本文主要是介绍复旦大学公开课:深度学习的基本原理、常用算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习资料:https://www.bilibili.com/video/BV1Bt4y1U7xq?from=search&seid=15892801515091723536
I believe in the importance of continuous learning!Just do your best ! Maybe good result will come soon !
TimeLine
- 2020.9.24: 目前为止,了解了深度学习的一个基本流程和基础概念,尝试去阅读一些paper
深度学习的方式
- 在input的刺激下,不断改变网络的连接权值
神经元的作用
- 对输入空间进行线性划分
学习训练算法
- 就是训练权值
前馈型神经网络(BP算法,也叫BP神经网络)
- 连接方式上是全连接;输入层(数值型数据,激活函数输入==输出),隐层,输出层

- 用于分类,找特征值
- x和w是向量,b是偏置值,f叫激活函数,负责通过输入的加权和,得到一个输出,输出给下一层神经元

- 训练算法
- 批量训练处理算法:
- 每一个样本都跑一遍神经网络,最小化 总损失函数(最小平方误差准则),通过梯度下降法对总进行权重和偏置,这叫一次poach

- 每一个样本都跑一遍神经网络,最小化 总损失函数(最小平方误差准则),通过梯度下降法对总进行权重和偏置,这叫一次poach
- 随机梯度下降法:
- 随机挑一小批的样本,每一个随机样本,都对权重进行修正;
- 基于 P处理 + 随机样本
- 批量训练处理算法:
- 梯度消失:梯度接近于0
神经网络常见的激活函数
- Sigmoid

- 梯度容易消失,在x很小或者x很大的时候会出现“梯度消失”;好处就是会限制在[0,1]且处处可导
- tanh:把Sigmoid的y范围拉伸到[-1,1],也不太行,“梯度消失”
- ReLu:分段函数

- Leaky ReLu
- 损失函数:交叉熵 (用于二分类问题)

- 激活函数的特性:非线性,可微分,单调,输出范围可控,计算简单,
- 学习率(学习步长)的确定方式
- 固定步长
- 用经验瞎猜
- 动态,在训练初期,可以让步长大一点
- Adam算法,也是动态的
- 过拟合:训练样本还行,但是测试样本有问题。根本原因是模型复杂,节点太多
- 解决方案
- 惩罚性成本函数
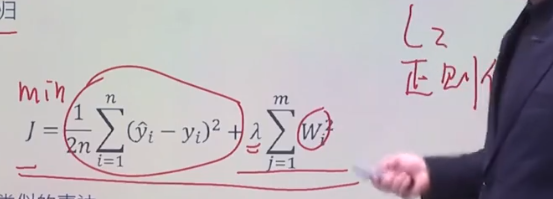
- DropOut 随机丢失
- 尽早终止:每各n个epoch,测试一下检验样本对于模型的损失函数是多少,如果变大的,则说明该停止,已经过拟合了
- 动量,有点像 模拟退火
- 惩罚性成本函数
- 解决方案
神经网络的作用
- 信用卡欺诈
- 手写体识别
- 总体流程:input data→hidden layer→output→gradient descent optimization→check for overfitting
深度学习的场合
- 银行客户流失预测(BP网络)
- 对于连续性,数值型的数据,归一化(0,1);对于离散型属性(true or false),神经网络不能直接处理,因此通过0和1代表其数值,也叫One-Hot编码
- 数据分成两个集:训练样本集 + 测试样本集,上面有提到过
- 标签数据:用户是否流失

- layer3输出层用的是softmax而不是隐层的sigmoid

这篇关于复旦大学公开课:深度学习的基本原理、常用算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





