本文主要是介绍大促流量激增,通过什么手段提升系统的高并发、高可用性?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在之前提到过,最近运营在前面搞了一个活动,比如抽奖,发放优惠券等方式,去吸引用户购买商品,但是卡券的有效时间只有2个小时,这样的话用户支付动作会比较集中,这也就对我们的支付系统有了更高的要求。所以,如何在流量激增的情况下保证支付服务的高并发和高可用性是对我们的要求。
经过一系列的压测、调优,达到了预期的QPS。结果不是最重要的,最重要的是期间的调优过程,所以将最近在压测过程中出现的问题以及调优的过程复盘并记录下来,以便日后查看。如果大家面临类似流量突增的情况会怎么调优呢?
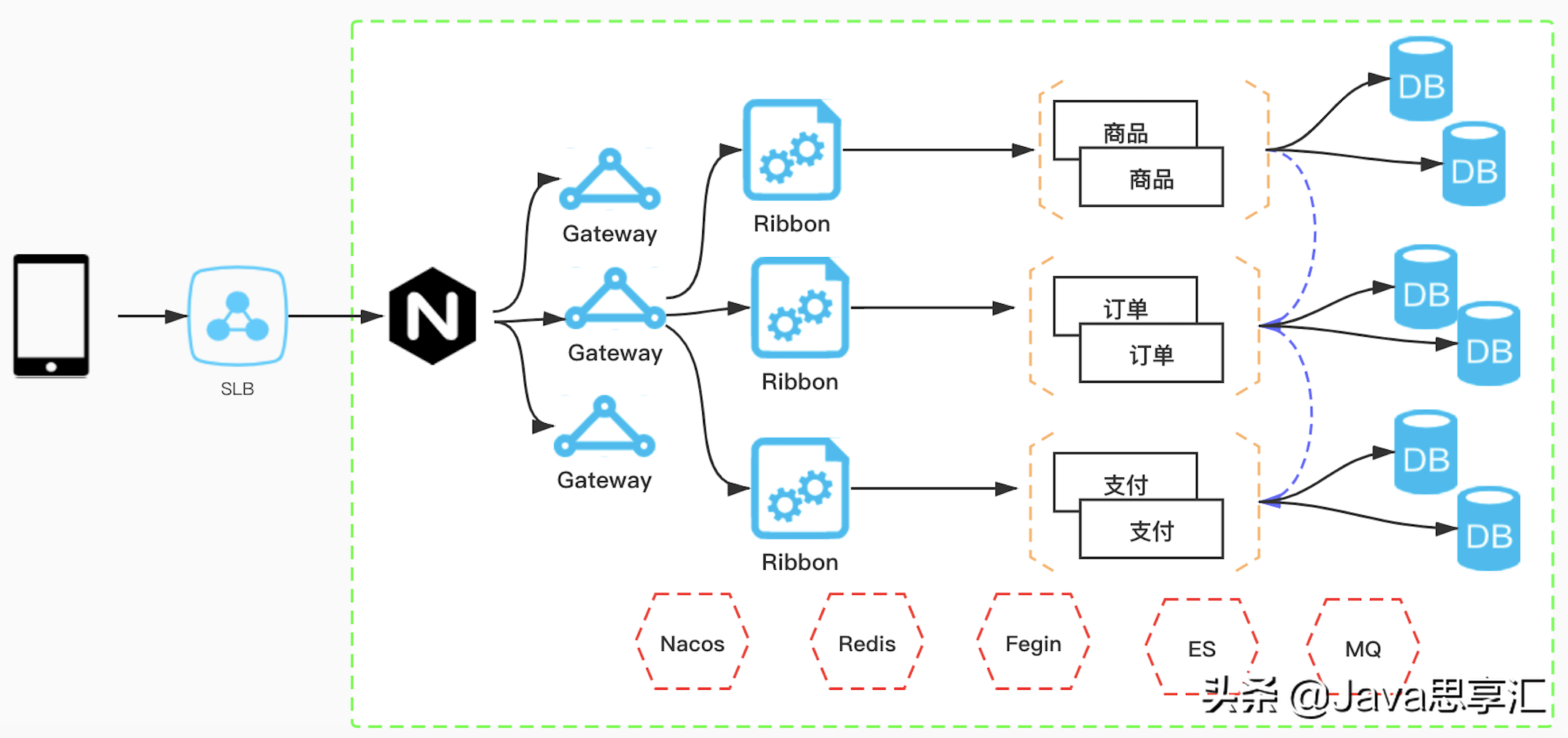
网络架构图
上图为我们目前简易的一个网络架构以及组件应用图,我将按照网络流量传递方式进行总结。
SLB
首先进行配置升级的就是流量入口的位置,即SLB。按照预估流量,以前SLB的QPS为5W,这次大促活动,将核心模块SLB的QPS升级至10W。
Nginx
接下来是负载均衡组件Nginx,因为本身Nginx的QPS就是万级别以上了,我们在压测过程中发现Nginx并不是瓶颈,所以就没有进行升配。
网络
因为我们的应用服务目前存在私有部署和阿里云部署,所以中间存在着网络专线,所以本次压测过程中重点关注了网络延迟,发现其中的网络延迟为毫秒级,可以接受,并未对网络带宽进行升级,不过这也是一个其中的一个风险点,如果在活动期间专线网络存在抖动的情况,可能会影响到核心服务的质量。
阿里云ECS
下面就到达了具体的服务应用部分,因为我们的服务全部都是通过网关(SpringCloud Gateway)进行统一服务转发的,所以在经过压测和流量评估后将网关进行了机器扩容和配置升级,由原来的4C8G升级为8C16G。
