本文主要是介绍从开发人员的视角面对c盘容量紧缺的一些方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
随着时代的发展,固态价格不断地下降,电脑硬盘容量水平线在不断地上升,近几年新出的主流笔记本自带固态容量也基本上在256G以上。所以通常不会有容量不够而带来的烦恼。个人用户往往是因为视频、游戏等文件占用了大量容量,针对这些零散大文件进行清理也比较方便。然而还是存在一些有痛点的用户,本文面向的主要读者是部分IT预算不足的公司的程序员。
程序员相比普通用户对电脑的性能要求是不同的,相信也有很多程序员所在的公司对于电脑硬盘配置并不是很慷慨,作者所在的公司一台电脑两个硬盘:128G固态作为系统盘,附加1T机械。
这篇文章是以程序员的视角,科学的针对不同的软件,分别进行默认数据存放位置的迁移,从而达到释放系统盘容量的目的。不过也受限于作者本身软件环境(win11 + 主前副后端开发)。建议读者在读完正文的 通用篇 后,根据目录直接跳到对应的软件下方寻找解决方案。同时我也会将我实际操作后腾出来地空间标识在各自的标题位置,供直观参考。
作为程序员,以下内容应该是属于常识:固态和机械硬盘的区别,硬盘的重要性能指标:IOps 和 MBps,本文为了普适性,将在附录部分简单介绍一下这些概念。
Why not “垃圾清理”
常见的清理方式为各大安全软件自带的 垃圾清理 功能,那为什么我不推荐使用这个功能呢?就拿 浏览器缓存 举一个典型例子,假设你经常会浏览 apple.com.cn 网站,按 F12 打开开发者工具:
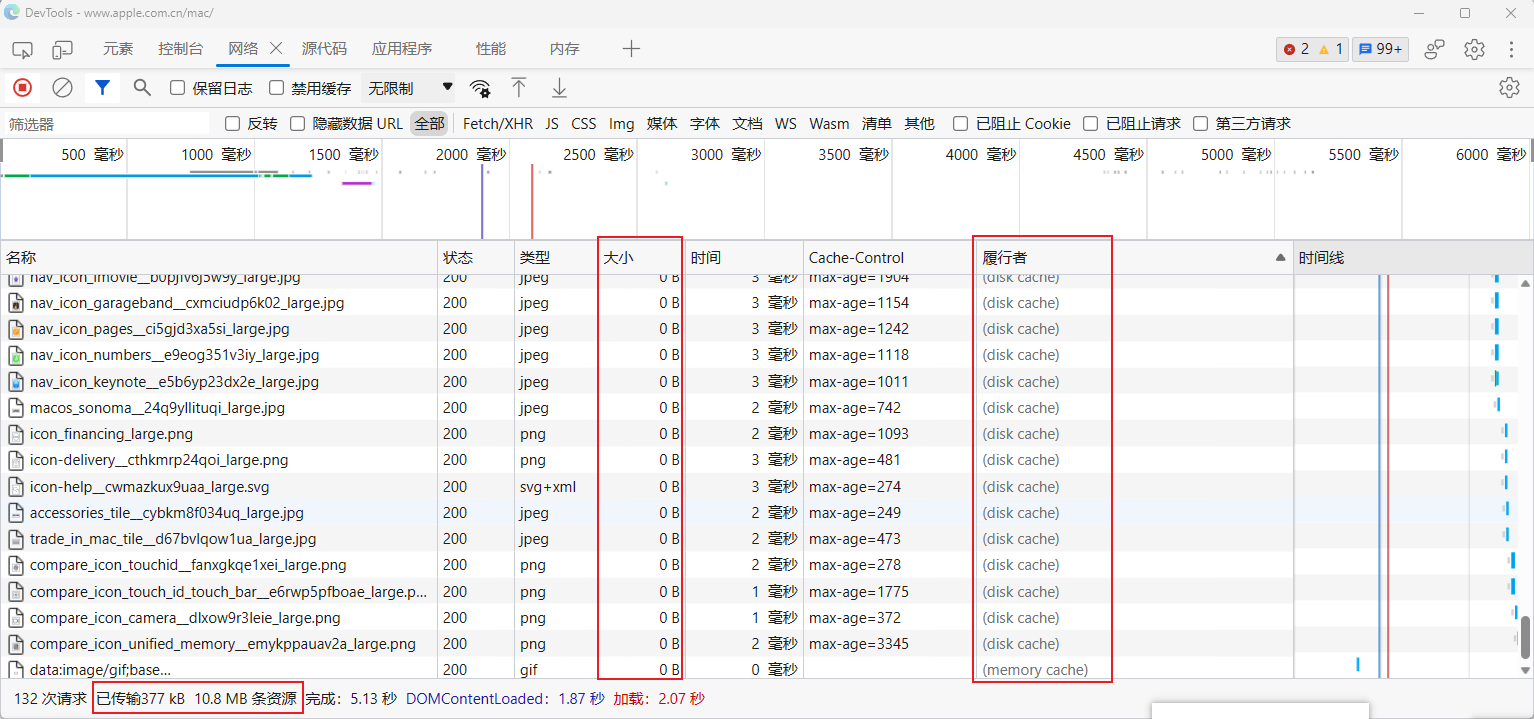
在 网络选项卡 中,首先关注一下 大小 和 履行者 两列,发现大部分请求(无论是图片等媒体的请求还是字体、js 文件的请求)都走了缓存(可能是硬盘缓存、内存缓存等),然后关注下方红框: 已传输 377kB 10.8MB 条资源,这是什么意思呢?