本文主要是介绍压缩视频增强论文Multi-Frame Quality Enhancement for Compressed Video阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文来源:CVPR2018
论文链接:Multi-frame Quality Enhancement for Compressed Video | IEEE Conference Publication | IEEE Xplore
项目链接:GitHub - ryangBUAA/MFQE
作者:北航徐迈团队
概述
输入的多帧序列先经过一个SVM来对PQF进行检测,所谓PQF(峰值质量帧)就是比相邻几帧质量都高的帧,对于PQF,不需要相邻帧的信息,作者采用修正的DS-CNN来进行增强(DS-CNN是ICME2017提出的一个压缩视频增强网络)。对于non-PQF,先用运动补偿网络对与其相邻的两个PQF进行运动补偿,然后用一个质量增强网络对三帧进行融合增强得到non-PQF的增强结果。
Abstract
在过去的几年里,人们已经见证了应用深度学习来提高压缩图像/视频质量的巨大成功。现有的方法主要集中在提高单个帧的质量上,而忽略了连续帧之间的相似性。在本文中,我们研究了在压缩视频帧之间存在严重的质量波动,通过使用邻域高质量帧可以改善低质量帧的质量,这种方法叫做多帧质量增强(MFQE)。因此,本文提出了一种用于压缩视频的MFQE方法,作为这一方向的首次尝试。在我们的方法中,我们首先开发了一个基于支持向量机(SVM)的检测器来定位压缩视频中的峰值质量帧(PQF)。然后,设计了一种新的多帧卷积神经网络(MF-CNN),以非PQF及其最近的两个PQF作为输入,提高压缩视频的质量。MF-CNN通过运动补偿子网(MC-subnet)补偿非PQF和PQF之间的运动。随后,质量增强子网(QE-subnet)借助其最近的PQF来减少非PQF的压缩伪影。最后,实验验证了MFQE方法在提高压缩视频质量方面的有效性和通用性。我们的MFQE方法的代码可以在https://github.com/ryangBUAA/MFQE.git获取。
1. Introduction
balabala
然而,当处理单个帧时,所有现有的质量增强方法都没有利用相邻帧中的信息,因此它们的性能在很大程度上受到限制。如图1所示,压缩视频的质量在各帧之间急剧下降。因此,可以使用高质量帧(即,峰值质量帧,称为PQFs)来增强其相邻的低质量帧(non-PQFs)的质量。这可以看作是多帧质量增强(MFQE),类似于多帧超分辨率[20,3]。

提出了一种用于压缩视频的MFQE方法。特别地,我们首先研究了几乎所有编码标准压缩的视频序列在帧间存在较大的质量变化。因此,有必要寻找可用于提高相邻non-PQFs质量的PQFs。为此,我们训练了一种支持向量机(SVM)作为检测PQFs的无参考方法。在此基础上,提出了一种新的多帧CNN(MF-CNN)结构,该结构以当前帧及其相邻的PQF为输入,来提高质量。我们的MF-CNN包括两个部分,即运动补偿子网(MC-subnet)和质量增强子网(QE-subnet)。运动补偿子网是用来对当前non-PQF和它的PQFs之间的运动进行补偿。质量增强子网拥有时空联合结构,用来提取和合并当前non-PQF和它的补偿PQFs的特征。最后,质量增强子网可以利用相邻PQFs的高质量内容对当前的non-PQF的质量进行提高。如图 1所示,当前non-PQF(帧96)和离它最近的PQFs(帧93和帧97)输入至我们MFQE 方法的MF-CNN,观察结果,non-PQF(帧96)的低质量内容(basketball)的质量能够利用PQFs(帧93和帧97)的高质量相同内容进行改善。并且,图1显示我们的MFQE方法也减轻了质量影响,因为非PQF的质量有了显著的提高。
本文的主要贡献有:(1)分析了各种视频编码标准压缩后视频序列的帧级质量评价(2) 提出了一种新的基于CNN的MFQE方法,该方法利用相邻的PQF来减少non-PQF的压缩伪影。