对于核心业务交易模块的机器也进行了翻倍扩容,以此来增加系统的整体吞吐量,增加机器后集群整体TPS和QPS提升比较明显。
Tomcat
本次调优过程中,对Tomcat核心参数也进行了调优,主要包含最大连接数和最大线程数等,对于4C8G对机器来说,建议设置参数如下:
server:tomcat:accept-count: 1000max-connections: 10000 max-threads: 800 min-spare-threads: 100缓存
提高系统查询性能的利器就是使用缓存了,以此来提升系统的访问速度、增大系统的处理容量、提升性能和缓解数据库压力。对于一些不怎么经常变得数据,我们使用的Redis来作为缓存。不过使用Redis作为缓存也需要考虑其可能发生的问题,也就是缓存穿透、缓存击穿和缓存雪崩的问题。针对以上问题,行业上都有比较成熟的解决方案,下面我们依次解释,并记录下处理方案。
缓存穿透:请求去查询一条数据库中压根就不存在的数据,也就是缓存和数据库都查询不到这条数据,这样的话请求每次都会打到数据库上面去。
穿透产生问题:如果有黑客对你的系统进行攻击,拿一个不存在的id 去查询数据,会产生大量的请求到数据 库去查询。可能会导致你的数据库由于压力过大而宕掉。
穿透解决方案:1)缓存中没有存储这些空数据的key。去数据库中查询也没有, 那么我们就可以为这些key对应的值设置为null丢到缓存里面去。后面再出现查询这个key 的请求的时候,直接返回null ;
2)布隆过滤器是将所有可能存在的Key的Hash到一个足够大的bitmap中,在缓存之前再加一层布隆过滤器 ,在查询的时候先去布隆过滤器去查询key是否存在,如果不存在就直接返回,存在再走查缓存或者查DB。
缓存击穿:在高并发的系统中,大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。
