本文主要是介绍无脑——010 复现yolov8 使用yolov8和rt detr 对比,并训练自己的数据集,标签自动标注,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.配置环境
首先去官网下载yolov8的zip
https://github.com/ultralytics/ultralytics
存放在我的目录下G:\bsh\yolov8
然后使用conda创建新的环境
conda create -n yolov8 python=3.8
#然后激活环境
conda activate yolov8
然后安装pytorch,注意 ,pytorch1.10.0以后的版本才支持rtdetr.pt的两个权重文件。
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch安装 ultralytics
pip install ultralytics
(然后我需要降低pillow的版本从9.3到8.0来适配我的pytorch,因为报错ImportError: DLL load failed while importing _imaging: 找不到指定的模块。:解决方法参考附录1,如果你们不需要请略过)
然后下载官网的权重文件:
https://github.com/ultralytics/assets/releases
这里我下载了一堆权重进行测试:
2.测试环境
然后照一张图片进行测试,
可以参考官方文档
https://docs.ultralytics.com/modes/predict/#inference-arguments
自己照一张图片,放在G:\bsh\yolov8\datademo\bug.jpg里边
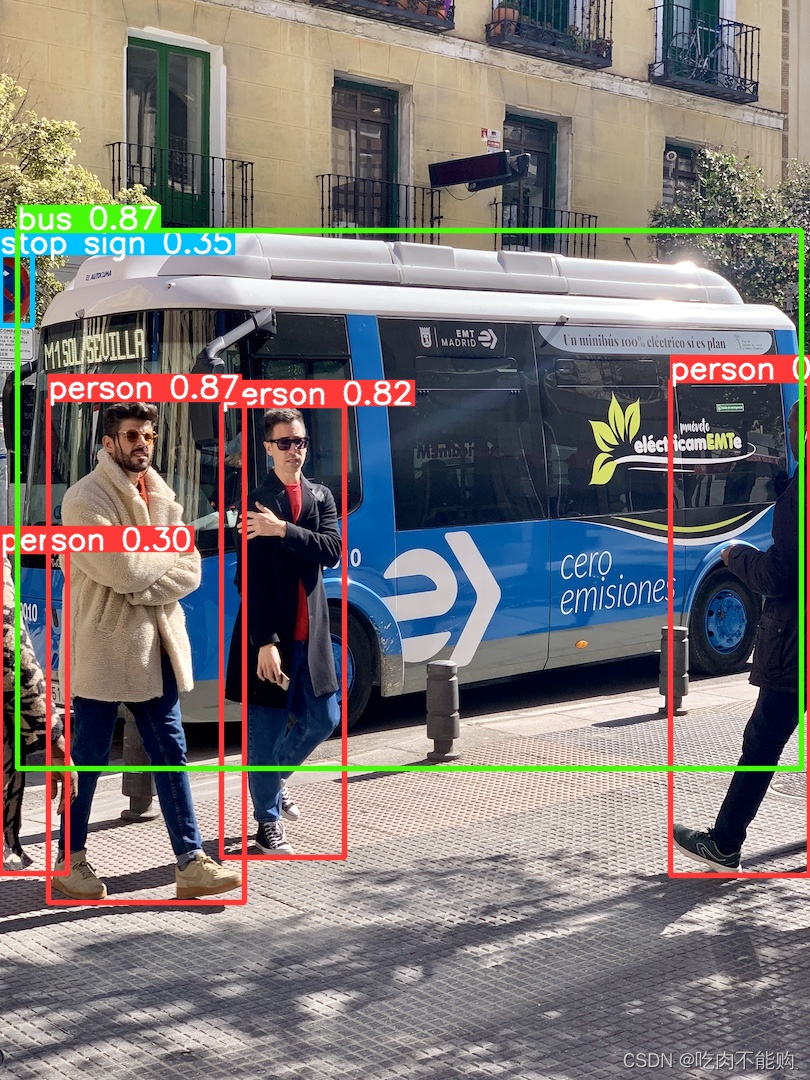
yolo detect predict model=weights/yolov8n.pt source=datademo\bus.jpg
运行结果如下图:
再拿一张自己随便拍的做测试,只能说种类越来越多了,之前yolov5那好像没有鼠标垫?

