本文主要是介绍【大数据基础平台】星环TDH社区集群版本部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🦄 个人主页——🎐开着拖拉机回家_大数据运维-CSDN博客 🎐✨🍁
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
感谢点赞和关注 ,每天进步一点点!加油!
目录
一、概述
二、环境配置
三、安装Manager
四、配置集群
五、安装服务
六、基本配置
6.1 开启安全
6.2 安装TDH客户端
6.3 集群外使用hadoop client
6.3.1 使用hadoop/hdfs
6.3.2 使用hbase shell
6.3.3 beeline访问hive
一、概述
TDH企业级一站式大数据基础平台致力于帮助企业更全面、更便捷、更智能、更安全的加速数字化转型。通过数年时间的打磨创新,已帮助数千家行业客户利用大数据平台构建核心商业系统,加速商业创新。为了让大数据技术得到更广泛的使用与应用从而创造更高的价值,依托于TDH强大的技术底座,星环科技推出TDH社区版(Transwarp Data Hub Community Edition)版本,致力于为企业用户、高校师生、科研机构以及其他专业开发人员提供更轻量、更简单、更易用的数据分析开发环境,轻松应对各类人员数据分析需求。
社区版官网:TDH社区版-TDH Community Edition-星环科技
下载
官网安装手册:星环社区版安装手册
安装视频:星环社区版安装视频
二、环境配置
配置JDK
yum install bash-completion lrzsz tree vim wget net-tools -ymkdir -p /usr/java
tar -zxvf jdk-8u162-linux-x64.tar.gz -C /usr/javavim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_162
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/binsource /etc/profile
java -version关闭防火墙和 selinux
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
# 临时关闭
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config安装chrony
yum install chrony -y
# 修改chrony配置文件指定NTP源为阿里NTP
sed -r -i 's?^pool.+iburst?pool ntp.aliyun.com iburst?' /etc/chrony.conf
# 重启chrony服务
systemctl restart chronyd
# 开机自动启动chrony服务
systemctl enable chronyd
# 查看时间服务器状态
chronyc sources -v主机名映射
/etc/hosts192.168.2.114 tw-manager
192.168.2.115 tdh-node01
192.168.2.116 tdh-node02磁盘容量

三、安装Manager
解压安装包,然后运行Web Installer使用图形化界面安装
tar xvzf TDH-Platform-Community-Transwarp-9.3.1-X86_64-final.tar.gz
cd transwarp-9.3.1-X86_64-final
./install
登录如下显示 的web 地址

通过浏览器访问管理节点,进入Web Installer界面

同意

选择继续

推荐默认端口“8180” ,下一步

安装Manager需要一个包含对应版本操作系统的资源库(repo)
【知识分享】安装Manager时如何配置RPM仓库
centos-7-os-x86_64安装包下载_开源镜像站-阿里云
Index of /centos/7/os/x86_64/

您进行选择后,系统会清理资源库缓存:

资源库缓存清理完毕后,系统会自动开始安装和配置Transwarp Manager

Manager安装完成,可以访问提示的安装地址并使用默认的用户名/密码(admin/admin)去登录管理界面继续接下来的配置。

四、配置集群
默认账号密码为 admin

接受最终用户协议才可以进行进一步

需要给您的集群设置一个名字。输入集群名字后点击“下一步”

如果配置集群中的节点可以通过用主机名互相访问,用户必须配置有效的DNS服务器或/etc/hosts文件。否则请选择需要管理工具配置/etc/hosts,Transwarp Manager会相应为您配置/etc/hosts文件,然后添加节点。
- NTP配置

编辑机柜,默认下一步

默认下一步

选择添加节点

添加安装的节点服务器

我选择SSH访问权限配置,输入用户名和密码

选中已添加的节点,下一步

配置完成后,点击“下一步”进行节点最终检查,系统将为您进行检查,如果有检查项出现告警,请点击+号查看具体说明并进行对应项的处理。

确定

系统会开始自动添加节点,添加节点的过程会进行一段时间,成功后您会看到成功页面。

五、安装服务
服务需要上传单独的tar,选择上传产品,完后上传后 点击下一步

点击 上传按键,并在以下弹出窗口中选择产品包的位置(可同时上传多个软件包)