2. Related works
balabala
3. Quality fluctuation of compressed video
在这个部分,我们分析压缩视频帧之间的质量波动。我们建立一个包括70个未压缩的视频序列的数据,序列均来自Xiph.org [37]和JCT-VC [1]数据集。我们使用各种压缩标准对序列进行压缩,包括MPEG-1 [11], MPEG-2 [28], MPEG-4[29], H.264/AVC [36]和HEVC [31],每一帧的压缩质量用信噪比PSNR来衡量。
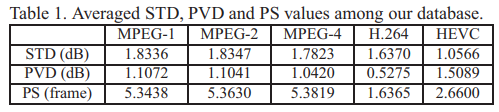
图2显示了不同标准压缩的8种视频序列的信噪比曲线。可以明显看出,压缩视频的质量随着帧数的变化不断地波动。我们更进一步衡量每个压缩视频的帧level质量的标准差(STD),如表1所示,所有5种标准的STD值均超过1dB,是70个压缩序列的平均值。70个序列中最大STD可以达到3.97 dB, 4.00 dB, 3.84 dB, 5.67 dB 和3.34 dB分别对应MPEG-1, MPEG-2, MPEG-4, H.264 和HEVC。这反应了视频压缩之后,帧level质量的显著波动。

此外,图3显示了使用HEVC标准进行压缩,一个序列的帧level的PSNR和主观质量的示例。我们可以从图3中看出,存在频繁交替的PQFs和VQFs。在此,PQFs被定义为质量比前后帧都要高的帧,相反的,VQFs被定义为质量比前后帧都要差的帧。如图3所示,non-PQFs (帧 58-60)除了VQF(帧60)的PSNR,很明显的要低于最近的PQFs(帧57和61),而且non-PQFs (帧 58-60)比最近的PQFs(帧57和61)的主观质量要低。例如:在数字“87”的区域,帧57-61的内容差不多。因此non-PQFs的视觉质量可以用最近的PQFs内容进行改善。

为了进一步研究帧level的质量的“顶峰”和“低谷”,我们对于每个压缩视频序列的PSNR曲线引入了Peak-Valley差值(PVD)和Peak间隔(PS)。如图3的(a)所示,PVD被定义为PQF和离它最近的VQF的PSNR的差值,PS为两个PQFs之间的帧的个数。70个使用不同压缩标准压缩的视频序列的PVD和PS的平均值如表1所示。我们看出,在大多数情况下,平均PVD的值要大于1dB,最近的HEVC标准达到了最大值为1.5dB。这就说明了PQFs和VQFs之间的质量的巨大差异。另外,对于每一种标准的平均PS值大约为5帧或者小于5帧。特别是,在HEVC或者H.264中,平均PS的值小于3帧。这种两个PQFs之间的短距离说明了两个相邻的PQFs的内容是高度相同的。因此PQF中可能存储着邻域non-PQFs中已经失真的有用内容。出于这种想法,我们MFQE方法被提出通过利用最近的PQFs的有用信息提高non-PQFs的质量。
4. The proposed MF-CNN approach
4.1. Framework
图4展示了我们的MFQE方法的框架。在这种MFQE的方法中,我们首先检测那些用于改善其他non-PQFs的质量的PQFs,在实际应用中,在压缩视频质量提升中raw序列通常是不可获得的,因此不能通过对比raw序列来辨别non-PQFs和PQFs。因此,我们在这种MFQE中引入了一种无参考PQFs检测器,详情在4.2中。

那些已经被检测到的PQFs的质量可以通过DS-CNN进行增强,因为PQFs相邻的帧是低质量并且不能利用PQFs的优势,因此DS-CNN是增强单帧质量的方法。我们对DS-CNN进行改进,使用参数修正线性单元(PReLU)代替修正线性单元(ReLU)来避免零梯度,并且应用残差学习来提高改善质量的表现力。
