本文主要是介绍Plotly+Pandas+Sklearn:实现用户聚类分群!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是辰哥~
很多读者问过我:有没有一些比较好的数据分析、数据挖掘的案例?答案是当然有,都在Kaggle上啦。
今天决定开始分享一篇关于聚类的案例,使用的是:超市用户细分数据集。为了方便大家练习,公众号后台回复 211202,即可领取本数据集~

下面分享的是排名Top1的Notebook源码,欢迎参考学习~
一、导入库
# 数据处理
import numpy as np
import pandas as pd
# KMeans聚类
from sklearn.cluster import KMeans# 绘图库
import matplotlib.pyplot as plt
import seaborn as sns
import plotly as py
import plotly.express as px
import plotly.graph_objects as go
py.offline.init_notebook_mode(connected = True)二、数据EDA
导入数据
首先我们导入数据集:
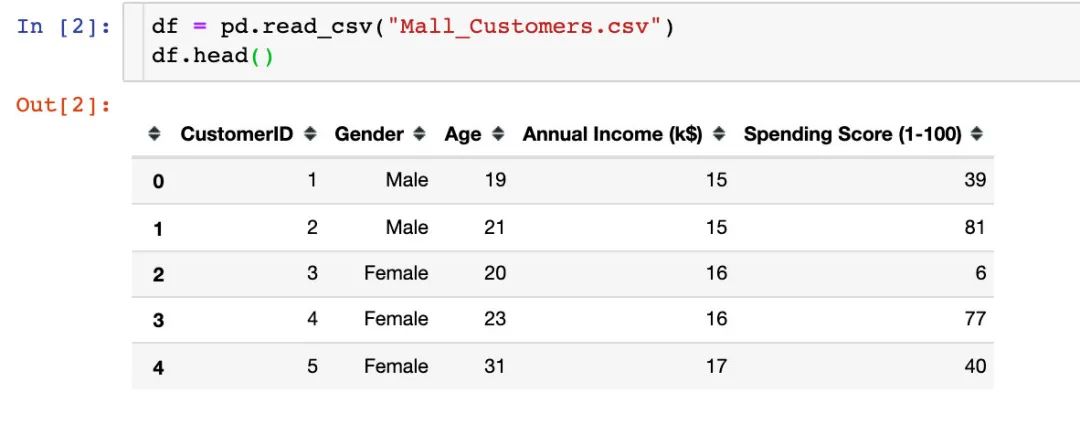
我们发现数据中存在5个属性字段,分别是顾客ID、性别、年龄、平均收入、消费等级
数据探索
1、数据形状shape
df.shape# 结果
(200,5)总共是200行,5列的数据
2、缺失值情况
df.isnull().sum()# 结果
CustomerID 0
Gender 0
Age 0
Annual Income (k$) 0
Spending Score (1-100) 0
dtype: int64可以看到:全部字段都是完整的,没有缺失值
3、数据类型
df.dtypes# 结果
CustomerID int64
Gender object
Age int64
Annual Income (k$) int64
Spending Score (1-100) int64
dtype: object字段类型中,除了性别Gender是字符串,其他都是int64的数值型