意思是本次页面加载,只有 377kB 是通过网络请求获取的,也就是如果是在手机上,本次页面访问只消耗了 377kB 的流量,而整个页面其实一共包含了 10.8MB 的数据。超过 10M 的数据都通过缓存从本地提取了,这么做既节省了流量,又加快了页面的响应(当然浏览器缓存的控制是有难度的,有很多网站会因为缓存导致数据更新不及时等问题,但那是网站开发者的问题,缓存是一个专业的开发者可以完全拿捏的纯粹的技术问题)。
那回到正题,这和 “垃圾清理” 有什么关系呢?现在我们来看一下一些软件的垃圾清理页面的详情列表:


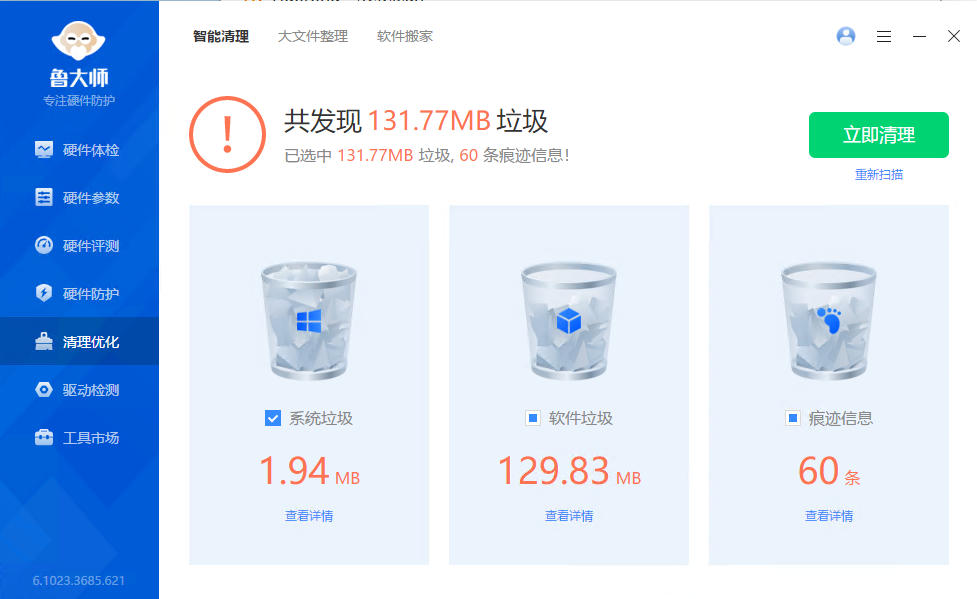

可以发现,浏览器缓存就包含在里面。当我们清理之后,一方面上述的优势(更快打开页面、节省流量等)都化为无,另一方面,再次访问网站,“垃圾”依然会重新产生。从而导致“垃圾”根本清理不完。
回想起我小时候玩电脑一天都会打开360清理好几次垃圾,当初的想法很单纯:既然是垃圾,那就应该清理,肯定会有好处的。现在回想,不禁感叹啊。
小插曲:
作者本以为清理浏览器缓存应该是各大软件垃圾清理都会有的项目,实测下来发现
腾讯电脑管家是不会清理的。
而这就引申出了问题的本质:到底什么是垃圾,不同的垃圾清理软件都有不同的定义,差别较大。例如浏览器缓存这项,在腾讯电脑管家中,不认为这是垃圾,没有在列表中列出;在鲁大师中,认为这是建议清理的垃圾,默认勾选;在火绒中,判定这是垃圾,但是默认并不勾选。
当然这只是针对我专业比较熟悉的浏览器缓存这一项——我清楚他存在的意义,剩下的“垃圾”还有好多项呢!比如系统还原点——清理后会导致系统更新后无法还原;系统日志—— 清理之后可能无法通过一些工具分析之前系统异常的原因。。。总之,本文中作者的观点是:很多东西你用不到归用不到,但是他总是在发挥他自己的作用,在不清楚具体作用的情况下,不要乱把文件当“垃圾”删掉。乱删轻则导致用户体验下降,严重的甚至会蓝屏、损毁数据,而且还没法解决根本性的问题——这些文件很可能会再次产生,重新占用容量。
这里再针对以上实验做个补充——我是如何判断