对于non-PQFs,使用MF-CNN来利用最近PQFs的有效信息来提高质量(例如:包括前一个和后一个PQFs)。MF-CNN结构由运动补偿子网(MC-subnet)和质量增强子网(QE-subnet)构成。运动补偿子网(MC-subnet)用来补偿相邻帧间的时间运动,具体地说,运动补偿子网(MC-subnet)首先对当前的non-PQFs和最近的PQFs进行了运动预测,然后,根据估计的运动,用空间变换器对距离最近的两个PQFs进行变换。这样的话,当前的non-PQFs和最近的PQFs之间的时间运动就可以被补偿。MC-subnet在4.3中被详细讲述。
最后,质量增强子网(QE-subnet)是一个时空联合结构,将在4.4进行讲述。在质量增强子网(QE-subnet)中,输入当前的non-PQFs和已被补偿的PQFs,然后当前non-PQFs的质量将在已被补偿的PQFs的帮助下进行改善。值得注意的是,在这个MF-CNN中,运动补偿子网(MC-subnet)和质量增强子网(QE-subnet)以端到端的方式联合训练。
4.2. SVM-based PQF detector
在我们的MFQE方法中,训练SVM分类器来实现无参考PQF检测。回想一下,PQF是比相邻帧质量更高的帧。因此,利用当前帧和相邻四帧的特征来检测PQFs。在我们的方法中,PQF检测器遵循无参考质量评估方法[27],从当前帧中提取36个空间特征,每个特征都是一维的。除此之外,还从前两帧和后两帧中提取此类空间特征。基于支持向量机分类器,得到180个一维特征来预测一帧是PQF还是non-PQF。
在我们的SVM分类器中, 定义了输出分类标签,表明了第n帧是PQFs(正样本ln=1)还是non-PQFs(负样本ln=0).我们使用LIBSVM库来训练SVM分类器,可以得到每一帧ln=1的概率,记做pn。在我们的SVM分类器中,我们使用径向基函数(RBF)作为核心。
定义了输出分类标签,表明了第n帧是PQFs(正样本ln=1)还是non-PQFs(负样本ln=0).我们使用LIBSVM库来训练SVM分类器,可以得到每一帧ln=1的概率,记做pn。在我们的SVM分类器中,我们使用径向基函数(RBF)作为核心。
最终,我么可以从SVM分类器中得到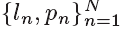 N为视频序列中的总的帧数。在我们的PQF检测器中,我们进一步提炼了根据PQF的先验知识得到的SVM分类器结果,特别的,引入以下两条策略重新精炼PQF检测器的标签
N为视频序列中的总的帧数。在我们的PQF检测器中,我们进一步提炼了根据PQF的先验知识得到的SVM分类器结果,特别的,引入以下两条策略重新精炼PQF检测器的标签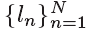 :
:
1)根据PQF的定义,PQFs不可能会连续出现,因此,如果出现以下情况:
![]()
我们设置:
![]()
(也就是说,如果出现了检测器预测出了一个连续PQF序列的情况,强行把此序列中最大值处设置为PQF,其他的改为non-PQF)
2)根据第三章的分析,PQFs通常出现在有限的距离范围内,例如HEVC中的平均PS为2.66帧,因此,我们假设D为两个PQFs之间的最大距离,基于这种假设,如果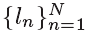 中连续为0的个数(non-PQFs的帧数)大于D:
中连续为0的个数(non-PQFs的帧数)大于D:
![]()
那么我们必须从它中间选择一帧作为PQF
![]()
(选择连续0中的最大值处作为PQF)
对做如上精简之后,我们的PQFs检测器就可以在压缩视频序列中定位non-PQFs和PQFs了。
4.3. MC-subnet
PQFs被检测出来之后,non-PQFs的质量就可以利用附近的PQFs的有效信息进行改善。然而,时间运动仍然存在于non-PQFs和PQFs之间。因此,我们使用MC-subnet对帧之间的时间运动进行补偿。下面将介绍MC-subnet的结构和训练策略:
Architecture.