ps:
检测目录设置成文件夹就行。遍历文件夹里的所有文件进行检测。
yolo detect predict model=weights/yolov8n.pt source=datademo
顺便附上yolov8支持的检测参数
Usage - sources:$ yolo mode=predict model=yolov8n.pt source=0 # webcamimg.jpg # imagevid.mp4 # videoscreen # screenshotpath/ # directorylist.txt # list of imageslist.streams # list of streams'path/*.jpg' # glob'https://youtu.be/Zgi9g1ksQHc' # YouTube'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streamUsage - formats:$ yolo mode=predict model=yolov8n.pt # PyTorchyolov8n.torchscript # TorchScriptyolov8n.onnx # ONNX Runtime or OpenCV DNN with dnn=Trueyolov8n_openvino_model # OpenVINOyolov8n.engine # TensorRTyolov8n.mlpackage # CoreML (macOS-only)yolov8n_saved_model # TensorFlow SavedModelyolov8n.pb # TensorFlow GraphDefyolov8n.tflite # TensorFlow Liteyolov8n_edgetpu.tflite # TensorFlow Edge TPUyolov8n_paddle_model # PaddlePaddle
测了刚才一圈,这些模型,除了yolov_nas的三个模型,都可以正常使用,据作者说暂时不打算加入yolo-NAS,那不知道为什么会有推理的模型,参考附录2.
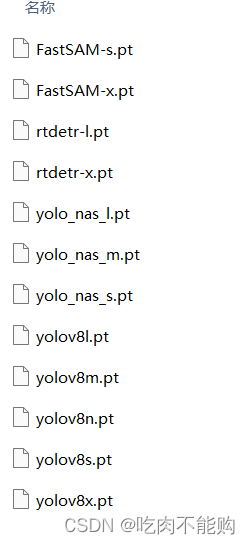
我还意外发现,yolov8s可以检测到键盘,其他的不行

3.准备自己的数据集
使用labelimg准备数据集,软件安装和使用方法可以看我之前的文章
http://t.csdn.cn/MhxVF
只需要使用labelimg标注好Annotations里的xml文件就行,结果长这样
然后运行我写的split_and_t2yolo.py,记得修改你的参数呦呦
# coding:utf-8import random
import argparse
import xml.etree.ElementTree as ET
import os
from os import getcwd'''
如果你的数据集的路径长这样:
G:/bsh/dataset/luosi/Annotations
G:/bsh/dataset/luosi/images
你的类别有小猫 小狗等
classes = ["yuanguojia","naiguojia","huanhuogai","dianchi","shuomingshu","paomoban","xiaohuogai"] # 改成自己的类别
你图片的类型是jpg、png、bmg等等'''
#这里是需要修改的地方,
ProjectPath = 'G:/bsh/dataset/dingzi/' #改成自己的路径,注意最后的/别拉下,否则不能合成路径
classes = ["luoso"] # 改成自己的类别
img_type = 'png' # 改成自己的图片类型,目前只支持三种类型jpg、png、bmg ,如果修改,自己去加到代码第140行#下边的就不用管了
dataAllPath = ProjectPathparser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default=ProjectPath+'Annotations', type=str, help='input xml label path')
# parser.add_argument('--xml_path', default=ProjectPath+'labels', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main0
parser.add_argument('--txt_path', default=ProjectPath+'ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.8 # 训练集所占比例,可自己进行调整xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):os.makedirs(txtsavepath)num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')for i in list_index:name = total_xml[i][:-4] + '\n'if i in trainval:file_trainval.write(name)if i in train:file_train.write(name)else:file_val.write(name)else:file_test.write(name)file_trainval.close()
