本文主要是介绍提取锂离子电池IC(容量增量)曲线的详细过程处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在处理锂离子电池的IC曲线时,发现并非简单的微分便可以提取出平滑的IC曲线,所以自己想了一些方式用于从源数据中提取出平滑的IC曲线用于研究分析。
下面开始,该处理方式主要试用于Arbin电池数据采集器的csv源数据文档处理。
文档的读取不在赘述,大家根据文件的储存形式选取自己习惯的读取处理方式。
库的调用准备:
import numpy as np
import os
import pandas as pd
import matplotlib.pyplot as plt
from scipy.interpolate import interp1d#插值函数
import glob #查找文件目录和文件
from scipy.signal import savgol_filter#平滑处理
from sklearn.neighbors import LocalOutlierFactor#异常值处理,数据清洗
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号自定义函数的定义:
def majority_nan_inf(array):total_num = array.sizenan_num = np.sum(np.isnan(array))inf_num = np.sum(np.isinf(array))if nan_num + inf_num >= int(total_num / 2):return 1else:return 0该函数用于判断该电池循环数据计算后是否绝大部分是异常值
def nan_inf_deal(array):not_nan_indexes = np.where(~np.isnan(array))[0]new_indexes = np.arange(len(array))array = np.interp(new_indexes, not_nan_indexes, array[not_nan_indexes])not_inf_indexes = np.where(~np.isinf(array))[0]new_indexes = np.arange(len(array))array = np.interp(new_indexes, not_inf_indexes, array[not_inf_indexes])return array该函数用于线性填充数据中nan和inf的位置
在每个电池循环做数据处理,排除异常情况

for cycle in cycles_take:if (cycle==0):continue#最开始的0次循环记录有问题,丢弃df_lim = df[df['Cycle_Index'] == cycle]last_max_q = max(dc_q)df_dc = df_lim[(df_lim['Step_Index'] == 10)]dc_v = np.array(df_dc['Voltage'])if (len(dc_v) == 0):continue # 排除无放电数据的循环index=np.where(dc_v>2.2)dc_v=dc_v[index]dc_q=np.array(df_dc['Discharge_Capacity'])[index]if (len (dc_q)==0):continueif (abs(max(dc_q) - last_max_q) > 0.03 or majority_nan_inf(dc_q)):continue#排除容量异常dc_c=np.array(df_dc['Current'])[index]dc_t=np.array(df_dc['Test_Time'])[index]由放电容量退化曲线图可以看到部分循环时刻记录出错,可能是由于突发状况导致记录暂停,马里兰数据记录时大学周围发生枪击案,导致部分电池数据记录中断几天。
IC曲线的计算公式为![]()
可以直接使用源数据中的discharge_capacity做差,只需要使用diff函数即可。
在这里我选择使用梯形近似的方式,使用安时计数法进行微分近似处理
dc_v, indices = np.unique(dc_v, return_index=True)#去除糅杂数据dc_q=dc_q[indices]dc_c = dc_c[indices]dc_t = dc_t[indices]#计算微分dc=dc_c[:-1]+np.diff(dc_c)*0.5#电流微分,每两个点取一个均值,单位Adt=np.diff(dc_t)#单位sdv=np.diff(dc_v)#单位Vdq=dc*dt/3600#As转化为Ahic=dq/dv对于计算出来的IC值,使用LOF算法去除过于异常的取值
if (majority_nan_inf(ic)):continuestart_v=dc_v[:-1]+np.diff(dc_v)*0.5ic=nan_inf_deal(ic)start_v, ic_index = np.unique(start_v, return_index=True)ic=ic[ic_index]#数据清洗eg:某些点由于取点过密导致值太大了ic_change=ic.reshape(-1, 1)lof = LocalOutlierFactor(n_neighbors=10)#10lof.fit(ic_change)outlier_labels = lof.fit_predict(ic_change)# 获取异常值的标记# 取出非异常的点ic_wash=ic[outlier_labels==1]start_v_wash=start_v[outlier_labels==1]杂乱无章的数据不便于我们统计分析,所以需要插值处理得到具有相同索引的数据
ic_number=60v_index=np.linspace(2.81,3.40,ic_number)f_c_wash = interp1d(start_v_wash, ic_wash, kind='cubic', fill_value="extrapolate")deal_wash = f_c_wash(v_index)deal_wash = nan_inf_deal(deal_wash)将插值完成的数据进行平滑处理,得到特征明显的IC曲线
window_size = 15 poly_order = 3 deal_wash_smooth = savgol_filter(deal_wash, window_size, poly_order)最后展示一下使用如上方法处理得到的IC曲线和原始数据之间的区别,可以看到我们的异常值处理和平滑处理使得大量特征得到保留的同时使得IC曲线更加平滑。
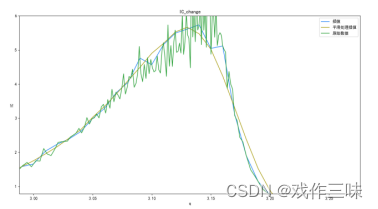
再展示一下对于插值后的数据,平滑处理的对比:
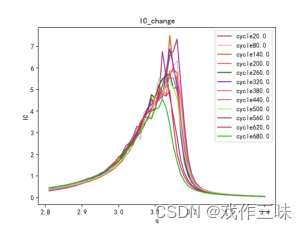
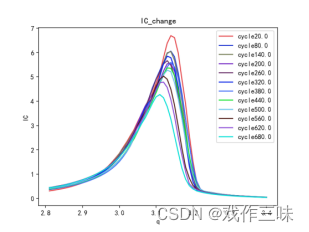
欢迎批评指正,如果本文对你有帮助的话,尽量点赞收藏,谢谢。
本文仅供参考,引用请标注来源。
这篇关于提取锂离子电池IC(容量增量)曲线的详细过程处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