Caballero等人对多帧超分辨率提出了空域运动补偿变换器(STMC)方法,如图5所示,这种STMC方法采用了卷积层来估计x4和x2的下缩放运动矢量映射,定义为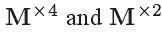 。在
。在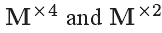 中,下缩放是通过采用一些2步长的卷积层来实现的。卷积层的更详细的细节在参考文献[3]
中,下缩放是通过采用一些2步长的卷积层来实现的。卷积层的更详细的细节在参考文献[3]

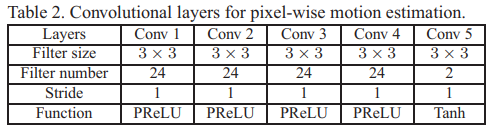
这种下缩放运动估计对处理大尺寸的运动十分有效,但是由于下缩放,运动矢量估计的精度就被大大降低了,因此,除了STMC,在我们的MC-subnet中,进一步增加了对于pixel-wise的运动估计的卷积层,其中不包括任何下缩放处理。pixel-wise运动估计的卷积层可以用表2进行描述。
正如图5所示,STMC的输出包括×2下缩放MV映射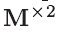 和对应的已补偿的PQF——
和对应的已补偿的PQF——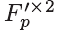 。将non-PQFs和原始的PQFs串联输入到pixel-wise运动估计卷积层中,然后产生pixel-wise MV 映射,记做M。值得注意的是,MV的映射M包括两个通道水平映射Mx和垂直映射My。这里,x和y是每个像素的水平和垂直索引。给定了Mx和My,PQF进行变换用来对时间运动进行补偿。让被压缩的PQFs和non-PQFs分别作为Fp和Fnp。补偿后的PQF即F’p可以被表示为:
。将non-PQFs和原始的PQFs串联输入到pixel-wise运动估计卷积层中,然后产生pixel-wise MV 映射,记做M。值得注意的是,MV的映射M包括两个通道水平映射Mx和垂直映射My。这里,x和y是每个像素的水平和垂直索引。给定了Mx和My,PQF进行变换用来对时间运动进行补偿。让被压缩的PQFs和non-PQFs分别作为Fp和Fnp。补偿后的PQF即F’p可以被表示为:
![]()
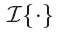 为双线性插值,这是由于Mx(x, y) 和 My(x, y)的值可能为非整数。
为双线性插值,这是由于Mx(x, y) 和 My(x, y)的值可能为非整数。
Training strategy.
由于很难获得MV的ground truth,因此无法直接训练卷积层的运动估计参数。超分辨率工作通过最小化当前帧和相邻被补偿帧之间的MSE来进行训练参数,然而,在我们的MC-subnet中,输入的Fp和Fnp都是带有质量失真的压缩帧。因此当最小化F‘p和Fnp之间的MSE时,MC-subnet要去估计失真的MV,会造成运动估计的不精确。因此,MC-subnet必须要在raw 帧的监督下进行训练。我们使用从运动估计输出的卷积层映射来对PQF的raw 帧(记做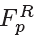 )进行变换,并将被补偿的raw PQF(
)进行变换,并将被补偿的raw PQF(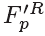 )和raw non-PQF(
)和raw non-PQF(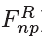 )之间的MSE最小化。MC-subnet的损失函数可以被记做:
)之间的MSE最小化。MC-subnet的损失函数可以被记做:
![]()
其中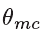 为我们的MC-subnet中的可训练参数。值得注意的是,在测试中补偿运动时,不需要使用到raw 帧的
为我们的MC-subnet中的可训练参数。值得注意的是,在测试中补偿运动时,不需要使用到raw 帧的![]()
4.4. QE-subnet
给定了被补偿的PQFs,non-PQFs的质量可以通过QE-subnet进行改善,QE-subnet为时空联合结构。特别地,和当前的non-PQFs一起,被补偿的前面和后面的PQFs(记做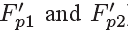 )被输入至QE-subnet中。就这样,三个帧的时间和空间的特点全部被研究和融合。因此,相邻的PQFs的有用信息可以被用来提高non-PQFs的质量。这和基于 CNN的图像\单帧的质量提升方法不同,它仅仅在一帧里面处理空间信息。
)被输入至QE-subnet中。就这样,三个帧的时间和空间的特点全部被研究和融合。因此,相邻的PQFs的有用信息可以被用来提高non-PQFs的质量。这和基于 CNN的图像\单帧的质量提升方法不同,它仅仅在一帧里面处理空间信息。
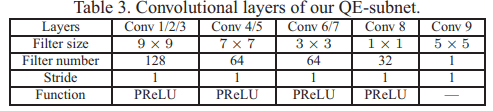
Architecture.
