本文主要是介绍Deep Learning 最优化方法之SGD,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文是Deep Learning 之 最优化方法系列文章的SGD方法。主要参考Deep Learning 一书。
整个优化系列文章列表:
Deep Learning 之 最优化方法
Deep Learning 最优化方法之SGD
Deep Learning 最优化方法之Momentum(动量)
Deep Learning 最优化方法之Nesterov(牛顿动量)
Deep Learning 最优化方法之AdaGrad
Deep Learning 最优化方法之RMSProp
Deep Learning 最优化方法之Adam
在这里SGD和min-batch是同一个意思,抽取m个小批量(独立同分布)样本,通过计算他们平梯度均值。后面几个改进算法,均是采用min-batch的方式。
先上一些结论:
1.SGD应用于凸问题时,k次迭代后泛化误差的数量级是O(1/sqrt(k)),强凸下是O(1/k)。2.理论上GD比SGD有着更好的收敛率,然而[1]指出,泛化误差的下降速度不会快于O(1/k)。鉴
于SGD只需少量样本就能快速更新,这远超过了缓慢的渐进收敛,因此不值得寻找使用收敛快O(1/k)。3.可能由于SGD在学习中增加了噪声,有正则化的效果4.在某些硬件上使用特定大小的数组时,运行时间会更少。尤其是在使用GPU时,通常使用2 的幂
数作为批量大小可以获得更少的运行时间。一般,2 的幂数的取值范围是32 到256,16 有时在尝试大模型时使用。5.如果批量处理中的所有样本可以并行地处理(通常确是如此),那么内存消耗和批量大小会
正比。对于很多硬件设施,这是批量大小的限制因素
再看看算法:

没啥太大难度,需要注意的是有必要随迭代步数,逐渐降低学习率。一种常见从做法是线性衰减学习率,直到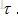
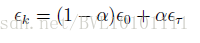
其中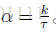
参考文献:
1.Cramér, H. (1946). Mathematical methods of statistics. Princeton University Press. 118, 251
这篇关于Deep Learning 最优化方法之SGD的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!