4、描述统计信息
描述统计信息主要是查看数值型的数据的相关统计参数的值,比如:个数、中值、方差、最值、四分位数等
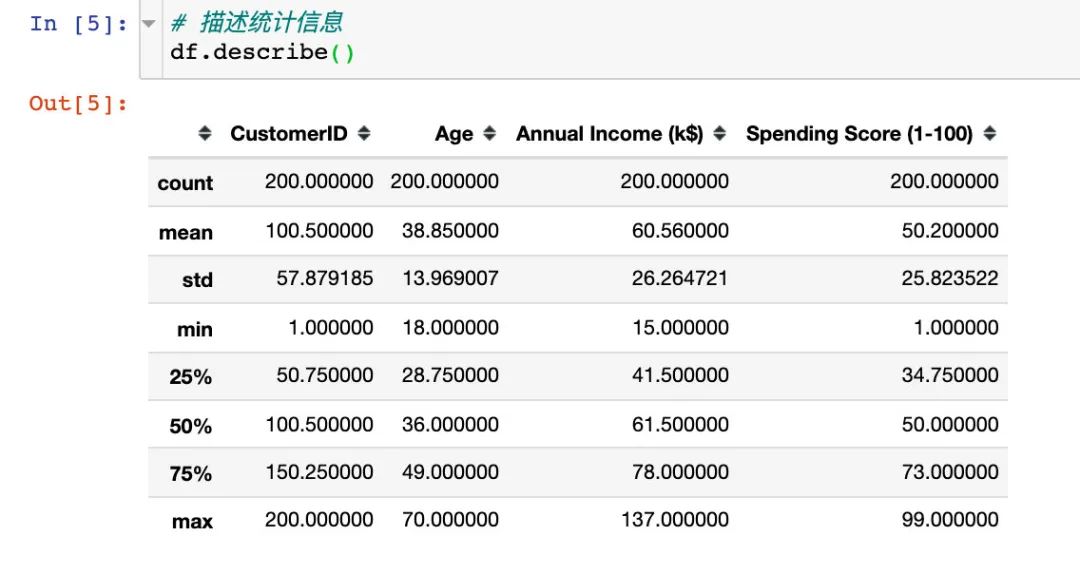
为了后续数据处理方便和展示,处理两点:
# 1、设置绘图风格
plt.style.use("fivethirtyeight")# 2、取出重点分析的3个字段
cols = df.columns[2:].tolist()
cols
# 结果
['Age', 'Annual Income (k$)', 'Spending Score (1-100)']三、3个属性直方图
查看'Age'、 'Annual Income (k$)'、 'Spending Score (1-100)'的直方图,观察整体的分布情况:
# 绘图
plt.figure(1,figsize=(15,6)) # 画布大小
n = 0for col in cols:n += 1 # 子图位置plt.subplot(1,3,n) # 子图plt.subplots_adjust(hspace=0.5,wspace=0.5) # 调整宽高sns.distplot(df[col],bins=20) # 绘制直方图plt.title(f'Distplot of {col}') # 标题
plt.show() # 显示图形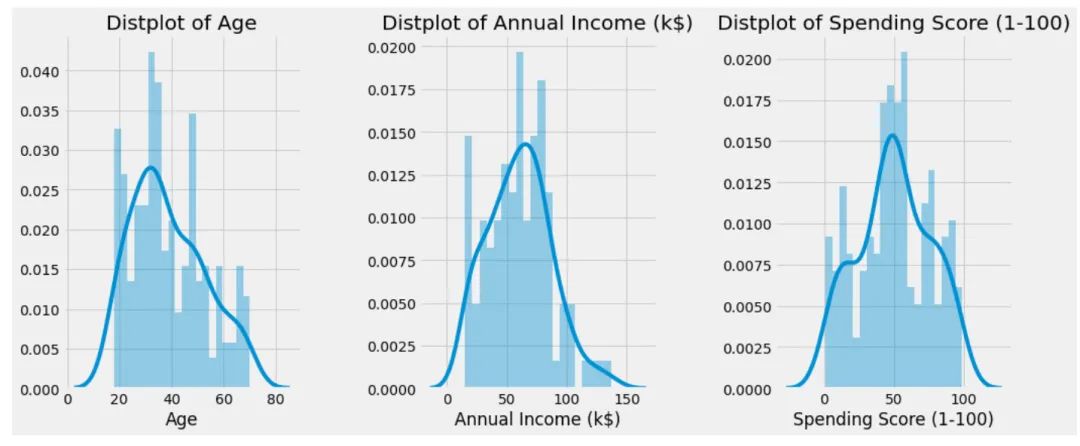
四、性别因素
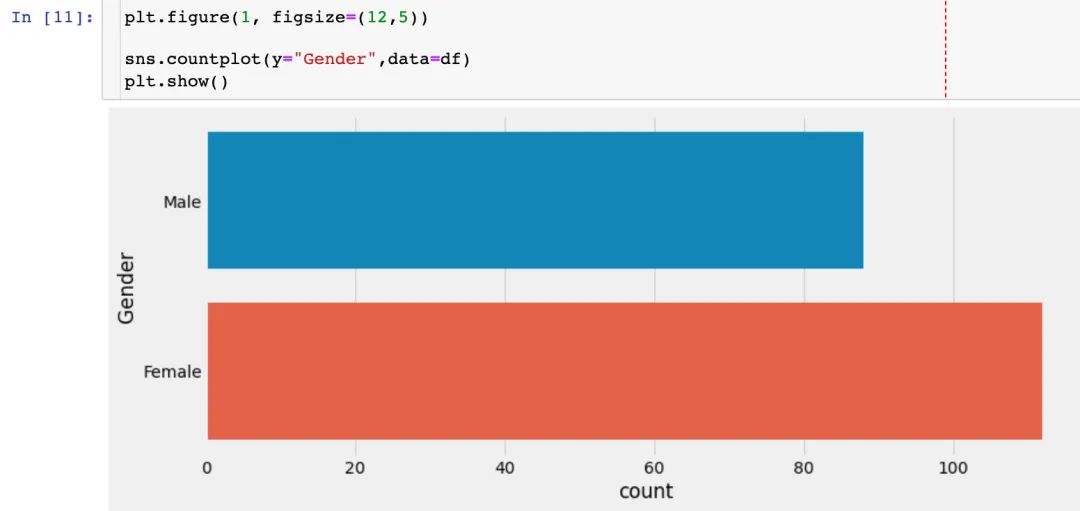
性别人数统计
查看本数据集中男女各有多少人。后续会考虑性别对整体的分析是否有影响。
不同性别下的数据分布
sns.pairplot(df.drop(["CustomerID"],axis=1),hue="Gender", # 分组字段aspect=1.5)
plt.show()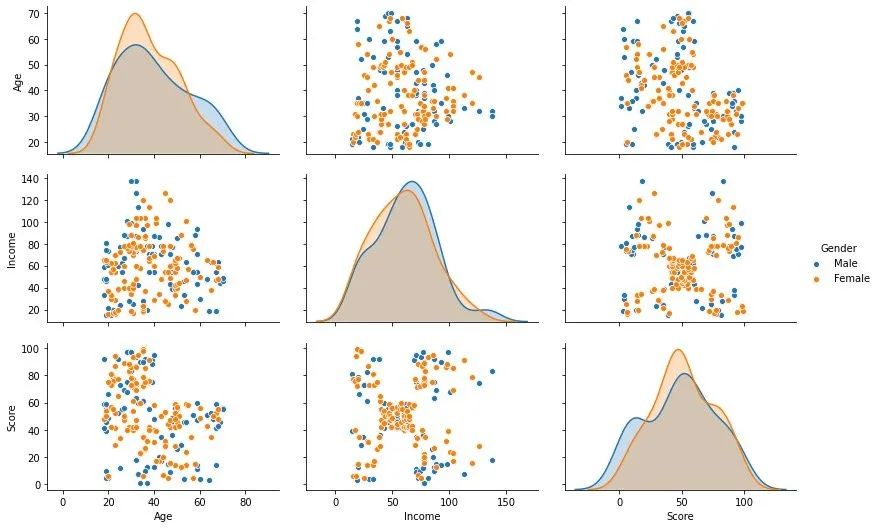
通过上面的双变量分布图,我们观察到:性别因素对其他3个字段的影响不大
不同性别下年龄和平均收入的关系