上传中

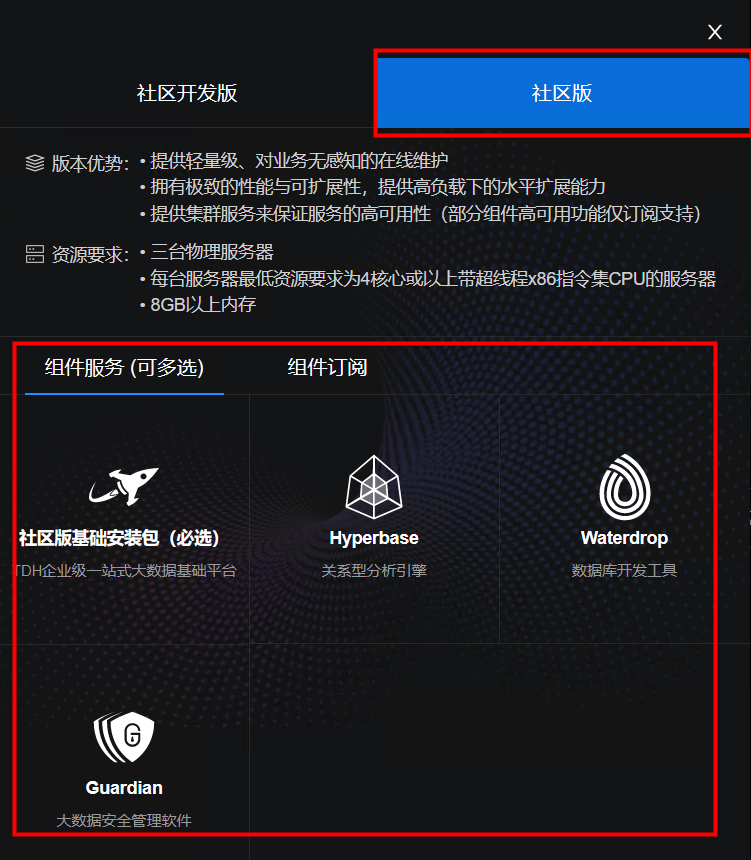
选择产品组件安装
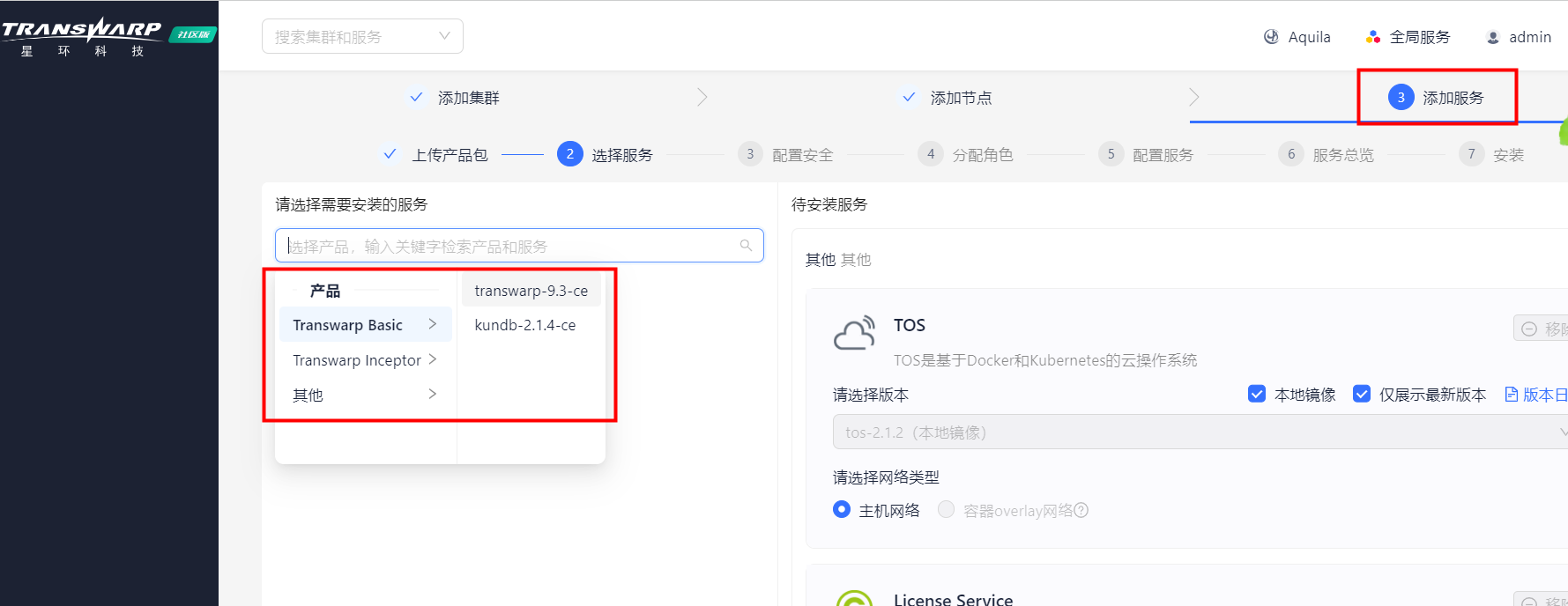
HDFS,YARN,Zookeeper 添加