file_train.close()
file_val.close()
file_test.close()sets = ['train', 'val', 'test']print(dataAllPath)# 使用detect.py产生的标签不需要进行转换
def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open(dataAllPath+'Annotations/%s.xml' % (image_id), encoding='UTF-8')out_file = open(dataAllPath+'labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').text# difficult = obj.find('Difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
for image_set in sets:if not os.path.exists(dataAllPath+'labels'):os.makedirs(dataAllPath+'labels/')image_ids = open(dataAllPath+'ImageSets/Main/%s.txt' % (image_set)).read().strip().split()if not os.path.exists(dataAllPath+'dataSet_path/'):os.makedirs(dataAllPath+'dataSet_path/')list_file = open(dataAllPath+'dataSet_path/%s.txt' % (image_set), 'w')# 这行路径不需更改,这是相对路径for image_id in image_ids:if img_type == 'png':list_file.write(dataAllPath + 'images/%s.png\n' % (image_id))elif img_type == 'jpg':list_file.write(dataAllPath + 'images/%s.jpg\n' % (image_id))elif img_type =='bmg':list_file.write(dataAllPath + 'images/%s.bmp\n' % (image_id))else:print("你的图片格式有问题,自己查一下")convert_annotation(image_id)list_file.close()print("生成成功,去检查一下吧~")
生成对应的标签格式之后,还需要新建一个datazaoju1.yaml文件来存放路径
train: G:/bsh/yolov5/yolov5-master/datavivoimg/dataSet_path/train.txt
val: G:/bsh/yolov5/yolov5-master/datavivoimg/dataSet_path/val.txt# number of classes
nc: 2# class names
names: ["prince", "garfield"]我们就可以开始训练了,以下是训练的代码
4.开始训练
然后运行代码:
yolo task=detect mode=train model=weights/yolov8s.pt data=./data/datazaoj1.yaml batch=4 epochs=50 imgsz=640 workers=4 device=0 close_mosaic=50
这里要把batch和worker调小,因为我的GTX 1060的显卡只有6G的显存,不然 就会电脑死机,记得,训练的过程中,不要打开谷歌浏览器,这玩意占用内存太多了,很容易导致训练失败。最后马赛克增强去掉,不然显存也不够
训练结果比yolov5效果好多了
Validating runs\detect\train16\weights\best.pt...
Ultralytics YOLOv8.0.150 Python-3.8.17 torch-1.10.1 CUDA:0 (NVIDIA GeForce GTX 1060, 6144MiB)
Model summary (fused): 168 layers, 11127906 parameters, 0 gradientsClass Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:00<00:00, 7.51it/s]all 11 45 0.89 0.915 0.982 0.818yuanguojia 11 14 0.774 1 0.986 0.893naiguojia 11 6 0.866 1 0.995 0.879huanhuogai 11 7 0.848 1 0.995 0.795dianchi 11 6 0.883 1 0.995 0.829shuomingshu 11 6 0.966 1 0.995 0.851paomoban 11 6 1 0.491 0.924 0.662