plt.figure(1,figsize=(15,6)) # 绘图大小for gender in ["Male", "Female"]:plt.scatter(x="Age", y="Annual Income (k$)", # 指定两个分析的字段data=df[df["Gender"] == gender], # 待分析的数据,某个gender下s=200,alpha=0.5,label=gender # 散点的大小、透明度、标签分类)# 横纵轴、标题设置
plt.xlabel("Age")
plt.ylabel("Annual Income (k$)")
plt.title("Age vs Annual Income w.r.t Gender")
# 显示图形
plt.show()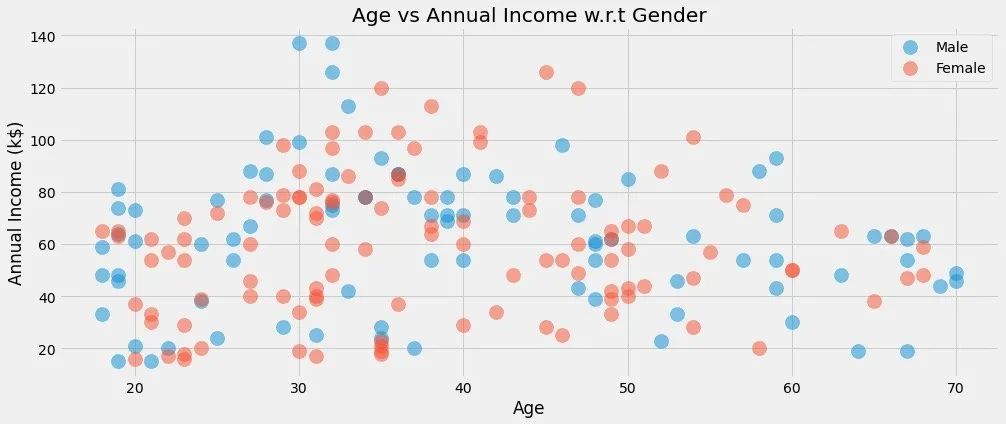
不同性别下平均收入和消费得分的关系
plt.figure(1,figsize=(15,6))for gender in ["Male", "Female"]: # 解释参考上面plt.scatter(x = 'Annual Income (k$)',y = 'Spending Score (1-100)',data=df[df["Gender"] == gender],s=200,alpha=0.5,label=gender)plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.title("Annual Income vs Spending Score w.r.t Gender")
plt.show()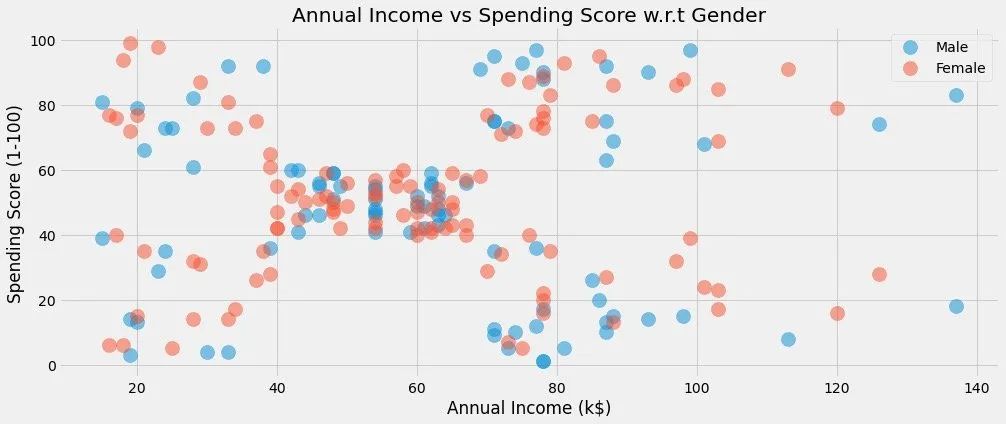
不同性别下的数据分布情况
通过小提琴图和分簇散点图来观察数据分布情况:
# 分簇散点图:Swarmplots
# 小提琴图:violinplotplt.figure(1,figsize=(15,7))
n = 0for col in cols:n += 1 # 子图顺序plt.subplot(1,3,n) # 第n个子图plt.subplots_adjust(hspace=0.5,wspace=0.5) # 调整宽高# 