腾讯电脑管家没有删除浏览器缓存的:网站资源缓存后,在资源没有过期的前提下(通常短时间不会过期,这里的短根据不同网站都不同,可能是几小时,可能是几天,可能是一年),重新打开网站(即使是关闭浏览器之后再重新打开),开发者控制台都会显示资源走的还是缓存。上述实验过程是先访问网站,然后关闭浏览器,然后清理垃圾,然后再访问同样网站,观察控制台缓存情况。发现通过腾讯电脑管家清理垃圾后,目标网站仍然大量资源走的缓存;而通过鲁大师清理垃圾后,目标网站所有资源均重新加载。而另一方面,通过清理的界面上标注的垃圾大小也能简单判断,鲁大师中浏览器缓存数据高达 100MB+。
简而言之,上面讲的是 垃圾清理软件 清理的可能是有作用的数据。而且容易复发,难以根治容量问题。而本文主要通过搬迁应用数据存储目录的形式,解决系统盘容量不足的问题(当然有部分垃圾清理软件也覆盖了一部分这类功能,比如微信聊天搬迁、应用程序搬家等,这些功能可以尝试,但是依然可能存在坑,尤其是现在通用的应用程序搬家程序,一方面应用程序如果是从 SSD 搬到 HDD,必然会导致应用打开速度变慢,举个例子:英雄联盟,如果是安装在 SSD 中,则选择英雄后到进入游戏的加载过程通常可以在10秒以内;而如果安装在 HDD 中,则加载过程通常起码得1分钟往上。另一方面,应用程序如果是安装版的话,涉及到的注册表、菜单项等位置能否自动矫正呢?等等因素,如果应用搬家功能是通用形式的,还请谨慎使用)。
正文
通用篇
默认文件夹位置迁移(看这些文件夹用的频率,作者占用10G+)
windows 中早期为了方便用户归类文件,设定了许多默认文件夹,比如下载、视频、图片、文档、桌面、音乐等。绝大部分程序都会将对应类别的资料默认保存地点设定为这些文件夹,例如浏览器下载的默认地址就是 下载;系统截图工具截图的默认保存地址是 图片;office365 的默认保存地址是 文档。。。然而这些文件夹默认都躺在 C:\Users\<current_user>\ 目录下。不过这些文件夹相较于普通文件夹,在属性中有一个 位置 标签页,可以迁移位置!
