本文主要是介绍华为云盘古大模型登Nature:秒级完成气象预测,速度快10000多倍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
来源:机器之心
华为云盘古气象大模型突破了 AI 预报天气精度不及传统数值预报的世界性难题,该模型是首个精度超过传统数值预报方法的 AI 预测模型,对比传统方法预测速度提升 10000 倍,可秒级完成对全球气象的预测。
天气预报是科学计算中最重要的应用场景之一。它提供了预测未来天气变化的能力,特别是极端天气事件(如洪水、干旱、飓风等)的发生,这对人们日常生活、农业、能源生产、交通运输等领域具有巨大价值。
过去十年中,随着高性能计算设备的迅速发展,数值天气预报(NWP,Numerical Weather Prediction)在每日天气预报、极端灾害预警、气候变化预测等领域取得了巨大的成功。但是随着算力增长的趋缓和物理模型的逐渐复杂化,传统数值预报的瓶颈日益突出。
研究者们开始挖掘新的气象预报范式,深度学习的快速发展带来了一种有前景的方向。如英伟达提出的 FourCastNet 只需要 7 秒就可以计算出 100 个成员的 24 小时预报,这比传统的 NWP 方法快了几个数量级。
然而,在数值方法应用最广泛的领域如中长期预报中,现有的 AI 预报方法精度仍然显著低于数值预报方法,并受到可解释性欠缺、极端天气预测不准等问题的制约。
现阶段,AI 气象预报模型精度不足主要有两个原因:
第一,现有的 AI 气象预报模型都是基于 2D 神经网络,无法很好地处理不均匀的 3D 气象数据。
第二,AI 方法缺少数学物理机理约束,因此在迭代过程中会不断积累迭代误差。
为了解决上述问题,来自华为云的研究人员提出了一种新的高分辨率全球 AI 气象预报系统:盘古气象(Pangu-Weather)大模型。论文于 2023 年 7 月 6 日登上《Nature》。

论文地址:https://www.nature.com/articles/s41586-023-06185-3
该研究训练了 4 个模型,分别为 1 小时间隔、3 小时间隔、6 小时间隔、24 小时间隔模型。为了训练每个模型,研究人员使用 1979-2021 年的气象数据,以小时为单位采样,训练了 100 个 epoch。此外,盘古气象大模型在单个 GPU 上的推理成本为 1.4 秒,比 operational IFS 快 10000 倍以上,与 FourCastNet 相当。
