本文主要是介绍Chapter4 : Application of Artificial Intelligence and Machine Learning in Drug Discovery,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
reading notes of《Artificial Intelligence in Drug Design》
文章目录
- 1.Introduction
- 2.Generative Chemistry
- 3.Target Profiling
- 4.ADMET Prediction and Scoring
- 5.Synthesis Planning
- 6.Conclusion
1.Introduction
-
In addition to FAIR principles, Schneider et al. provide an excellent discussion on how data should also follow the ALCOA (Attributable, Legible, Contemporaneous, Original and Accurate) guidelines as defined by US FDA.
-
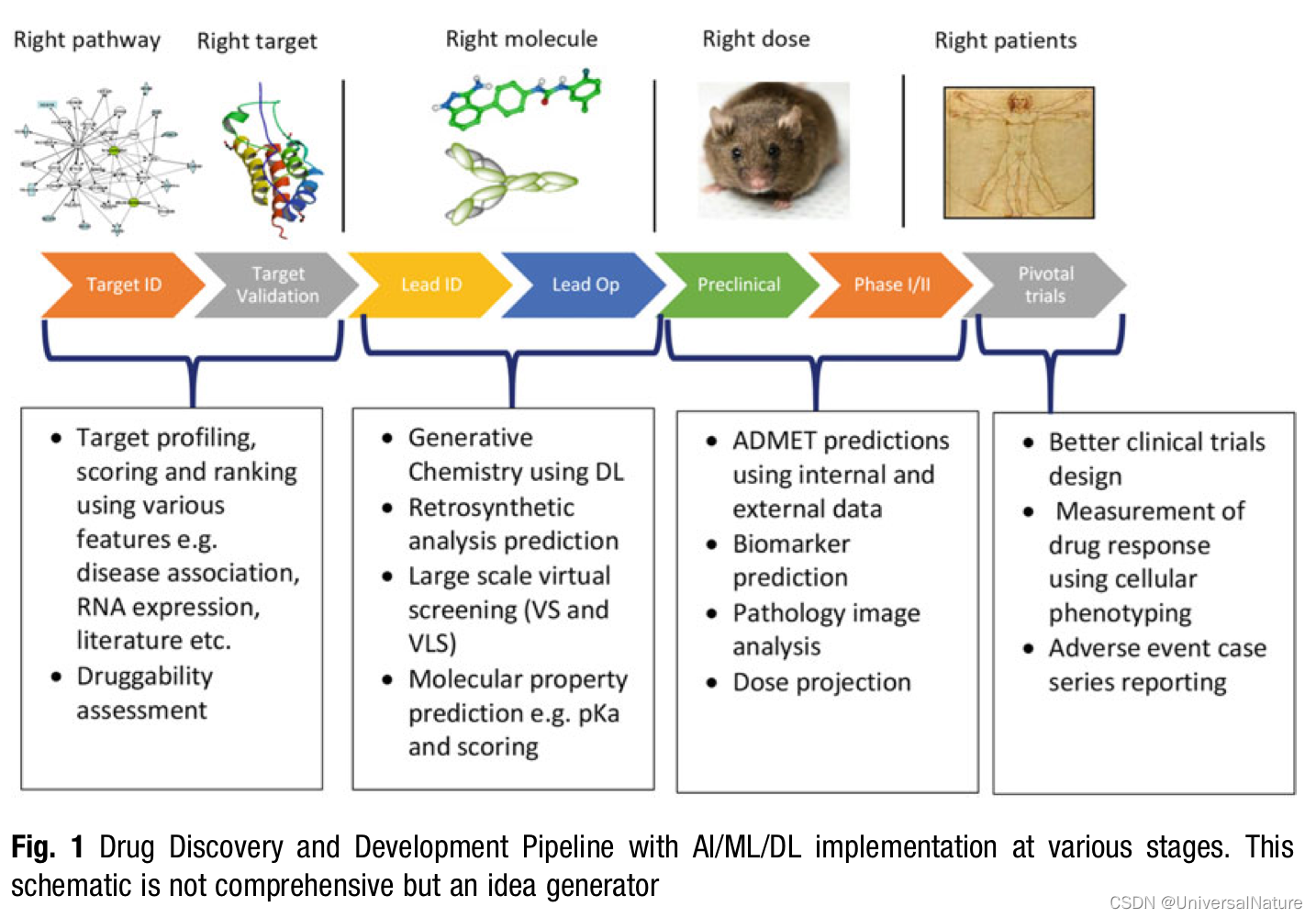
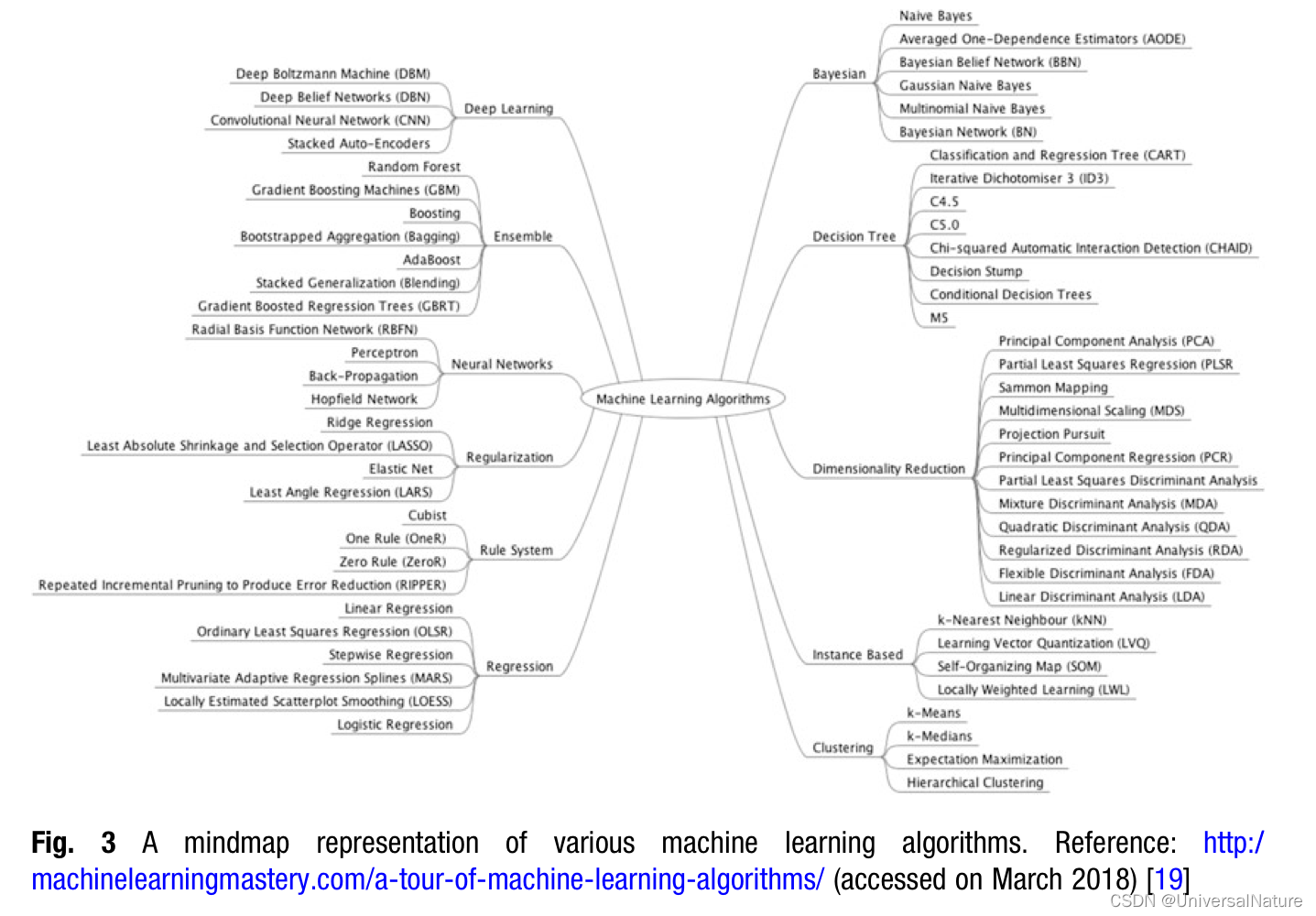
As a general principal when an opportunity or challenge is recognized within the drug discovery pipeline, we first ask ourselves if applying machine learning would be a good idea. Are there other methods that may be better as well as quicker to get us the desired information? This leads to investigating the actual use case as well as evaluating the amount and quality of data available for such application.