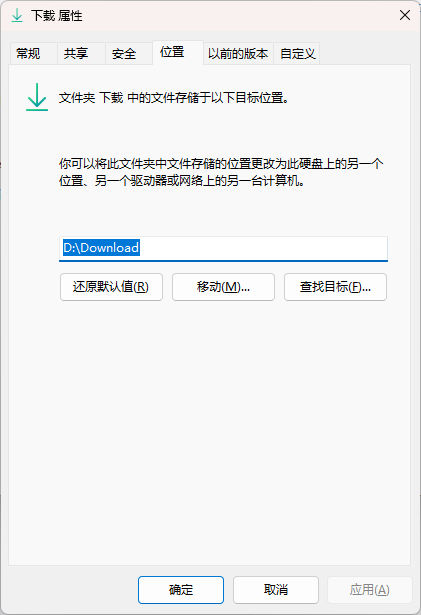
可能要注意的点:
这些默认文件夹中, 文档 文件夹相对有特殊性,之前博主并没有使用 OneDrive,印象中迁移了文档后发生了很麻烦的事情,之后不得不再次迁移回来。
但是在使用 OneDrive 之后,使用他本身提供的文档备份功能, 并将 OneDrive 存储位置设立在其他盘,就没有发生过之前的问题了,仅供参考。
特定软件篇
IDEA(看IDEA版本和本地打开过的项目数量,作者占用~12G)
官方指引:
- Directories used by the IDE
- Changing IDE default directories used for config, plugins, and caches storage
IDEA 配置主要分布在两个大目录: %APPDATA%\JetBrains\<product><version> 和 %LOCALAPPDATA%\JetBrains\<product><version>。
随着 IDEA 版本的升级,IDEA 上述目录占用的容量已经高到离谱的程度了,尤其是 LOCALAPPDATA 那一部分,更具体的说就是索引文件:
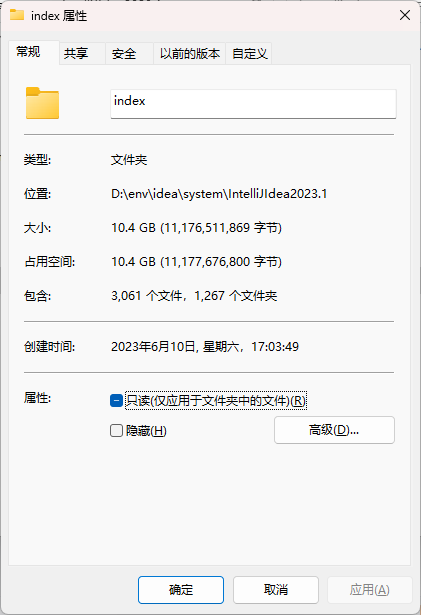
根据官方的指引,只要在软件内 Help | Edit Custom Properties 的地方重新定义各自的目录(四条定义,idea.config.path idea.system.path idea.plugins.path idea.log.path )即可切换软件读取配置文件的位置。
可能要注意的点:
笔者实际操作下来发现在 Help | Edit Custom Properties 定义了之后,移除原位置的目录后还是会新建在原来位置。最终成功的方案是直接在 IDEA 的安装目录的 bin/idea.properties 中做同样的修改才生效(这种办法上述官方文档也有说,官方文档的意思是,通过 Help | Edit Custom Properties 办法修改的配置在更新之后也可以一直适用,而直接修改硬盘上的配置文件,在更新之后会被重置)。
后续在写本文章的时候发现:

推断原本修改不生效的原因和没有定义 IDEA_PROPERTIES 环境变量有关(读取配置文件的位置错了),具体如何纠正配置还有待考察。(目前 Help | Edit Custom Properties 功能无法正常使用)
VSCode()
TODO (全世界难道只有我写前端用 IDEA 吗?可是我觉得 VSCode 门槛确实有点高啊。。。)
Docker(看下载的镜像大小和起的容器实际占用,比如跑个 docker-osx 容量就会不得了,作者占用~100G)
傻瓜教程可以参考:
WSL2 迁移 Docker 镜像存储位置
涉及到的 WSL 命令可以参考:
WSL 的基本命令
有关适用于 Linux 的 Windows 子系统的常见问题解答
涉及到的 docker 知识:
Docker Desktop WSL 2 backend on Windows
官方文档描述了 基于 WSL2 的 docker 会安装两个特殊的 Linux 发行版,分别是