在性能方面,盘古气象大模型是首个精度超过传统数值预报方法的 AI 方法,1 小时 - 7 天预测精度均高于传统数值方法(即欧洲气象中心的 operational IFS),同时预测速度提升 10000 倍,可秒级完成对全球气象的预测,包括位势、湿度、风速、温度、海平面气压等。盘古气象大模型的水平空间分辨率达到 0.25°×0.25° ,时间分辨率为 1 小时,覆盖 13 层垂直高度,可以精准地预测细粒度气象特征。作为基础模型,盘古气象大模型还能够直接应用于多个下游场景。
下面我们看看这项研究具体是如何实现的。
方法介绍
下图为深度网络架构示意图。该架构被称为 3D Earth-specific transformer (3DEST)。研究者将 13 层的高空变量(upper-air variables)和地表变量(surface variables)的气象变量输入到一个深度网络中。然后进行 patch 嵌入以降低空间分辨率,并将降采样的数据组合成一个 3D 立方体。
3D 数据通过一个编码器 - 解码器架构进行传播,该架构源自 Swin transformer,其是 Vision transformer 的一种变体,具有 16 个块。然后输出被分割成高空变量和地表变量,并通过 patch 恢复进行上采样以恢复原始分辨率。
为了向深度网络中注入 Earth-specific 先验知识,该研究设计了一种 Earth-specific 位置偏置,以取代 Swin 的原始相对位置偏置。这种修改使偏置参数的数量增加了 527 倍,每个 3D 深度网络包含大约 6400 万个参数。然而,与基线相比,3DEST 具有相同的计算成本,并且收敛速度更快。
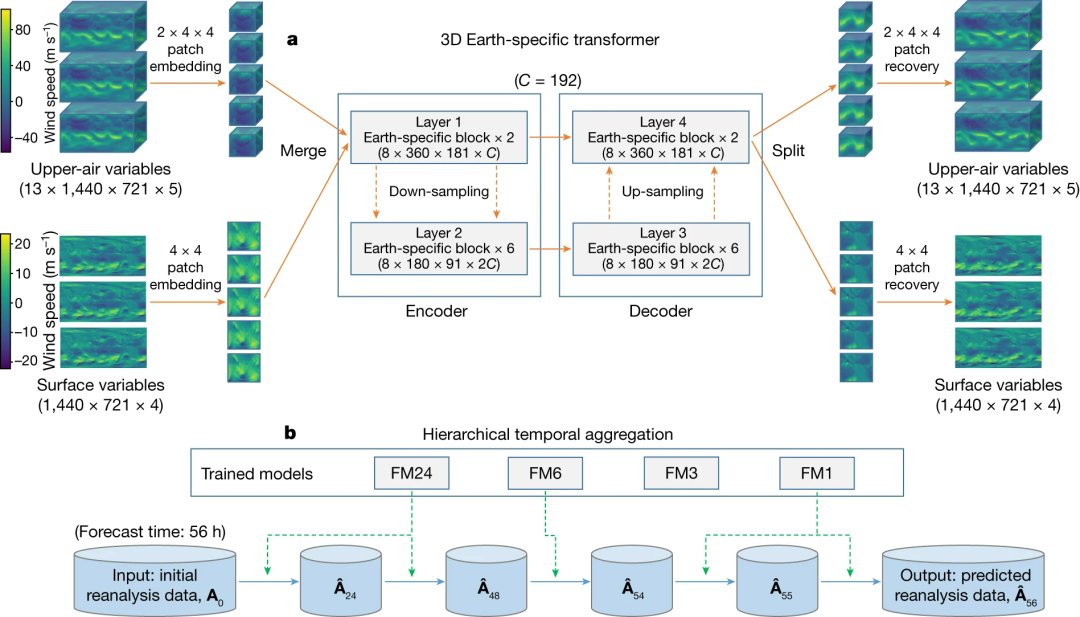
图 1 :3DEST 架构的网络训练和推理策略。
中期天气预报的前导时间(可理解为提前预报的时间)为 7 天或更长,因而需要迭代地调用基本深度网络(前导时间为 1 小时、3 小时、6 小时或 24 小时),然后将每个预测结果作为下一步的输入。为了减少累积的预报误差,该研究引入了分层时间聚合,这是一种贪婪算法,可以大大减少迭代次数。例如,当前导时间为 56 小时时,研究者会执行 24 小时的预报模型 2 次,6 小时的预报模型 1 次,1 小时的预报模型 2 次(图 1b)。与使用固定的 6 小时预报模型的 FourCastNet 相比,本文方法更快且更准确。
网络细节介绍
3DEST 架构的输入和输出数据有两个来源,即高空变量和地表变量。前者涉及 13 个气压层,每个层有 5 个变量,它们共同形成一个 13×1440×721×5 的数据体。后者包含一个 1440×721×4 的数据体。这些参数首先从原始空间嵌入到一个 C 维的潜在空间中。
