可。
如此实现会触发循环依赖,有可能两个节点从彼此取同样的对象。这是因为,当一个接收者R定位一个替代的发送者时,object directory可能返回从R获取对象的另一个节点的地址。为了避免循环依赖,需要跟踪节点的Get的所有依赖,即它的所有上游节点。如果一个发送者发生故障,接收者R只从不依赖R的发送者那里接收对象。

Reduce
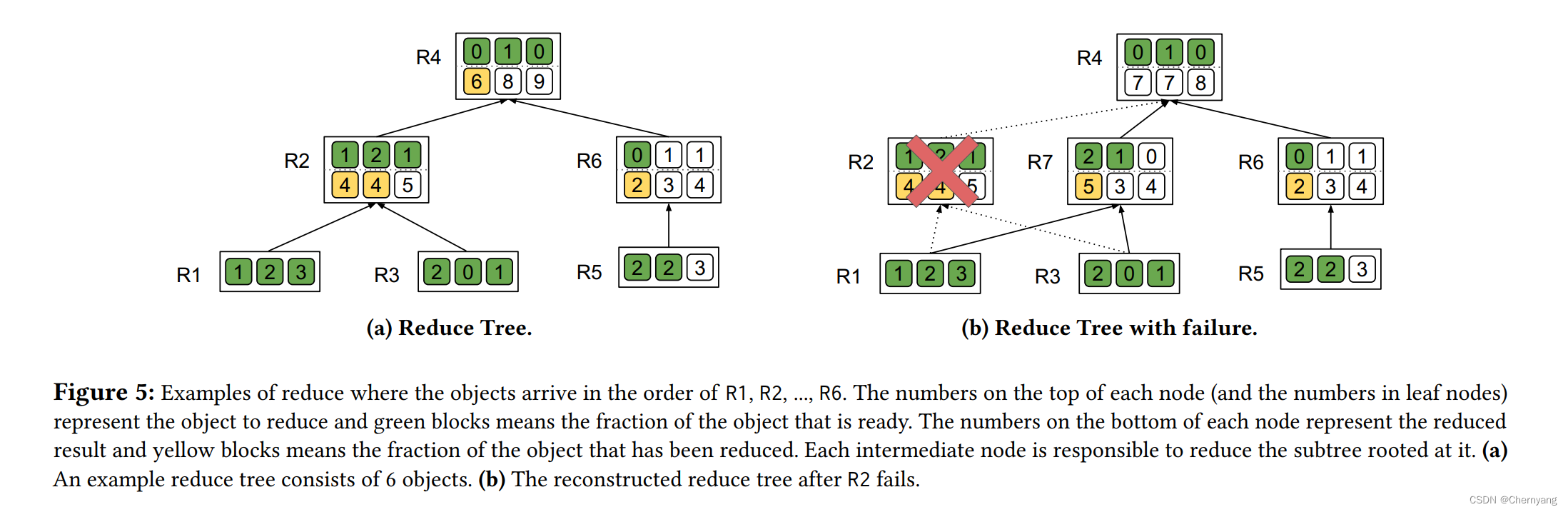
在Reduce过程中,当一个任务发生故障,这个节点立即被从树中移除,并被下一个准备好的源节点代替,它的所有祖先节点中的归约对象都会被清除。
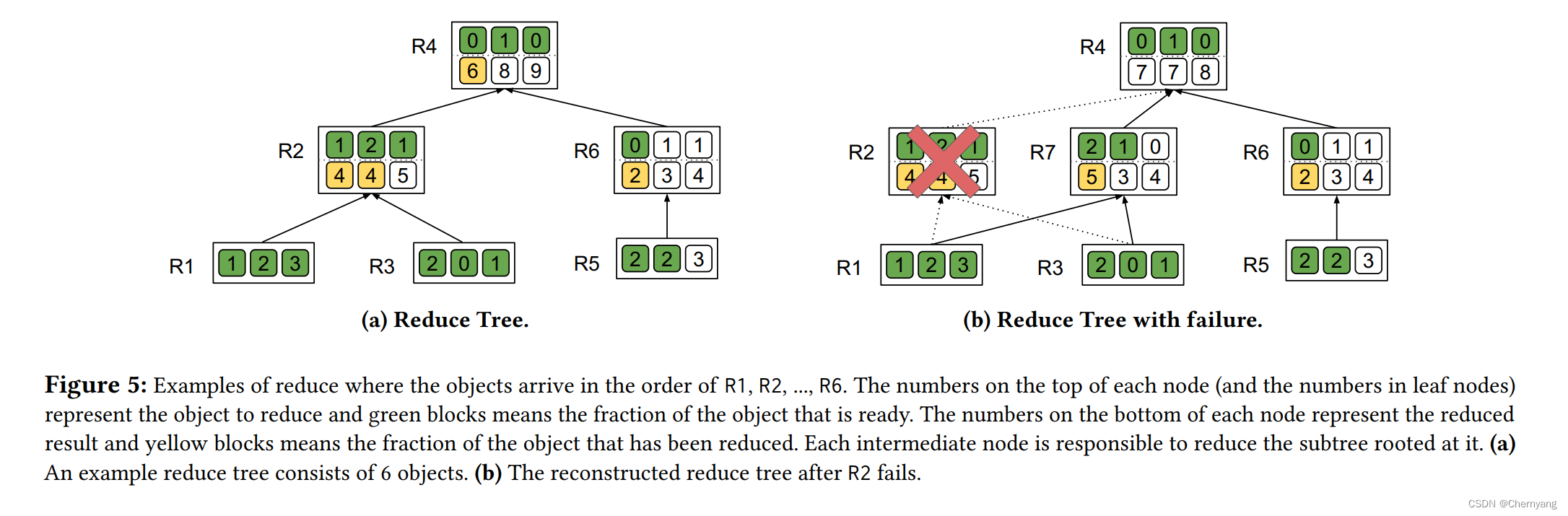
对于上图的例子,此任务只需归约10个对象中的6个,R2在R7到达之后恢复。R7替换了R2在树中的位置(R7也可以是重新加入的R2)。R4必须清除归约的对象。
这篇关于Hoplite: Efficient and Fault-Tolerant Collective Communication for Task-Based Distributed Systems的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)