docker-desktop和docker-desktop-data,前者用于安装并运行 docker 引擎相关的内容,后者存容器和镜像。
Java后端(根据项目数量、规模、运行时间决定,作者占用 maven 1.3G、log 文件两年累积10G)
作者虽然是全栈开发, 但是基本是偏前端的,后端主要占用容量的有:maven .m2 仓库、项目可能会产生的 log 文件、有些开发会写死的一些输出文件。
maven 默认读取的配置文件位置通常为 C:\Users\<current_user>\.m2\settings.xml。如果没有配置文件,或者配置文件没有指定仓库位置, 默认的仓库位置也是 C:\Users\<current_user>\.m2\repository\,可以通过在 setting 标签下写一个 <localRepository>/path/to/local/repo</localRepository> 子标签的形式修改。
Web前端(根据项目数量、规模以及工具链数量决定,作者占用5.3G)
前端主要是各种 npm 依赖,如果是使用 npm 进行安装的话,非全局安装,库文件都会直接原封不动存入项目目录,不会在其他地方留副本。如果前端项目比较多的话,这也是挺不得了的,pnpm 特地针对这个问题进行优化,发展出了中央存储库的形式,每次下载都会集中位置进行缓存,随着项目的增多,需要下载的库数量越来越少(只有版本不同或者之前项目没有过的依赖才需要下载),更多可以直接在本地缓存读取。这样总的依赖占用容量会相比 npm 低很多。
因为作者使用的是 pnpm,所以这里主要介绍一下pnpm怎么修改中央存储库的位置:
官方文档: global-dir
主要涉及到的环境变量是 $XDG_DATA_HOME,指向依赖中央存储库的实际存储位置(具体位置为 $XDG_DATA_HOME/pnpm/store),剩下的零零散散还有些比如缓存、bin 的存储目录等,都有各自的环境变量,但是从本文的目的来说,这些占用的容量并不大,如果想一并迁移的话,具体看上述官方文档(涉及到的几个环境变量在文档中都是紧挨着的)
但是在指定了存储位置之后还是有些注意点的, 比如不要在指定存储位置所在的驱动器之外使用 pnpm,否则依然会进行依赖文件的复制而不是符号链接。参考: Pnpm 是否可以跨多个驱动器或文件系统工作?
附带也简单介绍一下 npm 如何修改存储位置。
官方文档:
.npmrc
config
npm 并没有中央存储库的概念,主要占用空间的涉及到两个功能:全局安装依赖、缓存。npm 支持在运行命令行中、环境变量中、.npmrc 三种方法设定相应变量,这里就介绍修改 .npmrc 的方式修改存储库位置(.npmrc 文件的读取也有一个优先级,具体请参考官方文档):
在 C:\Users\<current_user>\.npmrc 中指定以下两个变量即可:
cache=D:\env\npmDownload\cache
prefix=D:\env\npmDownload\packages
总结
本文只覆盖了作者工作中常用的一些软件,其余软件同理,通常都可以手动指定或者安装后修改数据存储位置,在寻找教程时,务必优先从官网找。还有的软件比如微信等,设置内容比较少,很容易就能找到相关设置。
再次重复一遍,在不清楚文件具体作用的前提下,不要乱删文件!