简单认证模式,下一步
下一步

下一步
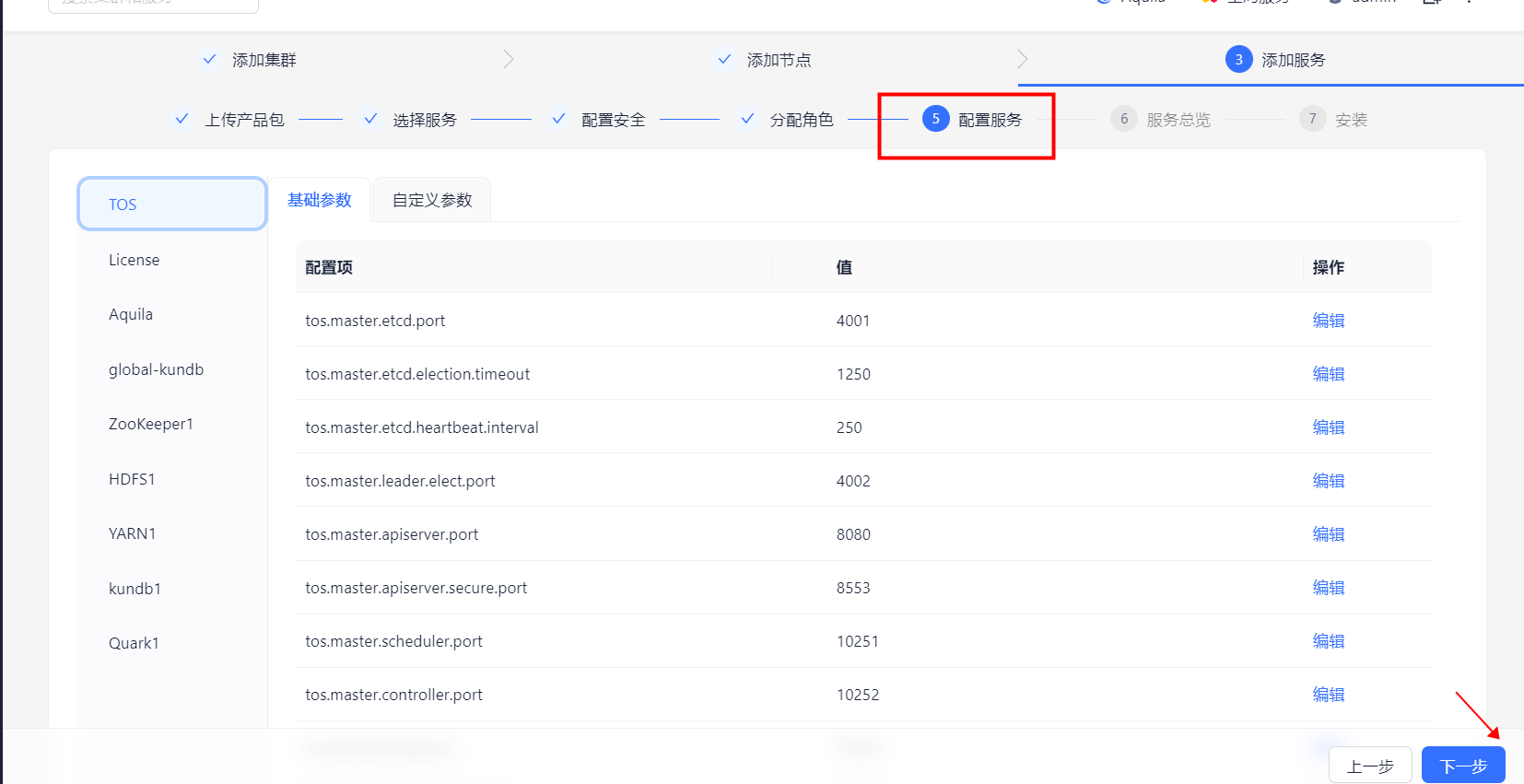

确定安装

安装中
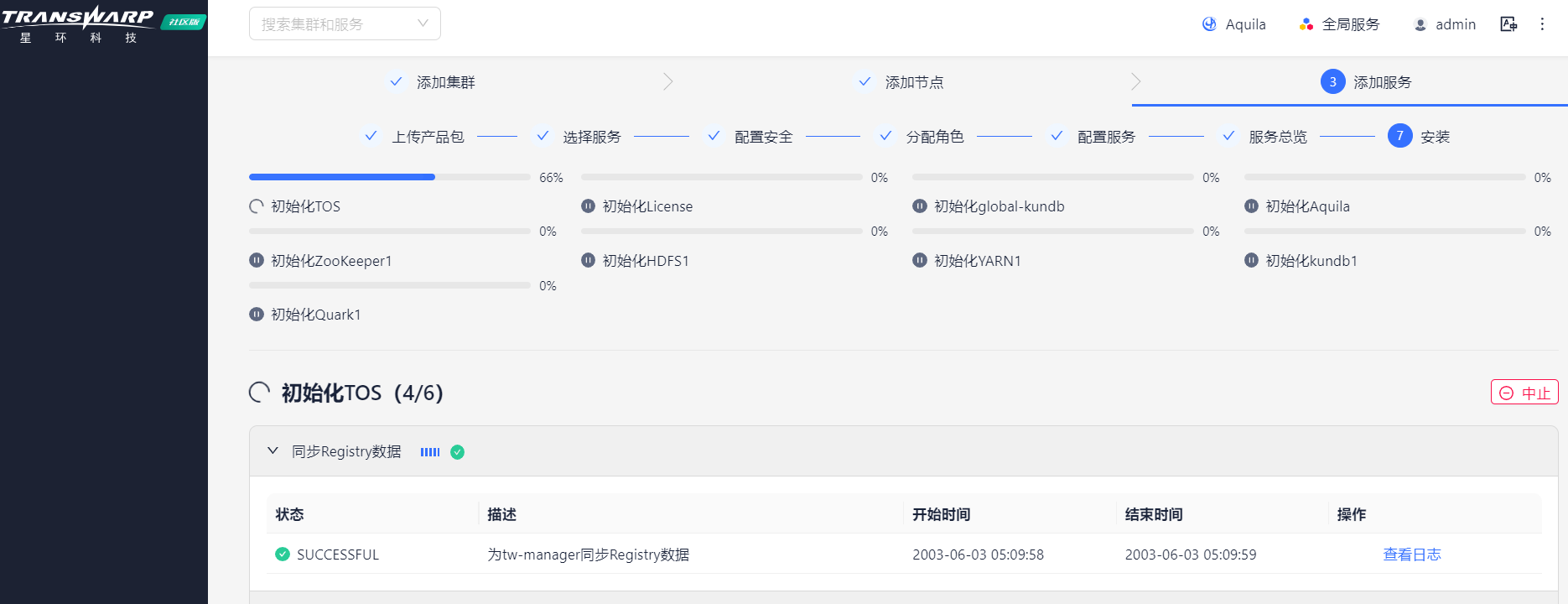
安装完成


全局服务
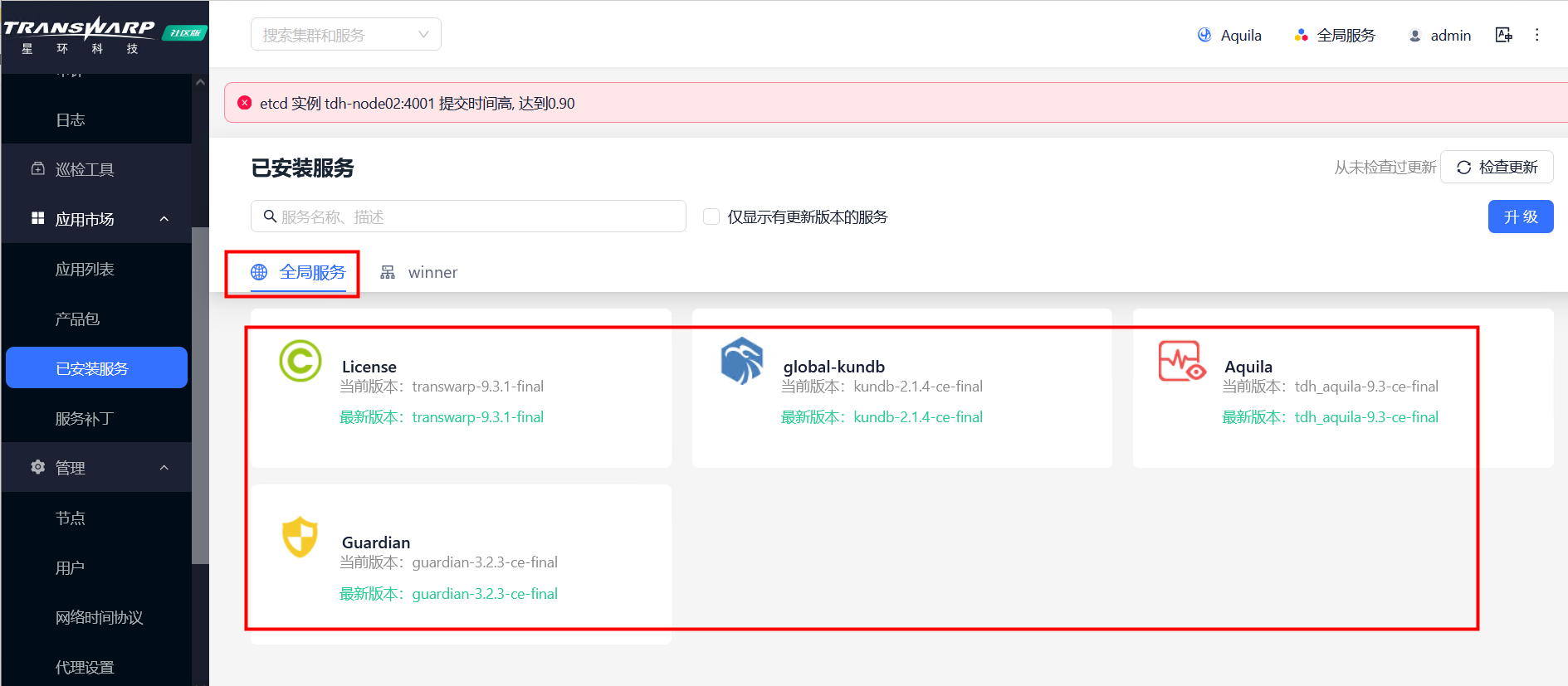
集群已安装的组件

组件监控

六、基本配置
6.1 开启安全
进入全局服务下的Guardian服务详情页,选择一键开启安全


输入密码

完成配置刷新

6.2 安装TDH客户端