Speed: 0.6ms preprocess, 14.5ms inference, 0.0ms loss, 1.5ms postprocess per image
Results saved to runs\detect\train16
| 名称 | 默认值 | 描述 |
|---|---|---|
| batch | 16 | 训练的批量大小 |
| model | null | 训练模型权重,可指定具体位置,如yolov8n.pt,yolov8n.yaml等 |
| epochs | 100 | 训练的轮次 |
| imgsz | 640 | 输入图像压缩后的尺寸 |
| device | null | 用于训练的设备,可选0或1或cpu等 |
| workers | 8 | 多线程数据加载,默认8 |
| data | null | 数据路径,使用自定义的yaml文件或者官方yaml |
| lr0 | float | 初始学习率 |
| lrf | float | 最终学习率(lr0 * lrf) |
| patience | 50 | 早期训练时,准确率如果没有显著上升则停止的轮次 |
| save | True | 是否需要保存训练的模型和预测结果 |
| cache | False | 使用缓存进行数据加载,可选True/ram, disk 或者 False |
| project | null | 项目名称 |
| name | null | 实验的名称 |
| exist_ok | False | 是否覆盖现有实验 |
| pretrained | False | 是否使用预训练模型 |
| optimizer | ‘SGD’ | 优化器,可选[‘SGD’, ‘Adam’, ‘AdamW’, ‘RMSProp’] |
| verbose | False | 是否打印详细输出 |
| seed | 0 | 重复性实验的随机种子 |
| deterministic | True | 是否启用确定性模式 |
| single_cls | False | 是否将多类数据训练为单类 |
| image_weights | False | 是否使用加权图像选择进行训练 |
| rect | False | 是否支持矩形训练 |
| cos_lr | False | 是否使用余弦学习率调度器 |
| close_mosaic | 10 | 禁用最后 10 个 epoch 的马赛克增强 |
| resume | False | 是否从上一个检查点恢复训练 |
| lr0 | 0.01 | 初始学习率(SGD=1E-2, Adam=1E-3) |
| lrf | 0.01 | 余弦退火超参数 (lr0 * lrf) |
| momentum | 0.937 | 学习率动量 |
| weight_decay | 0.0005 | 权重衰减系数 |
| warmup_epochs | 3.0 | 预热学习轮次 |
| warmup_momentum | 0.8 | 预热学习率动量 |
| warmup_bias_lr | 0.1 | 预热学习率 |
| box | 7.5 | giou损失的系数 |
| cls | 0.5 | 分类损失的系数 |
| dfl | 1.5 | dfl损失的系数 |
| fl_gamma | 0.0 | 焦点损失的gamma系数 (efficientDet默认gamma=1.5) |
| label_smoothing | 0.0 | 标签平滑 |
| nbs | 64 | 名义批次,比如实际批次为16,那么64/16=4,每4 次迭代,才进行一次反向传播更新权重,可以节约显存 |
| overlap_mask | True | 训练期间掩码是否重叠(仅限分割训练) |
| mask_ratio | 4 | 掩码下采样率 (仅限分割训练) |
| dropout | 0.0 | 使用 dropout 正则化 (仅限分类训练) |
5.结果精度评估
然后如果有验证集可以试一下效果:,比如我就没有,所以我就不测试了。接下来直接进入预测的过程
yolo task=detect mode=val model=runs/detect/train3/weights/best.pt data=data/fall.yaml device=0有这么多参数可以选择
| 名称 | 默认值 | 描述 |
|---|---|---|
| val | True | 在训练期间验证/测试 |
| save_json | False | 将结果保存到 JSON 文件 |
| save_hybrid | False | 保存标签的混合版本(标签+附加预测) |
| conf | 0.001 | 用于检测的对象置信度阈值(预测时默认 0.25 ,验证时默认0.001) |