绘制某个col下面的两种图形,通过Gender进行分组显示sns.violinplot(x=col,y="Gender",data=df,palette = "vlag") sns.swarmplot(x=col, y="Gender",data=df)# 轴和标题设置plt.ylabel("Gender" if n == 1 else '')plt.title("Violinplots & Swarmplots" if n == 2 else '')plt.show()结果如下:
查看到不同Gender下不同字段的分布情况
观察是否有离群点、异常值等
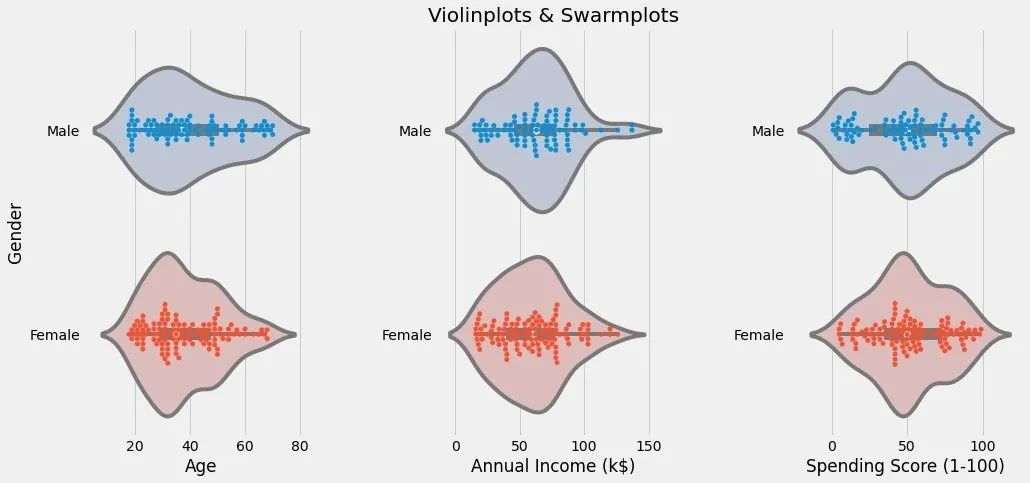
五、属性相关性分析
主要是观察属性两两之间的回归性:
cols = ['Age', 'Annual Income (k$)', 'Spending Score (1-100)'] # 这3个属性的相关性分析plt.figure(1,figsize=(15,6))
n = 0for x in cols:for y in cols:n += 1 # 每循环一次n增加,子图移动一次plt.subplot(3,3,n) # 3*3的矩阵,第n个图形plt.subplots_adjust(hspace=0.5, wspace=0.5) # 子图间的宽、高参数sns.regplot(x=x,y=y,data=df,color="#AE213D") # 绘图的数据和颜色plt.ylabel(y.split()[0] + " " + y.split()[1] if len(y.split()) > 1 else y)plt.show()具体图形为:
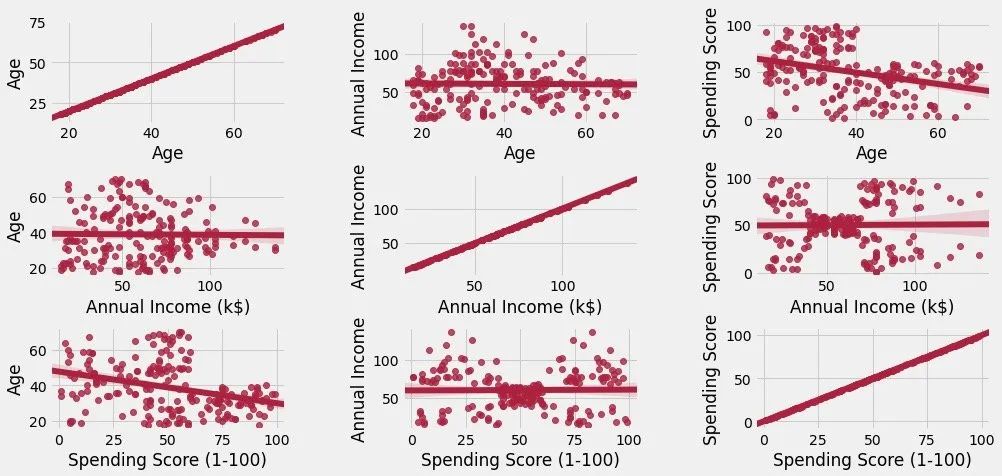
上图表明两点:
主对角线是自身和自身的关系,成正比例
其他图形是属性间的,有数据的散点分布,同时还有模拟的相关趋势图
六、两个属性间的聚类
在这里不具体讲解聚类算法的原理和过程,默认有基础
K值选取
我们通过绘制数据的ELBOW图来确定k值。资料大放送:
1、来自官网的参数解释:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