击穿产生问题:在高并发的系统中,大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。
击穿解决方案:1)可以在第一个查询数据的请求上使用一个互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
2)超时预判:在value内部设置1个超时值t1, t1比实际的超时时间t2小,当读时发现t1已过期,先加锁延长t1并重新设置到cache, 同时通知查库,查库期间Cache返回旧值,有一个线程从数据库加载数据并设置到cache中. 此后Cache返回新值;
3)预热:先将热数据先加载到缓存系统, 请求直接查询. 后台线程异步同步/定时更新。
缓存雪崩:指当Redis宕机或给所有的缓存设置了同样的过期时间,当某一时刻,整个缓存的数据全部过期了,然后瞬间所有的请求都被抛向了数据库,数据库就崩掉了。
雪崩产生的问题:会造成某一时刻数据库请求量过大,压力剧增。
雪崩解决方案:1)宕机:对缓存集群实现高可用,如果是使用 Redis,可以使用主从+哨兵 ,Redis Cluster 来避免 Redis 全盘崩溃的情况;
2)缓存失效:为了避免这些热点的数据集中失效,那么我们在设置缓存过期时间的时候,我们让他们失效的时间错开。比如在一个基础的时间上加上或者减去一个范围内的随机值。
以上是对应用缓存提升查询接口QPS的方式以及问题处理的总结。
异步化
异步化主要包含两部分,第一部分是分布式系统之间的异步化,主要通过MQ来实现,我们这里使用的阿里云付费版RocketMQ(ONS),在经过压测和评估之后,首先将TPS升级由2W升级至5W,以提高系统的吞吐量。还有就是利用MQ的消峰、异步解耦特性,对于核心业务非必须同步返回结果的接口同步MQ异步优化,这样极大了提高了接口的响应性能。但是在使用MQ时也需要注意一些问题,比如:消息的事务问题、消息顺序问题、消息的防重和幂等一些列的问题。