相关工具推荐
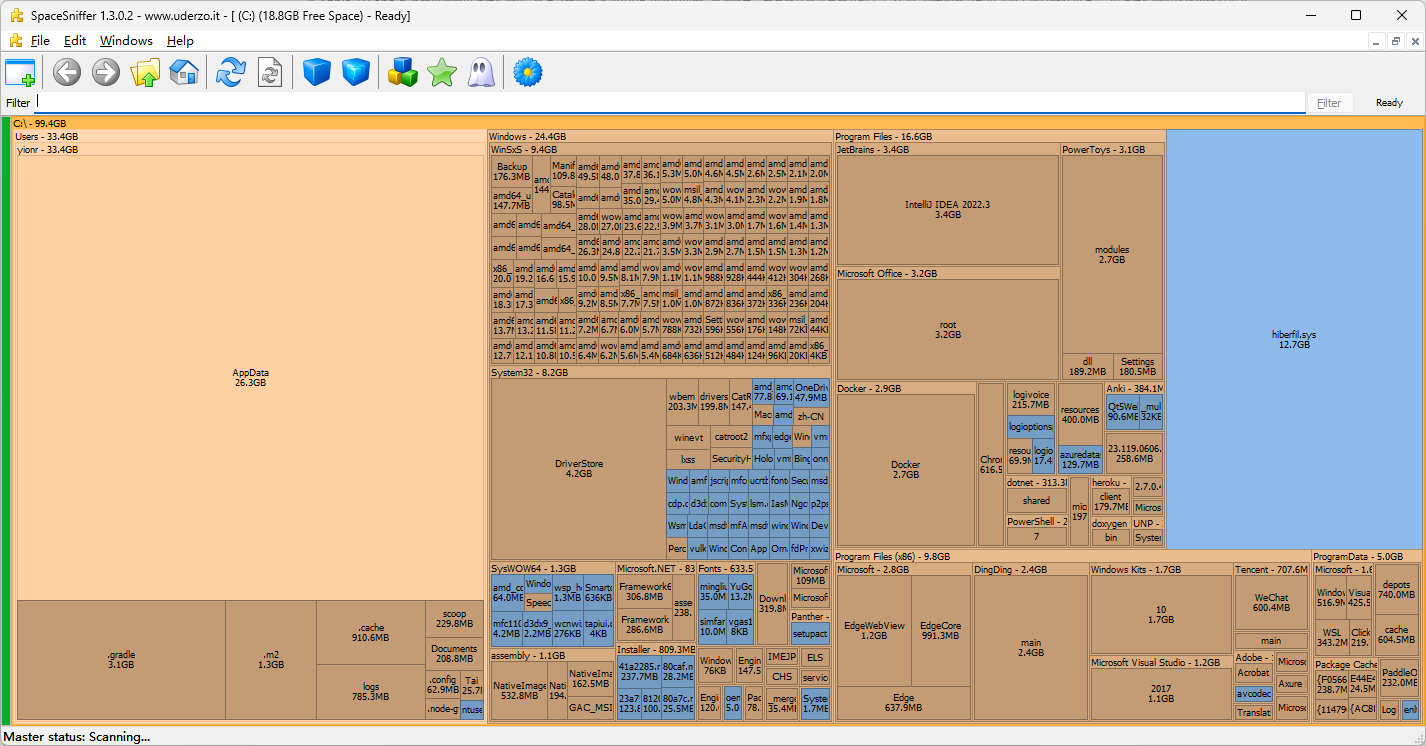
space sniffer
这个软件可以扫描指定的驱动器,然后以 矩形树图 的形式展现,容量大的对应的块就大,十分直观,针对包含子文件夹的,还可以进一步的深入,很方便就能找到指定驱动器下的大容量文件和文件夹:
附录
以下介绍硬盘的基础知识,为了使阅读更加轻松,将采用 FAQ 的形式展开。
1. MBps 我知道,IOps 是什么?
通常硬盘跑分软件,例如 AS SSD Benchmark 都会有几个数据指标:

请将焦点关注在 Seq 和 4K 这两个指标上,也就是平常经常能听到的 顺序读写性能 和 4K随机读写性能 。
顺序读写,针对的实际场景是 一个大文件 的复制行为,背后存储的规则是该文件的所有内容按照顺序排列在硬盘存储芯片(磁道)上。硬盘控制器在读写文件时,节省了查找的时间,整体的速率就会很高。
4K随机读写,针对的实际场景是 一大堆小文件 的复制行为,背后的存储规则是这一系列文件在磁盘分布上并没有什么顺序,硬盘控制器针对每个文件的读取,都要事先去查找到这个文件,然后再进行读取,大量的时间都花费在查找上了,整体速率相比顺序读写有很高的下降。
由此可知,4K 随机读写 其实就是随机读写,而为什么通常都会带有 4K 呢? 4K 在这里代表 4KB 的意思,也就是测试过程中,每个文件都是4KB大小的,那为什么不是 5K、3K 呢?对这块感兴趣的自行参考网上关于
4K对齐等文章的描述。
在简单了解了 顺序读写 和 4K随机读写 之后,就可以介绍 IOps 这个单位了, 也就是 Input/Output per second, 每秒钟能进行多少次输入输出操作。他是一个单位,相比 MBps 而言是硬盘的 4K随机读写性能 更合适的参考单位(顺序读写主要看 MBps,因为没有查找数据块的开销,所以主要看每秒钟能读写多少容量;而随机读写要看性能多厉害,得看他一秒钟能找到多少个文件。不过由于在测试中每个文件都固定为 4K,所以通过 MBps 也能简单判断性能,但是实际使用中, 用 IOps 更加直观,一个是关注吞吐量,一个是关注找文件的速度,这样解释懂了吗?)。
在编程中,尤其是现在工程化的前端项目,开发机对于硬盘 随机读写 的性能要求还是很高的,尤其是基于 webpack 的情况下,webpack在编译的过程中涉及到大量依赖文件的读写, 这些依赖都是很小的代码,但是数量巨大,拿一个开源项目举例,vant,在安装依赖后,node_modules中包含的文件数量如下:
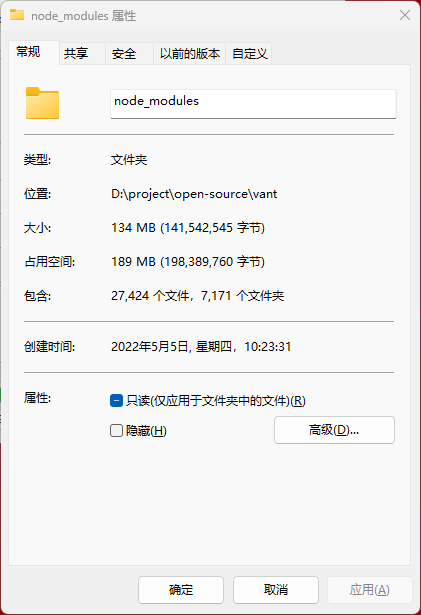
这个文件数量够夸张吧!即使硬盘的顺序读取速度很高(比如上图作者的机械硬盘顺序读写能到接近200MBps,如果直接套到这个文件夹下去,那岂不是1秒钟都不到就加载完了?笑),但是针对具体的场景,需要的是随机读写,导致原本就很花时间的 webpack 项目启动速度更是雪上加霜。
2. 固态和机械的主要区别是什么?