2、中文解释参考:https://blog.csdn.net/qq_34104548/article/details/79336584
df1 = df[['Age' , 'Spending Score (1-100)']].iloc[:,:].values # 待拟合数据
inertia = [] # 空列表,用来存储到质心的距离之和for k in range(1,11): # k值的选取默认是在1-10之间,经验值是5或者10algorithm = (KMeans(n_clusters=k, # k值init="k-means++", # 初始算法选择n_init=10, # 随机运行次数max_iter=300, # 最多迭代次数tol=0.0001, # 容忍最小误差random_state=111, # 随机种子algorithm="full")) # 算法选择 auto、full、elkanalgorithm.fit(df1) # 拟合数据inertia.append(algorithm.inertia_) # 质心之和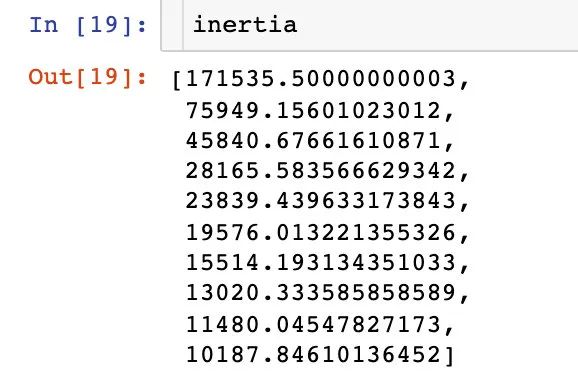
绘制出K值的变化和质心距离之和的关系:
plt.figure(1,figsize=(15,6))
plt.plot(np.arange(1,11), inertia, 'o') # 数据绘制两次,标记不同
plt.plot(np.arange(1,11), inertia, '-', alpha=0.5)plt.xlabel("Choose of K")
plt.ylabel("Interia")
plt.show()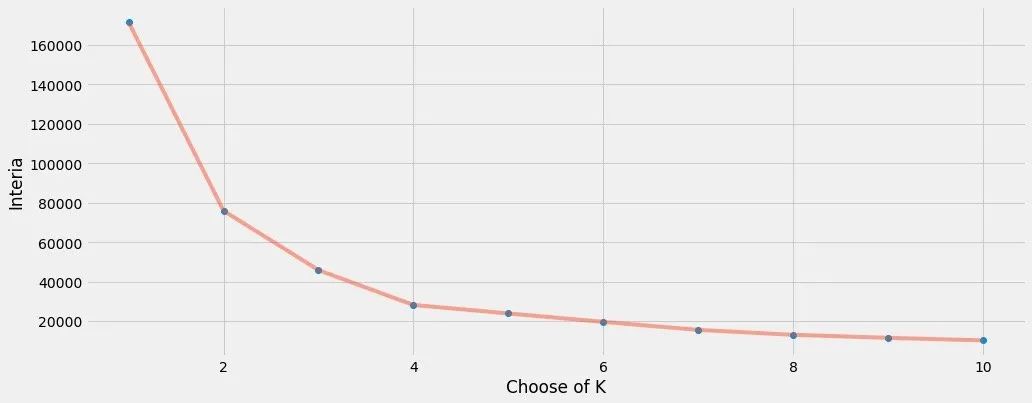
最终我们发现:k=4是比较合适的。于是采用k=4来进行数据的真实拟合过程
聚类建模
algorithm = (KMeans(n_clusters=4, # k=4init="k-means++",n_init=10,max_iter=300,tol=0.0001,random_state=111,algorithm="elkan"))
algorithm.fit(df1) # 模拟数据数据进行了fit操作之后,我们得到了标签label和4个质心:
labels1 = algorithm.labels_ # 分类的结果(4类)
centroids1 = algorithm.cluster_centers_ # 最终质心的位置print("labels1:", labels1)
print("centroids1:", centroids1)
为了展示原始数据的分类效果,官网的案例是下面的操作,我个人觉得有些繁琐:


进行数据合并:

展示分类效果:
plt.figure(1,figsize=(14,5))
plt.clf()Z = Z.reshape(xx.shape)plt.imshow(Z,interpolation="nearest",extent=(xx.min(),xx.max(),yy.min(),yy.max()),cmap = plt.cm.Pastel2, aspect = 'auto', origin='lower')plt.scatter(x="Age",y='Spending Score (1-100)', data = df , c = labels1 , s = 200)plt.scatter(x = centroids1[:,0], y = centroids1[:,1], s = 300 , c = 'red', alpha = 0.5)plt.xlabel("Age")
plt.ylabel("Spending Score(1-100)")plt.show()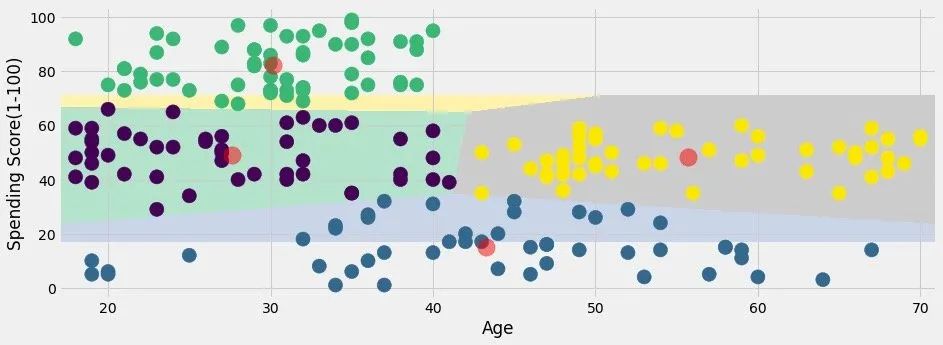
如果是我,怎么做?当然是使用Pandas+Plolty来完美解决:
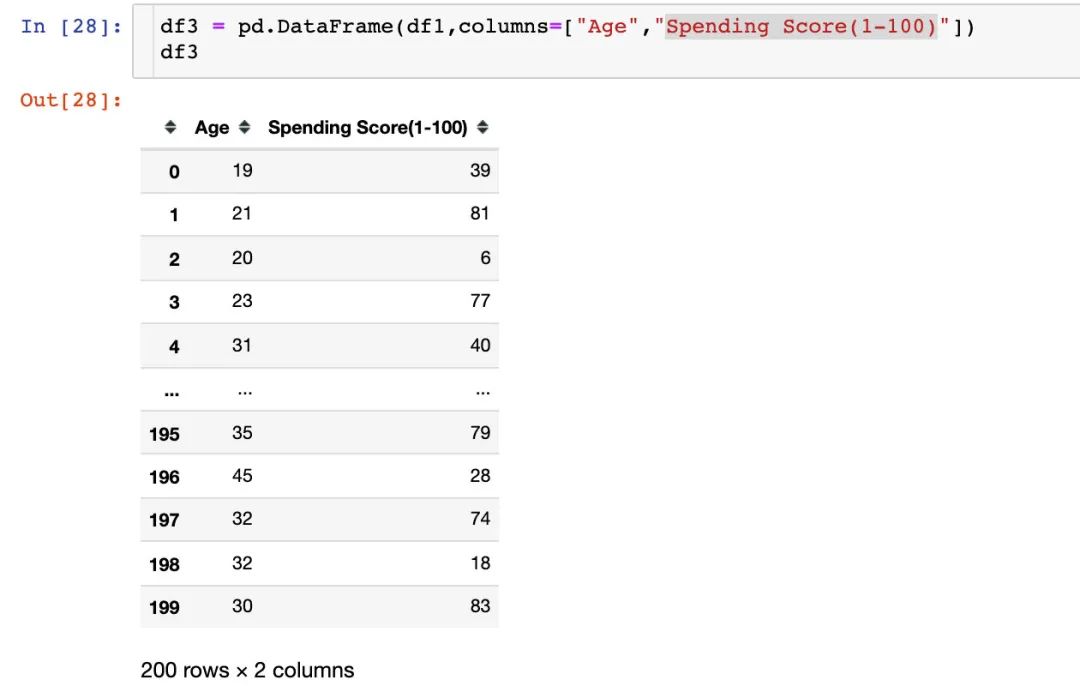
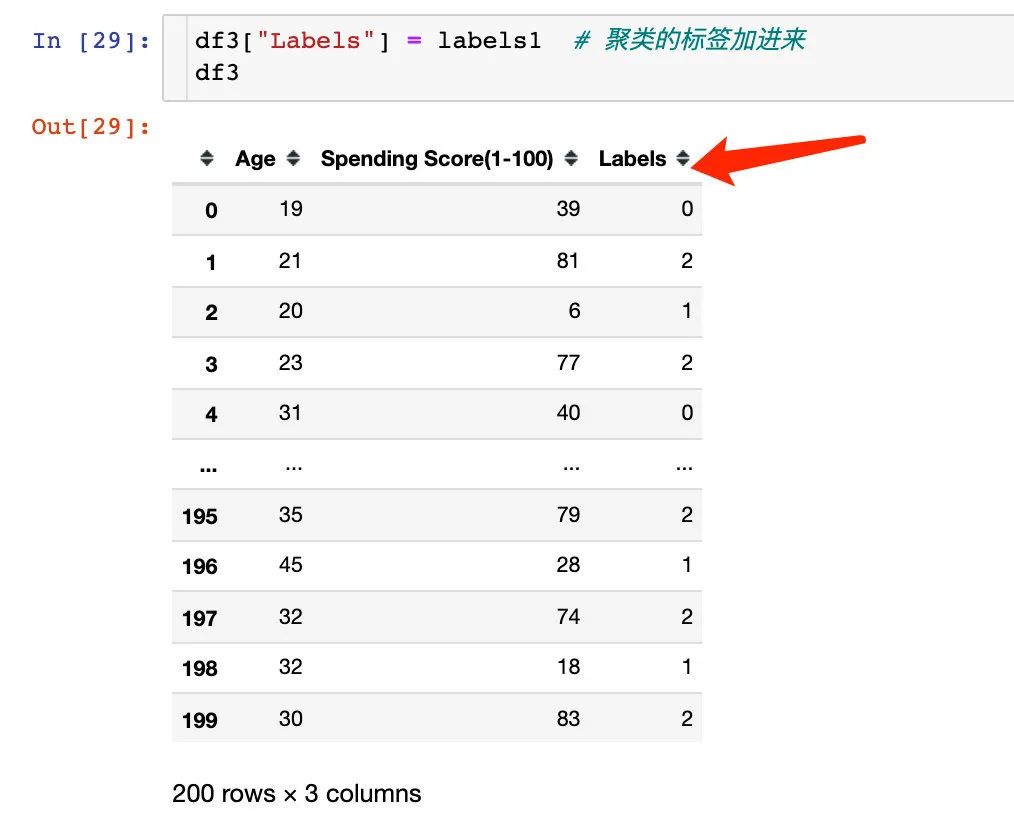
看下分类可视化的结果:
px.scatter(df3,x="Age",y="Spending Score(1-100)",color="Labels",color_continuous_scale="rainbow")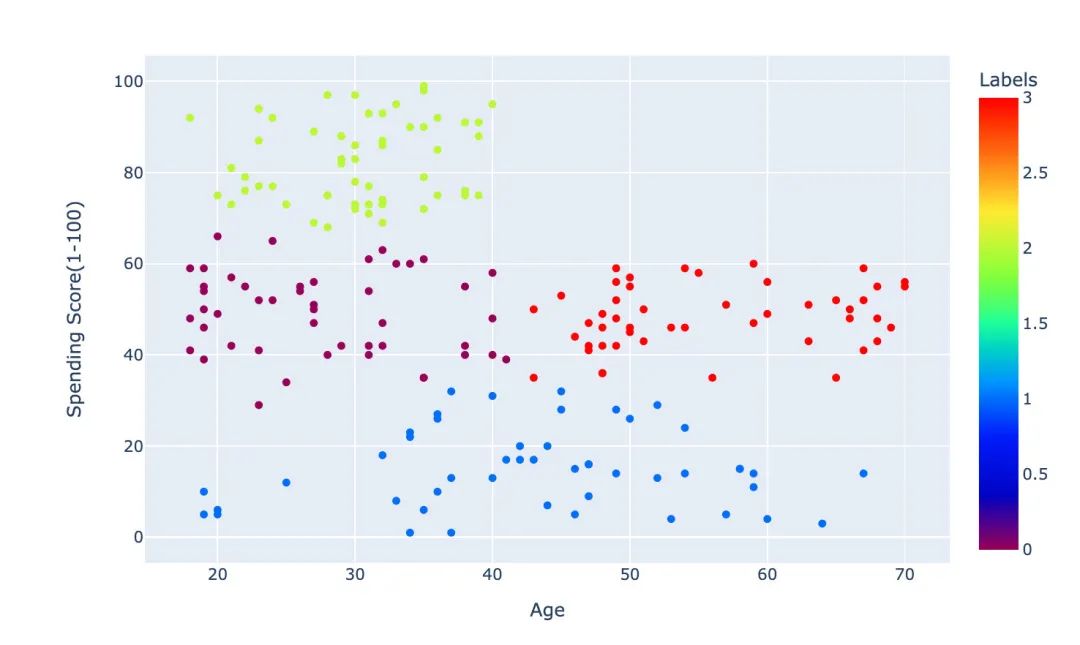