异步化的第二部分是在单机JVM来进行,比如线程池、程序调用多方接口采用Future模式等。
JVM
这也是本次调优的一个关键点!在首次压测的过程中,压测性能老师反馈存在卡顿的现象,经过排查监控发现是新生代存在频繁的Yong GC且GC时间长达1.5S,这也是导致卡顿产生的原因,老系统的新生代设置的Eden和S1、S2的比例为1:1:1也非常不合理,调优后将比例调整为8:1:1,增加Eden的内存空间。同时Metespace的空间分配也过小,还有就是有些系统竟然没有设置Xms,导致JVM的可用内存非常小,不断发生频繁的Full GC,调优后JVM的可用内存才恢复正常,效果如下图:
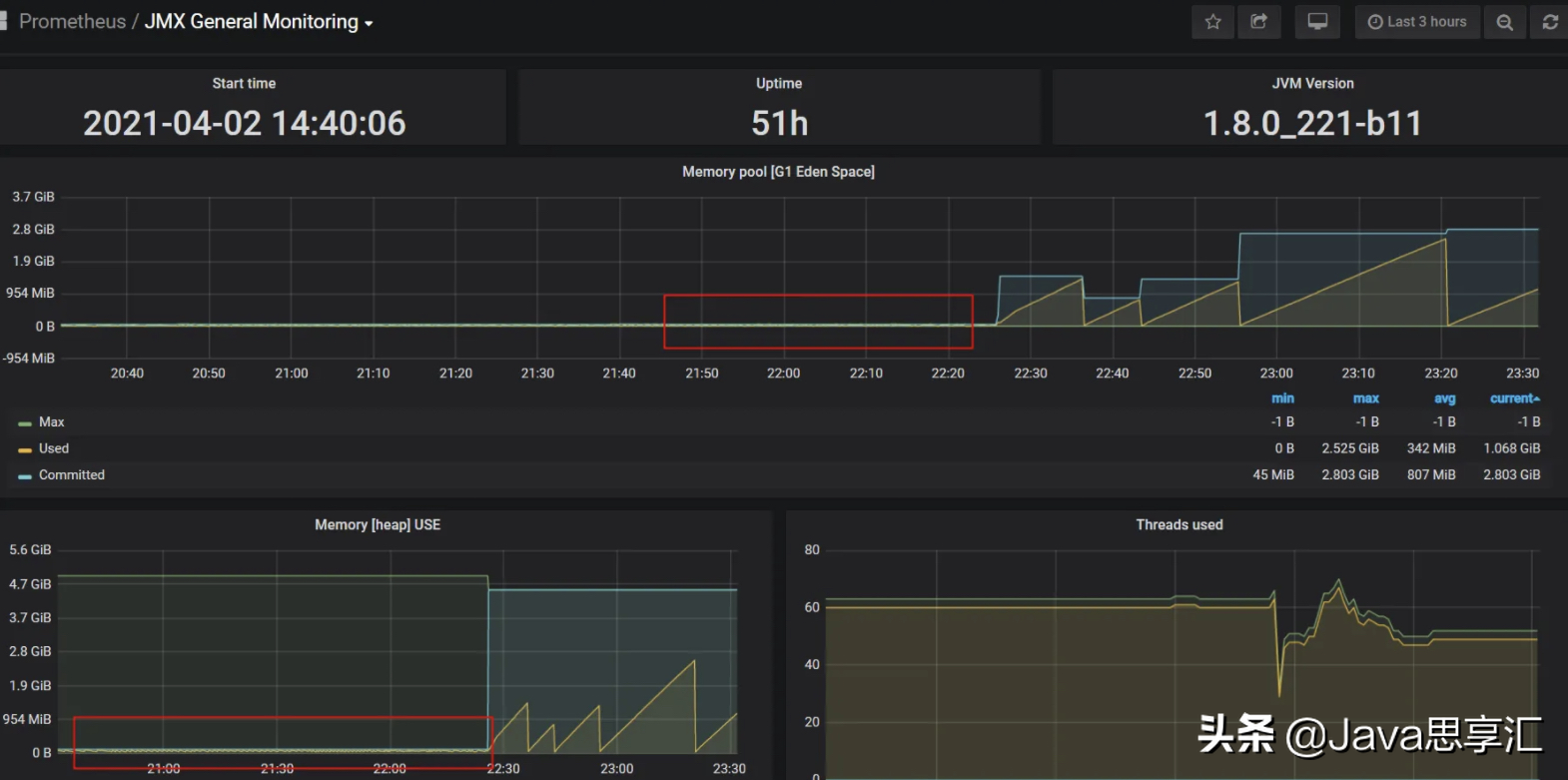
JVM使用情况
针对4C8G的机器,在设置JVM参数的时候,建议设置为:
CMS配置参考:-Xms4608M -Xmx4608M -Xmn2048M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:TargetSurvivorRatio=60 -XX:CMSInitiatingOccupancyFraction=75
G1配置参考:-Xms4608M -Xmx4608M -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+UseStringDeduplication系统日志
在压测的过程中,发现只要流量一上来,会产生大量的磁盘IO,这期间的接口响应也会变慢,经过分析是打印大量日志和日志中存在大JSON数据导致,于是升级日志打印级别同时将同步日志打印改为异步,系统提升性能效果明显。logback.xml修改如下:
<appender name="RollingFile_Async" class="ch.qos.logback.classic.AsyncAppender" neverBlock="true"><queueSize>8096</queueSize><neverBlock>true</neverBlock><appender-ref ref="RollingFileAppender"/>