在使用中,主要是速度的区别,产生速度区别的原因又可以细分为 存储介质 的不同和 传输协议 的不同,固态硬盘通常为 SATA 协议传输(SATA3.0 速率上限为 500MBps), 存储介质是磁盘,读写方式是采用机械结构;相比而言,2023 年,固态硬盘通常采用 NVME 协议传输(NVME根据使用的 PICE 版本和通道数量不同,通常读写速度可以轻松达到 2000MBps 以上),存储介质是闪存颗粒,读写方式是电子结构。
速度的区别当然不只是吞吐量的区别,在 IO 吞吐性能上也是天差地别,机械硬盘规格通常不标 IO 吞吐性能,因为受限于机械结构,IO 性能是公认的存在瓶颈。而不同固态硬盘的 IO 性能也能有很大差别,就拿公司自带的固态和作者自己买的做对比:
SN770 500G 固态硬盘
官网参数页:WD_BLACK SN770 NVMe™ SSD
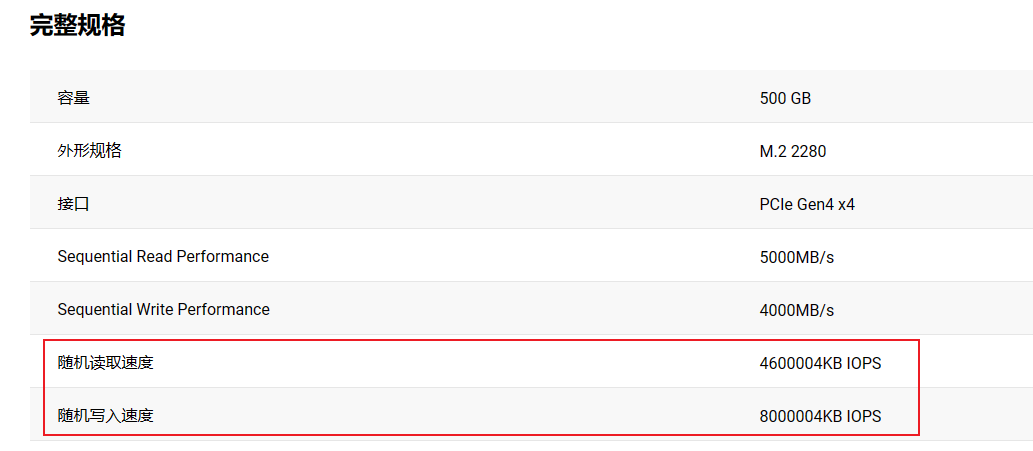
官网标称是达到了 80万的 随机写入次数 和 46万的 随机读取次数。对比公司的固态:
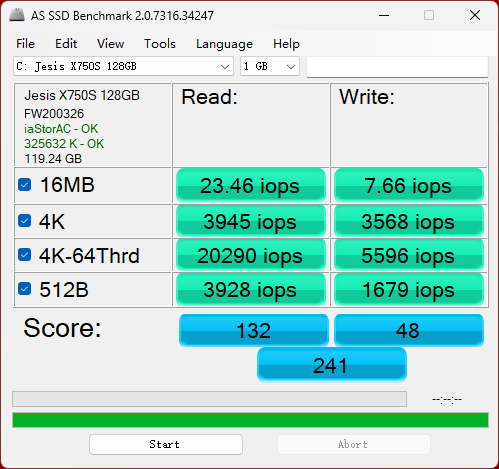
读 2 万,写 0.5 万。。。
这个差距有多大了解了吧。 顺便一提,现在固态能够被消费者感知的主要参数也是这个,因为平常移动大文件的场景是比较少的,比如一款是 4000MBps 的速度, 一款是 6000MBps 的速度,试想你的单文件体积要达到多大,才能明显感知到这两款的差距呢?而达到这个体积的文件数量在平时是否有遇到呢?但是 IO 吞吐就不一样了,前面前端工程就是一个例子,所以购买前可以仔细看看。
3. 什么有的固态在容量快满了之后,性能急剧下降,有的不会?而机械硬盘普遍存在这类问题?

知乎关于此问题的回答: 如何理解SSD的写放大?
请参考以上优质回答。
这篇关于从开发人员的视角面对c盘容量紧缺的一些方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