上面的过程是根据Age和Spending Score(1-100)来进行聚类。在官网上基于同样的方法还进行了:Annual Income (k$)和Spending Score (1-100)字段的聚类。
效果如下,分成了5个类:
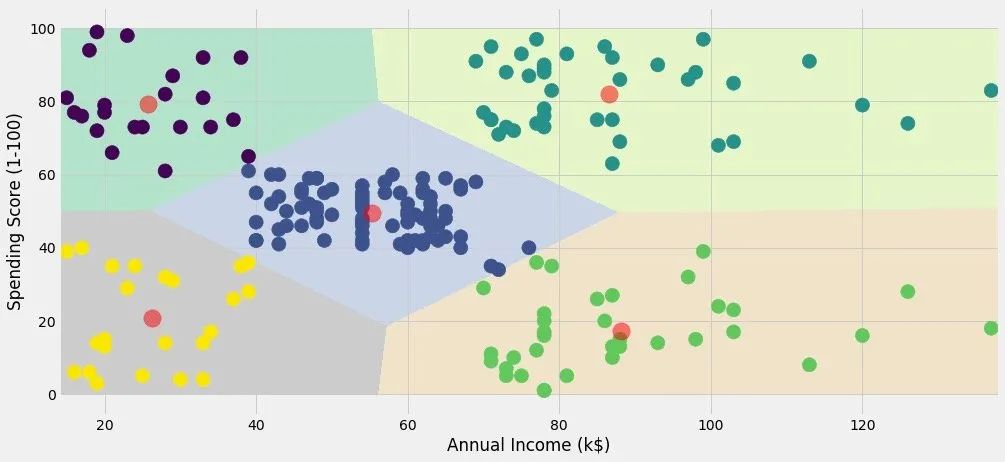
七、3个属性的聚类
根据Age 、 Annual Income 、 Spending Score来进行聚类,最终绘制成3维图形。
K值选取
方法都是相同的,只不过选取了3个字段(上面是某2个)
X3 = df[['Age' , 'Annual Income (k$)' ,'Spending Score (1-100)']].iloc[: , :].values # 选取3个字段的数据
inertia = []
for n in range(1 , 11):algorithm = (KMeans(n_clusters = n,init='k-means++', n_init = 10 ,max_iter=300, tol=0.0001, random_state= 111 , algorithm='elkan') )algorithm.fit(X3) # 拟合数据inertia.append(algorithm.inertia_)绘制肘图确定k:
plt.figure(1 , figsize = (15 ,6))
plt.plot(np.arange(1 , 11) , inertia , 'o')
plt.plot(np.arange(1 , 11) , inertia , '-' , alpha = 0.5)
plt.xlabel('Number of Clusters') , plt.ylabel('Inertia')
plt.show()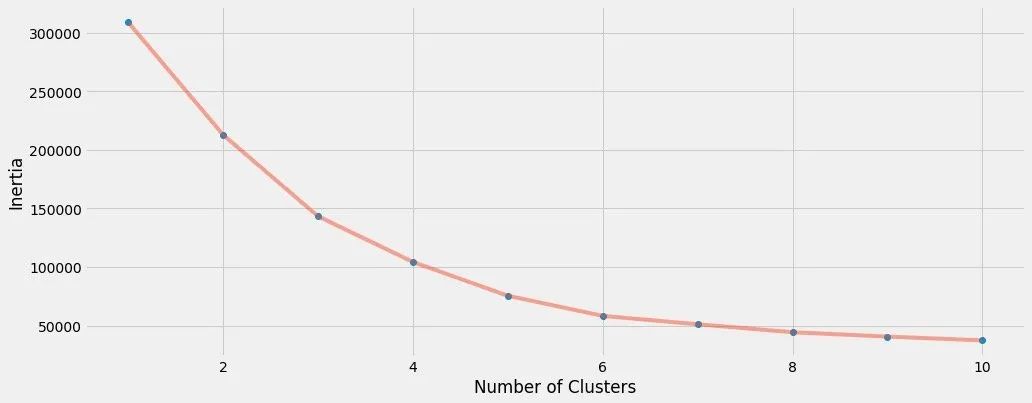
我们最终选取k=6来聚类
建模拟合
algorithm = (KMeans(n_clusters=6, # 确定的k值init="k-means++",n_init=10,max_iter=300,tol=0.0001,random_state=111,algorithm="elkan"))