2.Generative Chemistry
-
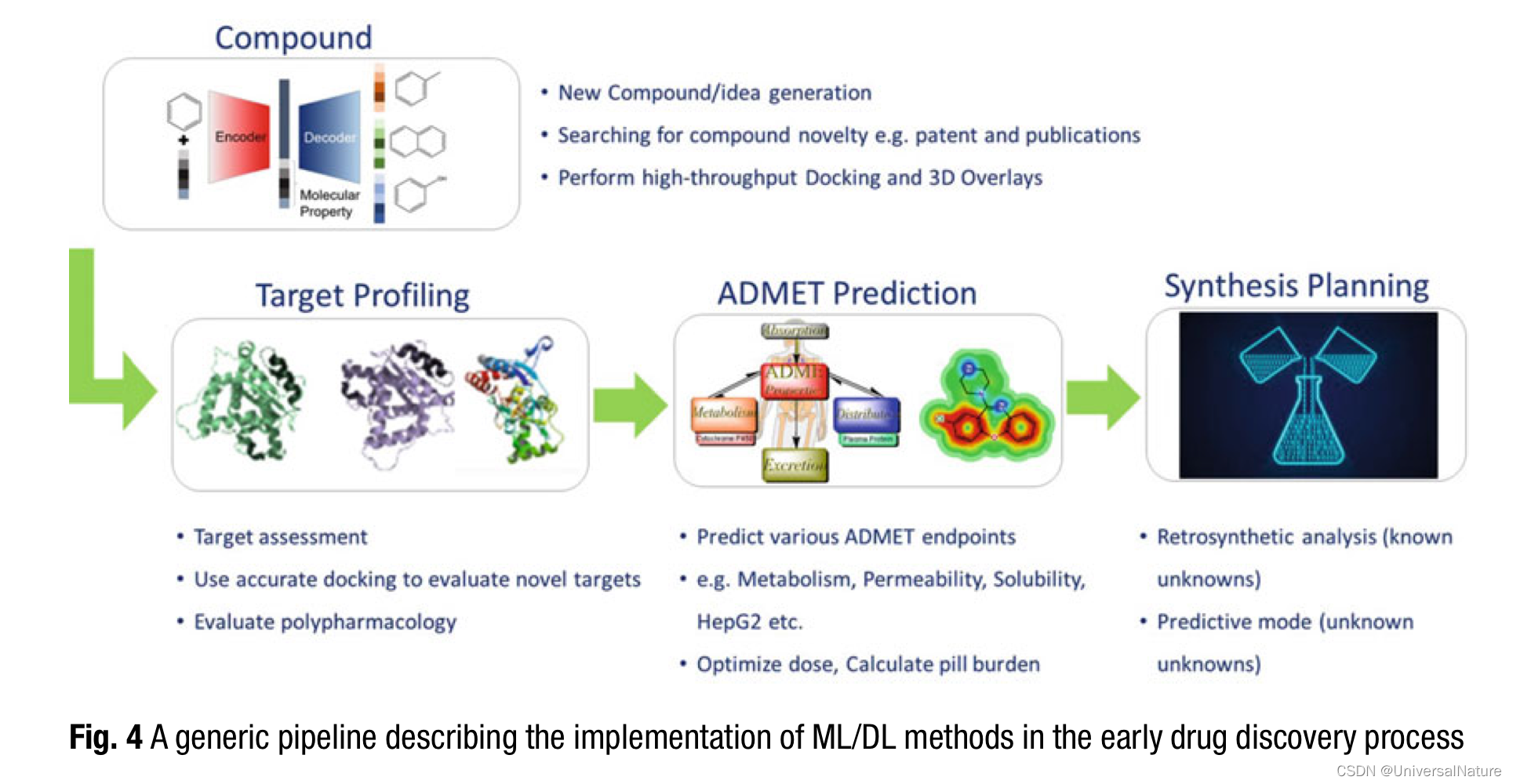
Generative chemistry methods can combine scoring based on multiparameters to allow picking compounds that check most of the criteria as set by the project teams.
-
There has been work done to bring chemistry and biology close to each other by utilizing gene expression information in de-novo compound generation.
-
Potentially possible, it would be useful to allow retrosynthesis be part of the latent space during the generative chemistry process so that users can get synthetically viable compounds.
3.Target Profiling
- The next challenge at hand is target profiling or target assessment. This also includes predicting polypharmacology as well as off-target effects (including toxicity predictions).
- A wishful thinking in the area of target profiling may be to utilize machine learning models using clinical as well as real world evidence (RWE) data in addition to all available preclinical data for better target and disease validation.
4.ADMET Prediction and Scoring
-
Various academic groups and industry have invested a lot of resources to provide these models due to the fact that there are frequent late stage failures due to either undesirable ADME properties or toxicity issues. Some of these properties could be measured in a high throughput fashion and thereby leading to generation of large data sets suitable for machine learning.
-
It’s imperative to discuss a few best practices:
- models should be interpretable
- models should not only be predictable but provide “confidence” for every prediction
- models should be updated routinely to keep them up to data with newly measured data
- Some sort of prospective predictions should be captured at the time of model update process so that project teams can assess the quality of a model for their projects in a prospective way.
-
An interesting idea to work on would be to build machine learning models that can utilize predicted ADMET properties in addition to physchem properties and generate low dose compounds.
5.Synthesis Planning
- In a more recent work by Coley et al., a panel of ~140K reaction templates was developed as a framework.
- There are several limitations:
- sufficiently cover the reaction space
- insufficient negative examples
- To enable collection of a larger dataset that could potentially contain more diverse and both positive and negative examples, one could imagine building a consortium where various pharmaceutical industry representatives can encrypt their respective ELN datasets and share that publicly at a precompetitive level.
6.Conclusion
- We strongly believe that this is the high time when industry embraces these methods and make them part of their routine drug discovery process.
这篇关于Chapter4 : Application of Artificial Intelligence and Machine Learning in Drug Discovery的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![#error: Building MFC application with /MD[d] (CRT dll version) requires MFC shared dll version](/front/images/it_default.jpg)