| iou | 0.6 | NMS 的交并比 (IoU) 阈值 |
| max_det | 300 | 每张图像的最大检测数 |
| half | True | 使用半精度 (FP16) |
| dnn | False | 使用 OpenCV DNN 进行 ONNX 推理 |
| plots | False | 在训练期间显示图片 |
其实如果正常训练完成,会自动进行验证评估的,就是最后显示的那一些精准度
6.模型推理预测
然后预测推理测试(模型预测)记得保存标签 savetxt,
yolo task=detect mode=predict model=runs/detect/train3/weights/best.pt source=data/images device=0 save_txt=true| 名称 | 默认值 | 描述 |
|---|---|---|
| source | ‘ultralytics/assets’ | 图片或视频的源目录 |
| save | False | 是否保存结果 |
| show | False | 是否显示结果 |
| save_txt | False | 将结果保存为 .txt 文件 |
| save_conf | False | 保存带有置信度分数的结果 |
| save_crop | Fasle | 保存裁剪后的图像和结果 |
| conf | 0.3 | 置信度阈值 |
| hide_labels | False | 隐藏标签 |
| hide_conf | False | 隐藏置信度分数 |
| vid_stride | False | 视频帧率步幅 |
| line_thickness | 3 | 边界框厚度(像素) |
| visualize | False | 可视化模型特征 |
| augment | False | 将图像增强应用于预测源 |
| agnostic_nms | False | 类别不可知的 NMS |
| retina_masks | False | 使用高分辨率分割蒙版 |
| classes | null | 只显示某几类结果,如class=0, 或者 class=[0,2,3] |
结果比较满意
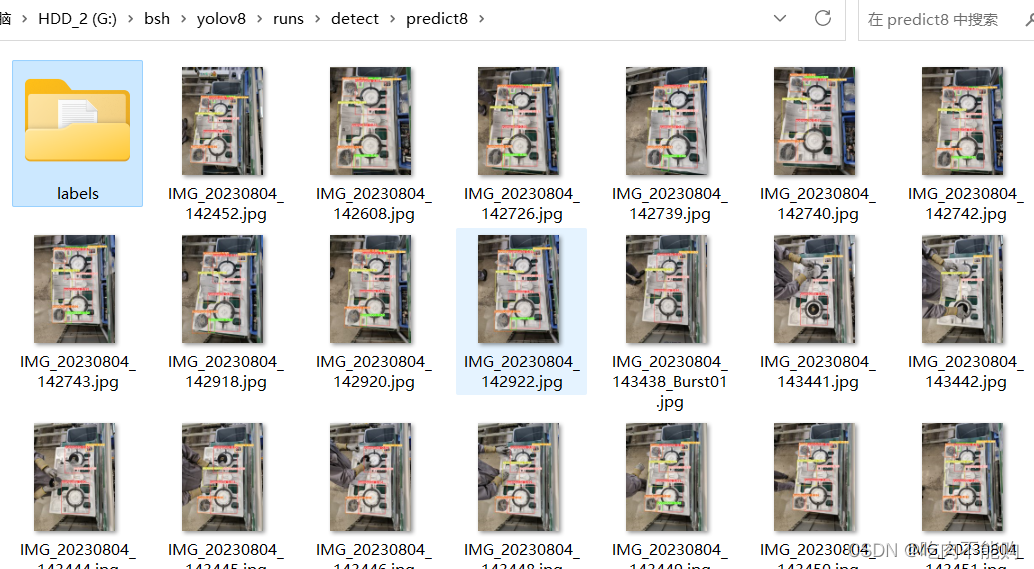

7.保存预测的标签,进行数据集自动标注
预测的标签都保存到了这里:
然后我们到那里去筛选图片,手工筛选,效果不好的删掉,只留下好的,然后使用chooselabels_and_newdata.py把对应的标签保留,其他标签删掉,同时重新生成新的数据集,使用我写的代码,注意修改前面的一部分就行了。
import os
import xml.etree.ElementTree as ET
from os import getcwd
import shutil
import random
import argparse'''
这一部分是你需要修改的
'''
dataAllPath = 'G:/bsh/dataset/zaojv123/ER8PR231MP/' #这里是训练数据集的文件夹# 指定exp72文件夹路径和labels文件夹路径
imgs_folder_path = 'G:/bsh/yolov8/runs/detect/predict16/' # 这里是你已经手工筛选完成后的图片路径
labels_folder_path = 'G:/bsh/yolov8/runs/detect/predict16/labels'# 这里是你已经手工筛选完成后,想要按照对应图片准备删除无效标签的路径
# classes = ["yuanguojia","naiguojia","huanhuogai","dianchi","shuomingshu","paomoban","xiaohuogai"] # 改成自己的类别
classes = ["tiehuojia", "naiguojia", "huanhuogai", "xiaohuogai", "shuomingshu"] # 改成自己的类别
img_type = 'bmp' # 改成自己的图片类型,目前只支持三种类型jpg、png、bmp ,如果修改,自己去加到代码第45行左右和第100行左右
# 指定源文件夹和目标文件夹的路径"""
下面的部分不需要修改
"""
#source_folder = "G:/bsh/yolov8/runs/detect/predict12/labels" # 这是predict生成的labels的文件夹
source_folder = labels_folder_path # 这是predict生成的labels的文件夹
destination_folder = dataAllPath+"labels/" # 这是你准备的数据集的labels的文件夹#destination_folder = "G:/bsh/dataset/dingzi/labels/" # 这是你准备的数据集的labels的文件夹
#后边的部分就不需要修改了,如果图片格式不存在可以自行修改