algorithm.fit(df2)labels2 = algorithm.labels_
centroids2 = algorithm.cluster_centers_print(labels2)
print(centroids2)得到标签和质心:
labels2 = algorithm.labels_
centroids2 = algorithm.cluster_centers_绘图
3维的聚类我们最终选择plotly来展示:
df["labels2"] = labels2trace = go.Scatter3d(x=df["Age"],y= df['Spending Score (1-100)'],z= df['Annual Income (k$)'],mode='markers',marker = dict(color=df["labels2"],size=20,line=dict(color=df["labels2"],width=12),opacity=0.8)
)data = [trace]
layout = go.Layout(margin=dict(l=0,r=0,b=0,t=0),title="six Clusters",scene=dict(xaxis=dict(title="Age"),yaxis = dict(title = 'Spending Score'),zaxis = dict(title = 'Annual Income'))
)fig = go.Figure(data=data,layout=layout)fig.show()下面就是最终的聚类效果:
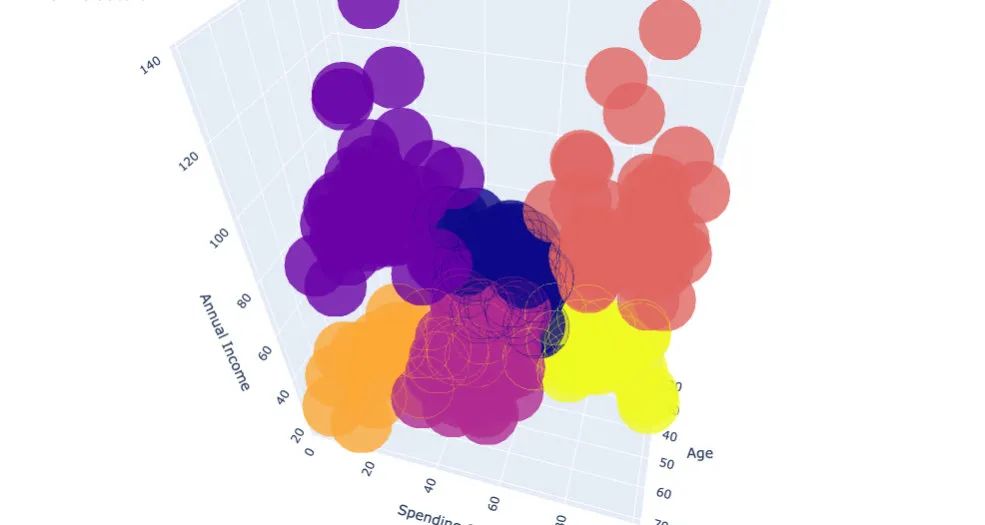
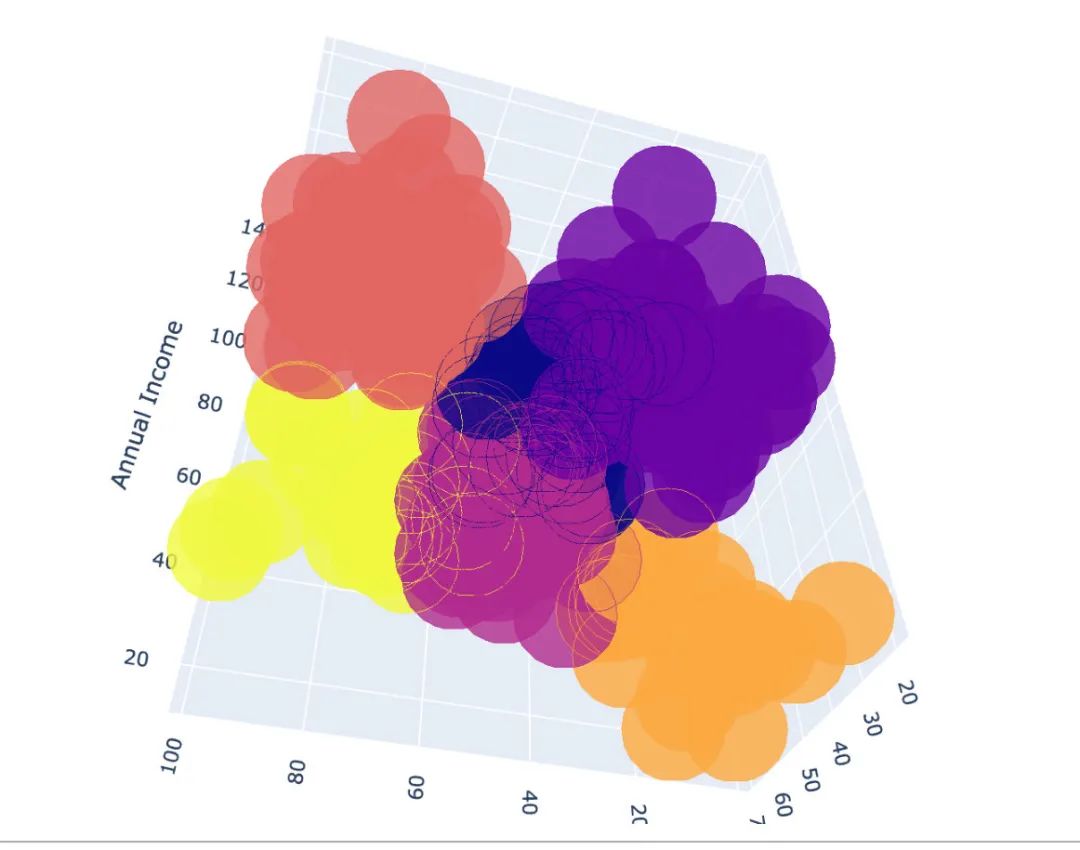
公众号后台回复 211202
即可领取本数据集~

干货推荐


利用可视化神器 Plotly 绘制酷炫图表

5 分钟,使用内网穿透快速实现远程桌面

利用Selenium实现网站自动签到
这篇关于Plotly+Pandas+Sklearn:实现用户聚类分群!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