</appender><root level="info"><appender-ref ref="RollingFile_Async"/>
</root>数据库
对于核心业务操作必然涉及到最终到落库操作,数据库优化也是本次调优的重点,主要从一下几个方面进行优化:
- 升级数据库配置(DRDS升级配置由32C128G升级至64C256G);
- RDS增加从库,数据读写分离,增加查询性能;
- 连接池最小连接数由5改成20,最大连接数由60改成200;
- 慢SQL优化;
- 分页查询。
ES
针对聚合搜索的业务,本次对ES也进行了调优,最主要对目的都是让FileSystem Cache能够缓存更多的数据,我们做了按照年份对数据做了冷热数据分离、数据预热等,具体细节我梳理一下,见下图:
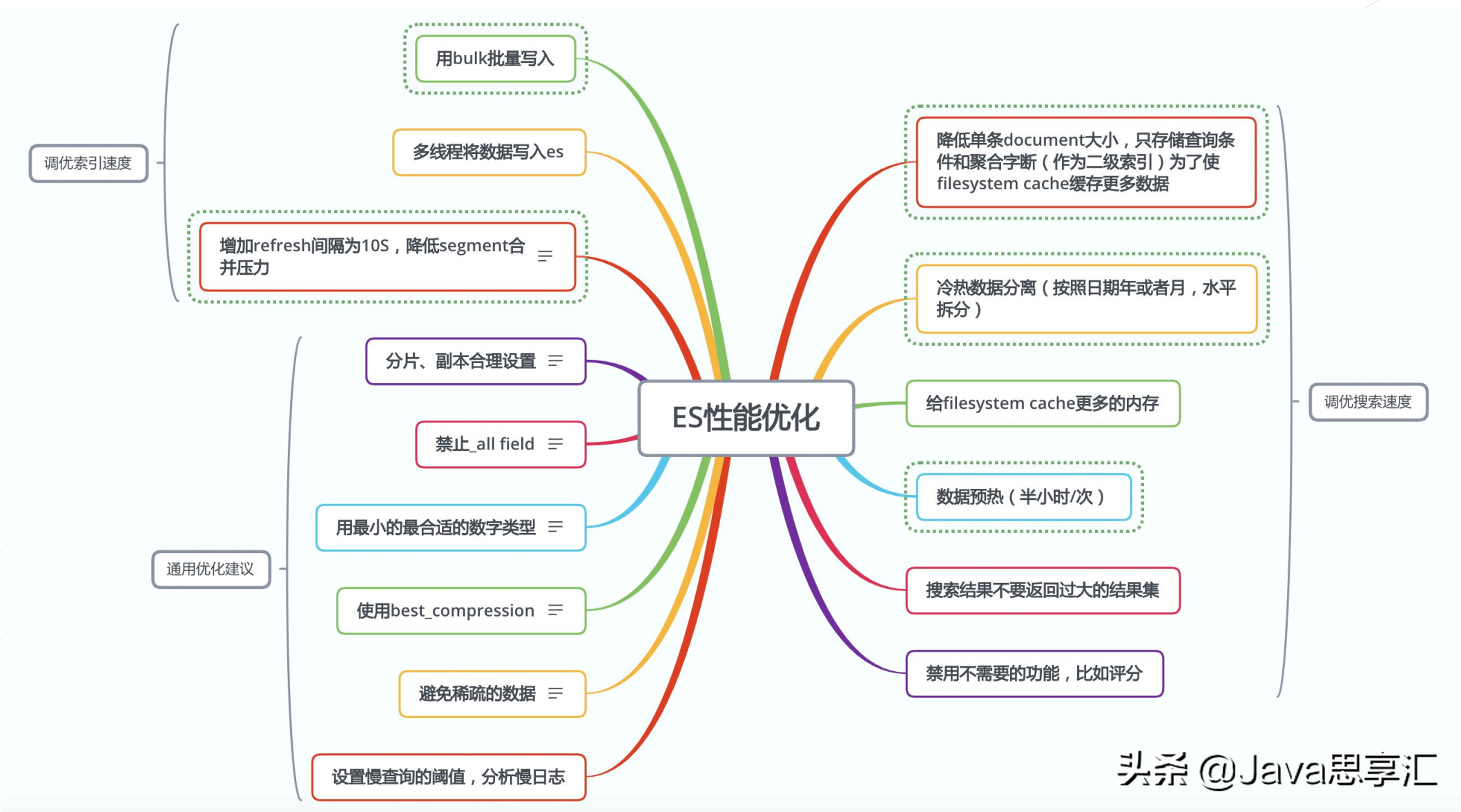
ES优化细节
限流、降级
为了保证系统的高可用,系统必须采取一定的降级和限流手段,防止发生服务雪崩的情况。比如降级,针对一些不重要的展示信息,由于这些信息涉及到关联表查询等,影响系统的整体性能,所以在大促期间将这些不重要的信息进行降级处理。限流主要是针对找过预估的流量按照QPS进行限制。
好的,以上是针对本次大促活动进行的调优整理,希望可以帮助到大家,如果有其他更好的方式也欢迎留言讨论。
不断分享开发过程用到的技术和面试时经常被问到的问题,如果您也对IT技术比较感兴趣可以「关注」我,让我们共同学习,共同进步!
这篇关于大促流量激增,通过什么手段提升系统的高并发、高可用性?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