def move_files(source_folder, destination_folder):# 遍历源文件夹中的文件for file_name in os.listdir(source_folder):source_file = os.path.join(source_folder, file_name)destination_file = os.path.join(destination_folder, file_name)# 检查目标文件夹中是否已存在同名文件if os.path.exists(destination_file):print(f"跳过文件:{file_name},因为已存在相同的文件名")continue# 移动文件到目标文件夹shutil.move(source_file, destination_file)print(f"移动文件:{file_name} 到 {destination_folder}")'''
以后的部分不需要修改
'''
# 获取exp72文件夹中的所有图片文件名(不含扩展名)if img_type == 'png':image_names = [os.path.splitext(file)[0] for file in os.listdir(imgs_folder_path) if file.endswith('.png')]
elif img_type == 'jpg':image_names = [os.path.splitext(file)[0] for file in os.listdir(imgs_folder_path) if file.endswith('.jpg')]
elif img_type == 'bmp':image_names = [os.path.splitext(file)[0] for file in os.listdir(imgs_folder_path) if file.endswith('.bmp')]
else:print("你的图片格式有问题,自己查一下")# 获取labels文件夹中的所有txt文件名
txt_files = [file for file in os.listdir(labels_folder_path) if file.endswith('.txt')]# 遍历labels文件夹中的txt文件
for txt_file in txt_files:# 提取txt文件名(不含扩展名)txt_file_name = os.path.splitext(txt_file)[0]# 检查txt文件名是否在图片文件名列表中if txt_file_name not in image_names:# 不在图片文件名列表中的txt文件,删除txt_file_path = os.path.join(labels_folder_path, txt_file)os.remove(txt_file_path)# 调用函数进行文件移动,把predict预测的labels 文件移动到数据集中,如果有重名选择跳过
move_files(source_folder, destination_folder)# 重新使用汇总后的labels文件夹来生成txt文件
##########################################这里是需要修改的地方,
ProjectPath = dataAllPathparser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default=ProjectPath+'labels', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main0
parser.add_argument('--txt_path', default=ProjectPath+'ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.8 # 训练集所占比例,可自己进行调整xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):os.makedirs(txtsavepath)num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')for i in list_index:name = total_xml[i][:-4] + '\n'if i in trainval:file_trainval.write(name)if i in train:file_train.write(name)else:file_val.write(name)else:file_test.write(name)file_trainval.close()
file_train.close()
file_val.close()
file_test.close()# -*- coding: utf-8 -*-#然后重新划分数据集,汇入预测到的labels标签,
sets = ['train', 'val', 'test']print(dataAllPath)wd = getcwd()