Manager页面下载客户端,选择“随产品包上传”下载tdh-client。

选择所有组件 ,确定

下载 后上传/opt路径解压
tar -xvf tdh-client.tar
完成后即可使用TDH-Client。 使用TDH-Client前还需设置JAVA_HOME环境变量。

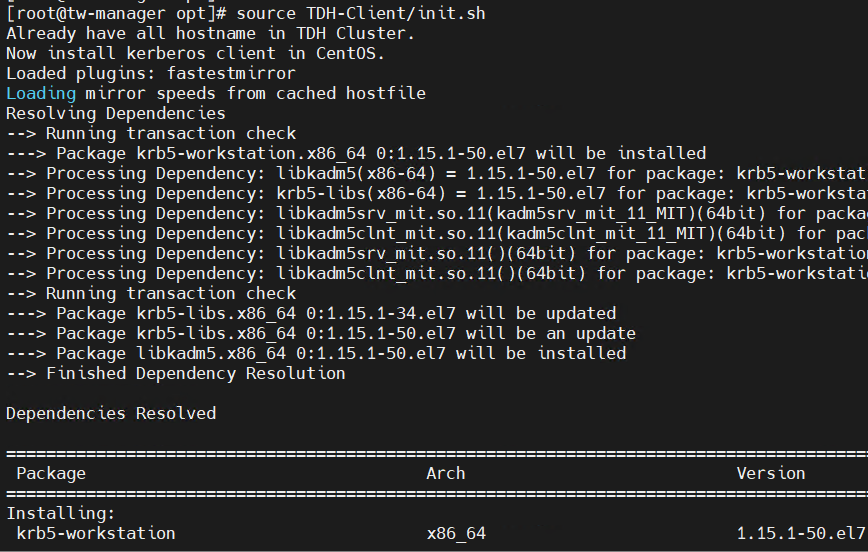
执行脚本,请执行位于目录TDH-Client内的脚本init.sh。
source TDH-Client/init.sh您可以以任何用户执行该脚本,但是我们建议以root用户身份执行。当以其他用户身份执行时,需要输入root密码。
注意 ,用户必须使用source命令执行该脚本。 当新建一个连接到服务的终端session时,都需要重新执行source init.sh,bash init.sh 和 ./init.sh 都不起作用。
6.3 集群外使用hadoop client
首先您需要保证JAVA_HOME设置正确。已准备好TDH-Client(TDH-Client文件夹下有init.sh),下方假定TDH-Client存储路径为:/opt
6.3.1 使用hadoop/hdfs
# 查看 principal
klist -kt /opt/TDH-Client/kerberos/hdfs.keytab
# 认证
kinit -kt /opt/TDH-Client/kerberos/hdfs.keytab hdfs@TDH
创建文件夹和上传文件测试

6.3.2 使用hbase shell
在guardian上下载hbase租户的keytab,假定路径是/tmp/hbase.keytab /opt/TDH-Client/kerberos/hbase.keytab, 如果没有认证直接进入 命令报错如下:

klist -kt /opt/TDH-Client/kerberos/hbase.keytab
确认后执行下方命令方可使用.
source /opt/TDH-Client/init.sh
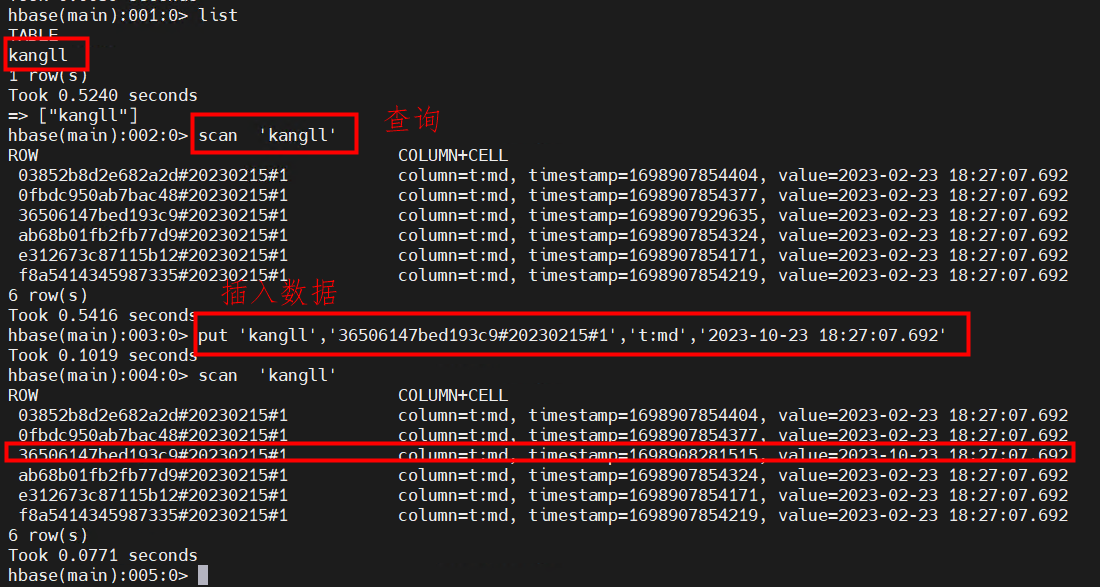
kinit -kt /opt/TDH-Client/kerberos/hbase.keytab hbase@TDHhbase shel 进入命令行,创建表kangll , put 数据
create 'kangll',{NAME=>'d',VERSIONS => 1,DATA_BLOCK_ENCODING => 'FAST_DIFF',COMPRESSION => 'SNAPPY'},{SPLITS=> ['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}
alter 'kangll', {NAME => 't',VERSIONS => 1,DATA_BLOCK_ENCODING => 'FAST_DIFF',COMPRESSION => 'SNAPPY'},{SPLITS=> ['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}put 'kangll','e312673c87115b12#20230215#1','t:md','2023-02-23 18:27:07.692'
put 'kangll','f8a5414345987335#20230215#1','t:md','2023-02-23 18:27:07.692'
put 'kangll','ab68b01fb2fb77d9#20230215#1','t:md','2023-02-23 18:27:07.692'
put 'kangll','0fbdc950ab7bac48#20230215#1','t:md','2023-02-23 18:27:07.692'
put 'kangll','03852b8d2e682a2d#20230215#1','t:md','2023-02-23 18:27:07.692'
put 'kangll','36506147bed193c9#20230215#1','t:md','2023-02-23 18:27:07.692'查询成功

6.3.3 beeline访问hive
source /opt/TDH-Client/init.sh
kinit -kt /opt/TDH-Client/kerberos/hive.keytab hive@TDH通过 Beeline 命令行连接
beeline -u 'jdbc:hive2://192.168.3.115:10000/default;principal=hive/tw-manager@TDH;kuser=hive@TDH;keytab=/opt/TDH-Client/kerberos/hive.keytab;auth=kerberos;krb5conf=/etc/krb5.conf'创建表时,若没有指定存储格式,默认为TextFile,是不支持插入单行或多行的,我们使用select 的方式插入一条数据 作为测试。

Guardian添加winner_spark 用户,kerytab文件自动创建,Guardian页面上面给winner_spark 用户授HBase, HDFS的使用权限。

参考文档地址:
星环科技 | TranswarpCloud
这篇关于【大数据基础平台】星环TDH社区集群版本部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