QE-subnet的结构如图6所示。卷积层的具体细节在表3中给出。在QE-subnet中,卷积层conv1,2和3被用来提取输入帧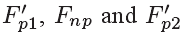 的空域特征。然后为了使用F‘p1的高质量信息,conv4被用来融合Fnp和F‘p1的特征。也就是说,conv1和2的输出被串联并且与conv4卷积。同样的,conv5被用来融合Fnp和F‘p2的特征.conv6/7被用来提取conv4/5的更加复杂的特征。因此,conv6和conv7提取的特征通过conv8非线性映射到另一个空间,重建的残差,记做
的空域特征。然后为了使用F‘p1的高质量信息,conv4被用来融合Fnp和F‘p1的特征。也就是说,conv1和2的输出被串联并且与conv4卷积。同样的,conv5被用来融合Fnp和F‘p2的特征.conv6/7被用来提取conv4/5的更加复杂的特征。因此,conv6和conv7提取的特征通过conv8非线性映射到另一个空间,重建的残差,记做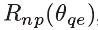 ,在conv9中被重建。non-PQFs的质量增强是通过对输入non-PQFs Fnp加上实现的。这里,
,在conv9中被重建。non-PQFs的质量增强是通过对输入non-PQFs Fnp加上实现的。这里,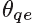 被定义为QE-subnet中的可训练参数。
被定义为QE-subnet中的可训练参数。

Training strategy.
我们的MF-CNN的MC-subnet和QE-subnet都是端到端的联合训练。假设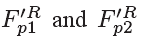 分别被定义为上一个和下一个PQFs的raw帧。MF-CNN的损失函数可以被表示为:
分别被定义为上一个和下一个PQFs的raw帧。MF-CNN的损失函数可以被表示为:
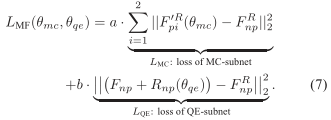
如公式7所示,MF-CNN的损失函数为权重Lmc和Lqe之和,分别为MC-subnet和QE-subnet的损失函数。由于MC-subnet产生的F‘p1和F‘p2是QE-subnet的基础,我们在训练的开始设置a>>b,观察了LMC收敛后的情况,我们设置a<<b来最小化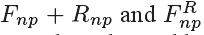 之间的MSE。最后non-PQFs Fnp的质量能够使用最近的PQFs的有效信息进行改善。
之间的MSE。最后non-PQFs Fnp的质量能够使用最近的PQFs的有效信息进行改善。
5. Experiments
5.1. Settings
给出的实验结果来验证我们的MFQE方法的有效性。在我们的实验中,第三章引入的70个视频序列被分为训练集(60个序列)和测试集(10个序列)。训练序列和测试序列均使用最近的HEVC压缩标准进行压缩,将QP设置为42和37.我们的MFQE方法对于QP为42和37的压缩视频分别训练了两个模型。在基于SVM的PQFs检测器中,公式(3)中的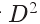 设置为6.这是因为HEVC压缩标准下的所有压缩序列两个最近的PQFs之间的最大距离是6帧。当训练MF-CNN时,raw和压缩的序列被分为64x64的块,用来作为训练样本。批处理大小(batch size)设置为64。我们采用Adam算法,初始学习率为10(-4),使(7)的损失函数最小化。在训练的初始阶段,我们把公式7设置为a=1,b=0.01来训练MC-subnet,在MC-subnet(converges)之后,再将参数设置为a=0.01,b=1来训练QE-subnet。