for image_set in sets:if not os.path.exists(dataAllPath+'labels'):os.makedirs(dataAllPath+'labels/')image_ids = open(dataAllPath+'ImageSets/Main/%s.txt' % (image_set)).read().strip().split()if not os.path.exists(dataAllPath+'dataSet_path/'):os.makedirs(dataAllPath+'dataSet_path/')list_file = open(dataAllPath+'dataSet_path/%s.txt' % (image_set), 'w')# 这行路径不需更改,这是相对路径for image_id in image_ids:if img_type == 'png':list_file.write(dataAllPath + 'images/%s.png\n' % (image_id))elif img_type == 'jpg':list_file.write(dataAllPath + 'images/%s.jpg\n' % (image_id))elif img_type == 'bmp':list_file.write(dataAllPath + 'images/%s.bmp\n' % (image_id))else:print("你的图片格式有问题,自己查一下")list_file.close()print("运行完成!去检查一下吧~")至此,就可以使用预测到的标签进行重新训练了
8.对比rt-detr模型
然后用rtdetr-x.pt试试,进行对比
同样的训练代码,worker=4训练不起来,改成了=2也不行,
然后就用rtdetr-l.pt测试了
yolo task=detect mode=train model=weights/rtdetr-l.pt data=./data/datazaoj1.yaml batch=2 epochs=50 imgsz=640 workers=1 device=0 close_mosaic=50
这是我的参数
然后结果:
Validating runs\detect\train20\weights\best.pt...
Ultralytics YOLOv8.0.150 Python-3.8.17 torch-1.10.1 CUDA:0 (NVIDIA GeForce GTX 1060, 6144MiB)
rt-detr-l summary: 498 layers, 31996070 parameters, 0 gradientsClass Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 3/3 [00:00<00:00, 3.91it/s]all 11 45 0.687 0.941 0.951 0.738yuanguojia 11 14 0.699 1 0.885 0.79naiguojia 11 6 0.552 1 0.927 0.868huanhuogai 11 7 0.719 1 0.995 0.729dianchi 11 6 0.475 1 0.995 0.79shuomingshu 11 6 0.676 1 0.995 0.787paomoban 11 6 1 0.644 0.909 0.466
Speed: 1.0ms preprocess, 60.0ms inference, 0.0ms loss, 1.3ms postprocess per image
Results saved to runs\detect\train20
通过对比,发现rtdetr训练的时候需要更大的显存,由于我显存不够,只得把batch调到了2,同样的轮数所以收敛效果不好,比yolov8要差不少。大家可以继续增加训练轮数进行对比
附录1
1.pillow库报错
ImportError: DLL load failed while importing _imaging: 找不到指定的模块。
(yolov8) PS G:\bsh\yolov8> pip show pillow
Name: Pillow
Version: 9.3.0
看出,报错是因为pillow版本过高,直接安装8.0版本即可
pip install pillow==8.0
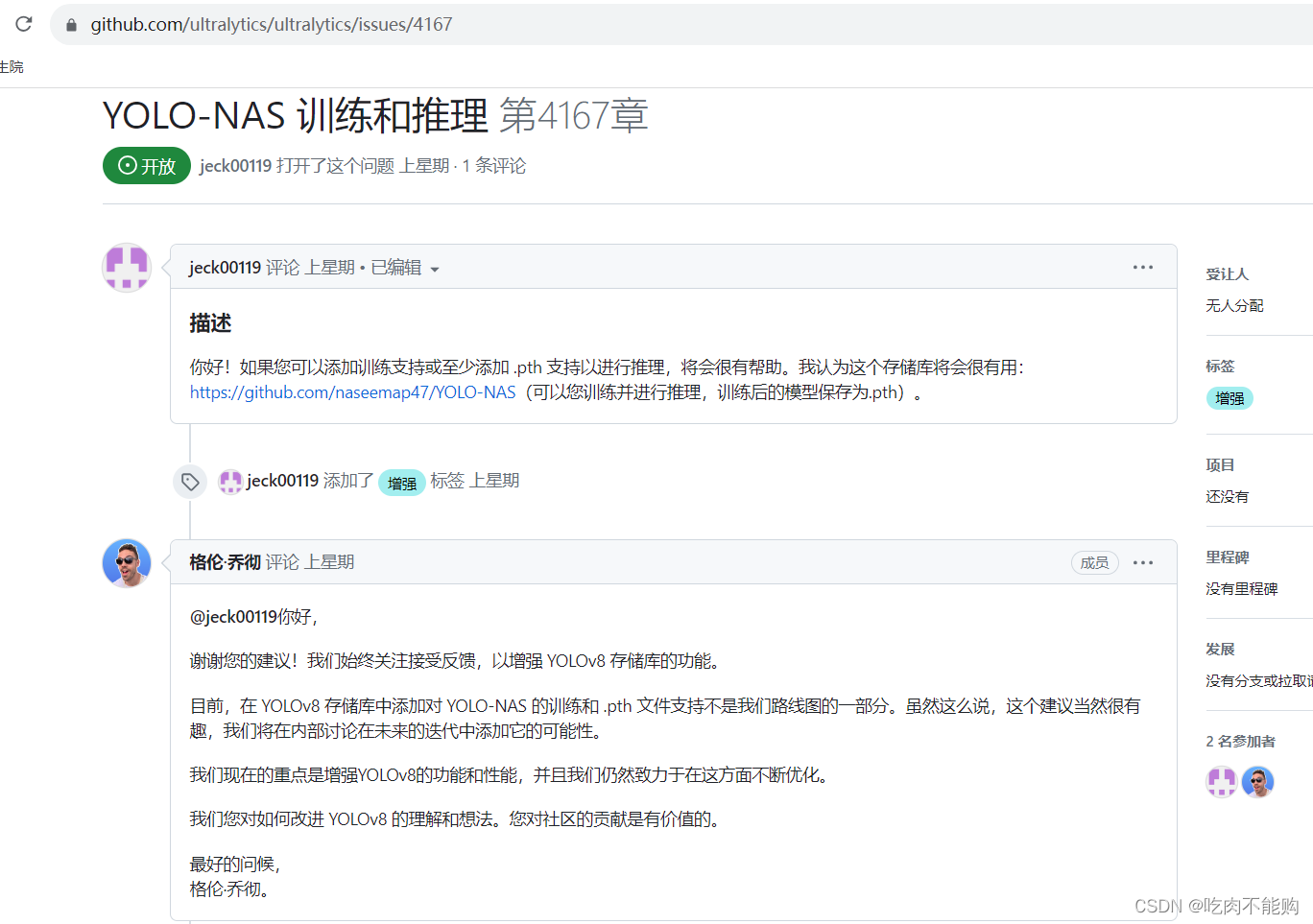
2.yolo_nas测试问题
安装pip install super_gradients之后还是报错LooseVersion = distutils.version.LooseVersion
AttributeError: module ‘distutils’ has no attribute ‘version’
然后又安装的pip install setuptools==59.5.0
最后发现yolov8的框架不支持yolo_nas,作者给出的解释是跟自己的研究路线不相符,如下图:
这篇关于无脑——010 复现yolov8 使用yolov8和rt detr 对比,并训练自己的数据集,标签自动标注的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



