本文主要是介绍库卡机器人提示无合适的mam文件处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
库卡机器人提示无mam文件多出现在老机械手,常年没有维护的机械手上。提示缺少该文件正常不会对机械手自动运行存在影响,但如果你要用EMD对机械手重新进行做零点矫正就不行了,只能做普通矫正。这时候该怎么处理呢?其实只要把该信号屏蔽就好了,具体操作如下。
先找到将库卡机械手切换到专家权限然后找到$machine.dat文件

然后打开该文件修改内部变量
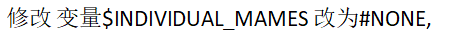 具体位置如下图
具体位置如下图
修改完成后点击保存即可,最后重启机械手就可以了
这篇关于库卡机器人提示无合适的mam文件处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