设置为6.这是因为HEVC压缩标准下的所有压缩序列两个最近的PQFs之间的最大距离是6帧。当训练MF-CNN时,raw和压缩的序列被分为64x64的块,用来作为训练样本。批处理大小(batch size)设置为64。我们采用Adam算法,初始学习率为10(-4),使(7)的损失函数最小化。在训练的初始阶段,我们把公式7设置为a=1,b=0.01来训练MC-subnet,在MC-subnet(converges)之后,再将参数设置为a=0.01,b=1来训练QE-subnet。
5.2. Performance of the PQF detector
由于PQF检测是我们提出的MFQE方法的第一步,我们从精度、recall、和F1得分对PQF检测器进行评估,如表4所示。
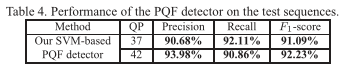
我们从表4中可以看出,当QP为37时,我们基于SVM的PQF检测器的平均精度和recall分别为:90.68% 和92.11% ,另外,F1-分数(被定义为精度和recall的谐波平均精度)为91.09%。相同的结果在QP为42时,平均精度、recall和F1-分数分别为93.98%, 90.86% 和 92.23%。因此,我们的基于SVM的PQF检测器的性能是有效的。
5.3. Performance of our MFQE approach
在这一章节,通过根据ΔPSNR对我们MFQE方法的性能进行评估,ΔPSNR是原始压缩序列和改进后序列之间的PSNR的差值。该方法的性能和AR-CNN、DnCNN、DCAD、DS-CNN和Li的文章提出的算法进行比较。其中,AR-CNN,DnCNN 和Li的文章是对于提高压缩图像质量的最近成果。DCAD和DS-CNN是现在最先进的视频质量增强方法。
Quality enhancement on non-PQFs.
我们的MFQE方法主要是针对使用多帧信息来提高non-PQFs的质量。因此,首先我们来评估non-PQFs的质量增强情况。图8显示了在QP=37的情况下,全部10个序列的PQFs, non-PQFs和 VQFs的平均ΔPSNR结果。正如图中所示,我们的MFQE方法相对于PQFs来说,更能够极大程度的提高non-PQFs的质量。并且,我们的方法能够对VQFs实现更高的ΔPSNR。相比较而言,那些其他的方法对于non-PQFs质量的改善情况等于甚至低于PQFs的改善情况。特别地,对于non-PQFs,我们的方法的ΔPSNR是DS-CNN方法的两倍,并且DS-CNN还是众多方法中最好的一种。这就证明了我们的MFQE方法能够有效提高non-PQFs的质量。

Overall quality enhancement.
表格5给出了每个测试序列所有帧的平均ΔPSNR。正如表格5所示,我们的方法的输出在所有序列的条件下均优于其他方法。具体来说,当QP=37时,我们方法的最高PSNR能够达到0.7716 dB,平均ΔPSNR为0.5102 dB。比Li的文章高了87.78%,比DS-CNN高了57.86%,此外相比于 AR-CNN , DnCNN 和 DCAD更高。在QP=42时,我们的方法的ΔPSNR依旧是DS-CNN方法的两倍。因此,我们的方法对于所有的序列都是有效的,这主要是由于我们改善了占据压缩视频大部分的non-PQFs的质量。

Quality fluctuation.
