本文主要是介绍Thermal(1)——温控策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考文档:
《Rockchip-Developer-Guide-Linux4.4-Thermal-CN》
功耗计算
静态功耗公式:
/* a、b、c、d、C是常量,在DTSI中配置,保持默认值即可,T是温度,V是电压,需要根据实际情况调整 */
t_scale = (a * T^3) + (b * T^2) + (c * T) + d
v_scale = V^3
P(s)= C * T_scale * V_scale
动态功耗公式:
/* C是常量,在DTSI中配置,保持默认值即可,V是电压,F是频率,需要根据实际情况调整 */
P(d)= C * V^2 * F
以RK3399为例,假设A53、A72、GPU都有⼯作,都需要限制,实际使⽤最⾼频分别为1416MHz(1125mV)、1800MHz(1200mV)、800MHz(1100mV)


以GPU为例:
GPU 动态功耗:C = 733(dynamic-coefficient配置为733),V = 1100mV,F = 800MHz
P_d_gpu = 733 * 1100 * 1100 * 800 / 1000000000 = 709 mWGPU 静态功耗:DTSI中static-coefficient配置为411000,ts配置为32000 4700 -80 2,则C = 411000,
a = 2,b = -80,c = 4700,d = 32000,温度为开始降频的温度值T = 75000mC,V = 1100mV
t_scale = ( 2 * 75000 * 75000 * 75000 / 1000000 ) + ( -80 * 75000 * 75000 / 1000) + ( 4700 * 75000 ) + 32000 * 1000 = 778250
v_scale = 1100 * 1100 * 1100 / 1000000 = 1331
P_s_gpu = 411000 * 778250 / 1000000 * 1331 / 1000000 = 425mW
P_max = P_d_a53 + P_d_a72 + P_d_gpu + P_s_gpu = 4110mW
注意:当前只有GPU有计算静态功耗;当前只是列出计算⽅法,实际上通过exel表格计算⽐较⽅便;
当GPU主频最大为600MHz时
P_d_gpu = 733 * 925 * 925 * 600 / 1000000000 = 376 mWt_scale = ( 2 * 75000 * 75000 * 75000 / 1000000 ) + ( -80 * 75000 * 75000 / 1000) + ( 4700 * 75000 ) + 32000 * 1000 = 778250
v_scale = 925 * 925 * 925 / 1000000 = 791
P_s_gpu = 411000 * 778250 / 1000000 * 791 / 1000000 = 253mWP_max = P_d_a53 + P_d_a72 + P_d_gpu + P_s_gpu = 3605mW
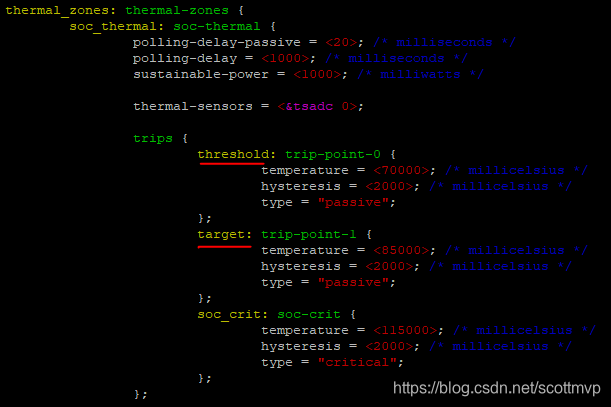
设定75度后才降频,所以可以先让75度时的power为最⼤的power,再通过如下公式计算得sustainable的值:
sustainable + 2 * sustainable / (target- threshold) * (target- 75) = P_75sustainable + 2 * sustainable / (85 - 70) * (85 - 75) = 3605
sustainable = 1545mW
相关内容
通过sys文件系统接口调CPU主频
查看CPU频率属性
A53
[root@rk3399:/]# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_gove
rnors
conservative ondemand userspace powersave interactive performance
[root@rk3399:/]# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_freq
uencies
408000 600000 816000 1008000 1200000 1416000A72
[root@rk3399:/]# cat /sys/devices/system/cpu/cpu4/cpufreq/scaling_available_freq
uencies
408000 600000 816000 1008000 1200000 1416000 1608000 1800000
不同的工作频率对应了不同的工作电压,在userspace模式下,可以设置cpu的工作频率,设置为最大频率时,就可以测量最大的工作电压。
[root@rk3399:/]# echo userspace > /sys/devices/system/cpu/cpu0/cpufreq/scaling_g
overnor
[root@rk3399:/]# echo 1416000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_set
speed
GPU主频
参考文档:
《Rockchip-Developer-Guide-Linux4.4-Devfreq》
Linux4.4内核将频率、电压相关的配置放在了devicetree中,我们将这些配置信息组成的节点,称之为OPP Table。OPP Table节点包含描述频率和电压的OPP节点、leaakge相关配置属性、PVTM相关配置属性等。
gpu_opp_table: opp-table2 {opp-200000000 {opp-hz = /bits/ 64 <200000000>;opp-microvolt = <825000>;opp-microvolt-L0 = <825000>;opp-microvolt-L1 = <825000>;opp-microvolt-L2 = <825000>;opp-microvolt-L3 = <825000>;};
...opp-800000000 {opp-hz = /bits/ 64 <800000000>;opp-microvolt = <1100000>;opp-microvolt-L0 = <1100000>;opp-microvolt-L1 = <1075000>;opp-microvolt-L2 = <1050000>;opp-microvolt-L3 = <1025000>;};};
GPU可以工作在opp-200000000、opp-300000000、opp-400000000、opp-600000000、opp-800000000这五种频率和电压状态。
这篇关于Thermal(1)——温控策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