除了机器因素,质量波动也是导致压缩视频的QoE [15, 32, 16]下降的原因。幸运的是,综上所述,我们的方法能够减轻质量波动,这是因为我们改善了non-PQFs的质量。如第3节所介绍的,我们根据PSNR曲线的STD和PVD来评估视频质量的波动。图7展示了在所有测试序列的条件下,对于HEVC和其他方法的STD 和PVD值的平均值。正如图7所示,在提高压缩视频质量之后我们的方法能够有效减小STD 和PVD值。相反来说,以HEVC为基准线,其他的方法却增大了STD 和PVD的值。因此和其他方法相比,我们的方法能够减轻质量波动,获得更好的QoE。图9更进一步的展示了对于两个测试序列的HEVC基准和我们方法的PSNR曲线。


可以看到,使用MFQE方法的PSNR曲线波动明显要比HEVC波动要小。总的来说,我们的MFQE方法能够有效地降低压缩视频质量波动,同时能够改善视频质量。
Subjective quality performance.
图10展示了Vidyo1 在QP = 37, BasketballPass 在 QP = 37和PeopleOnStreet 在QP = 42的情况下的主观质量表现。我们从图10中可以看出,我们的MFQE方法对比其他方法能够有效地去除块效应。尤其是那些被严重扭曲的内容,比如Vidyo1中的嘴巴,BasketballPass中的球和PeopleOnStreet中的影子,他们能够在我们的MFQE方法中利用临近的高质量帧进行重建出来。相反的,这些扭曲的内容很难仅仅使用一种低质量帧(像其他方法一样)来进行重建。

Effectiveness of utilizing PQFs.
最后,通过对MF- CNN进行再训练,利用相邻帧代替PQFs增强non-PQFs,验证了利用PQFs的有效性。在我们的实验中,使用相邻帧代替PQFs分别仅仅只有0.3896 dB 和 0.3128 dB的ΔPSNR 在QP=37和 42时。相反的,正如上述所说,使用PQFs能够达到ΔPSNR 为0.5102 dB和 0.4610 dB在QP = 37 和 42时。并且,之前也已经讨论过利用PQFs进行质量提升的non-PQFs的ΔPSNR要比PQFs大得多。这就证明了我们的MFQE方法使用PQFs的有效性。
5.4. Transfer to H.264 standard
我们进一步验证了转换到H.264的标准下的我们方法的性能。我们的训练和测试序列都使用H.264在QP=37的情况下进行压缩。然后,训练序列被用来调整MF-CNN的模型。然后测试序列分别被我们的MFQE方法和调整后的MF-CNN方法进行质量改善。我们发现测试序列的PSNR能够改善近0.4540 dB。这个结果可比于HEVC下的结果(0.5102 dB)。因此,我们的MFQE方法的综合性能就得以验证。
6. Conclusion
在这篇论文中,我们提出了一个基于CNN的MFQE方法来减小视频的压缩效应,和其他仅使用单帧进行质量提升的方法不同,我们的MFQE方法能够使用最临近的高质量PQFs来对当前帧的质量进行改善一帧的质量。为了达到这个目的,我们提出了一个新的CNN框架,叫做MF-CNN来提高每一个non-PQFs的质量。我们的MF-CNN中的MC子网能够对PQFs和non-PQFs之间的运动矢量进行补偿。随后,QE子网能够通过输入当前non-PQFs和补偿过的PQFs提高每个non-PQFs的质量。最终。实验结果表明我们的MFQE方法能够有效改进non-PQFs的质量,效果远高于其他的视频提升方法。最后,该方法在减小质量波动的情况下的质量提升效果要比其他方法都要明显。
这篇关于压缩视频增强论文Multi-Frame Quality Enhancement for Compressed Video阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