该研究使用了一种称为 patch 嵌入的常见技术来进行降维。对于高空部分,patch 大小为 2×4×4,因此嵌入数据的形状为 7×360×181×C。对于地表变量,patch 大小为 4×4,因此嵌入数据的形状为 360×181×C,其中 C 是基本通道宽度,设置为 192。然后,这两个数据体沿着第一个维度连接,得到一个 8×360×181×C 的数据体。该数据体随后通过具有 8 个编码器层和 8 个解码器层的标准编码器 - 解码器架构进行传播。解码器的输出仍然是一个 8×360×181×C 的数据体,通过 patch 恢复投影回原始空间,产生所需的输出。
3DEST:每个编码器和解码器层都是一个 3DEST 块。它类似于标准的视觉 Transformer 块,但专门设计用于与地球的几何结构对齐。此外,该研究还使用了视觉 Transformer 的标准自注意力机制。为了进一步降低计算成本,该研究继承了窗口注意机制,将特征图分割成窗口,每个窗口最多包含 2×12×6 个 token。研究人员还应用了移动窗口机制,以使每个层的网格分割与上一层不同,偏移量为窗口大小的一半。由于经度方向上的坐标是周期性的,左右边缘的半窗口合并为一个完整的窗口。由于纬度方向不是周期性的,合并操作没有沿纬度方向进行。
实验
实验设置。该研究在 ERA5 数据上对盘古气象大模型进行了评估。为了公平地比较盘古气象大模型和 FourCastNet,研究者使用了从 1979 年到 2017 年总计 39 年的数据训练 3D 深度网络,并在 2019 年的数据上进行验证,2018 年的数据上进行测试。
本文研究因子包括 69 个,包括 13 个气压水平(50 hPa、100 hPa、150 hPa、200 hPa、250 hPa、300 hPa、400 hPa、500 hPa、600 hPa、700 hPa、850 hPa、925 hPa 和 1000 hPa)下的 5 个高空变量和 4 个地表变量。
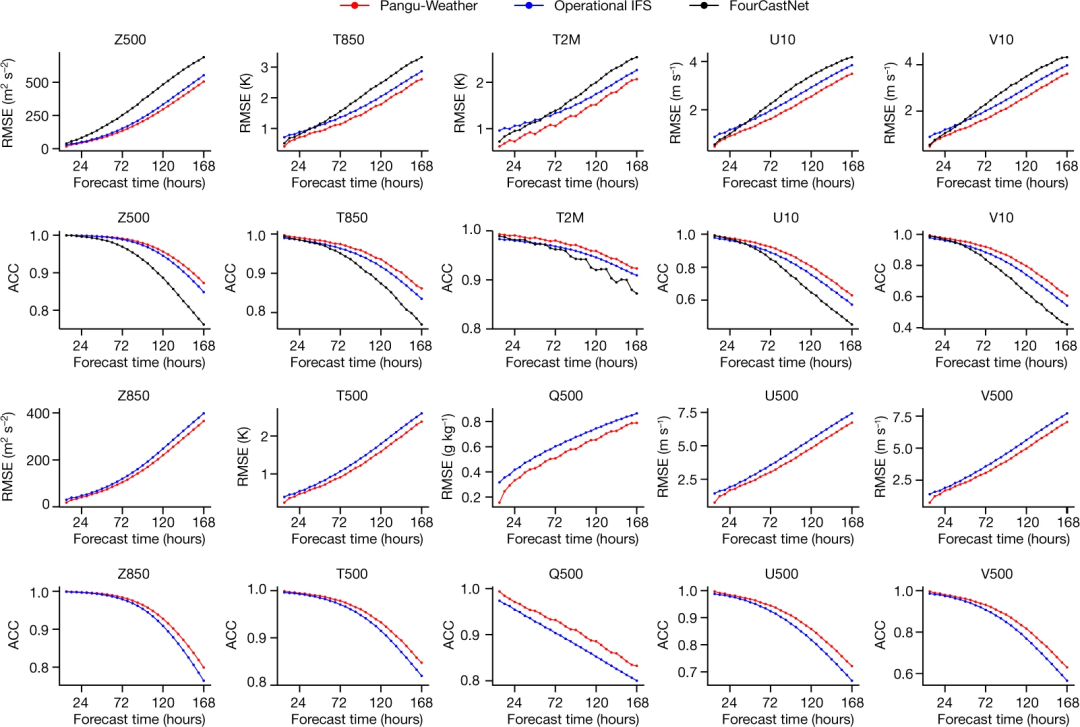
主要结果。当在再分析数据(reanalysis data)上进行测试时,盘古气象大模型在每个测试变量上都产生了比 operational IFS 和 FourCastNet 更低的均方根误差(RMSE)和更高的异常相关系数(ACC)。
此外,盘古气象大模型的推理成本在单个 GPU 上为 1.4 秒,比 operational IFS 快了 10000 倍多,并且与 FourCastNet 持平。盘古气象大模型不仅产生了强大的定量结果(例如,RMSE 和 ACC),而且保留了足够的细节,以便帮助人们研究某些极端天气事件。
确定性全球天气预报
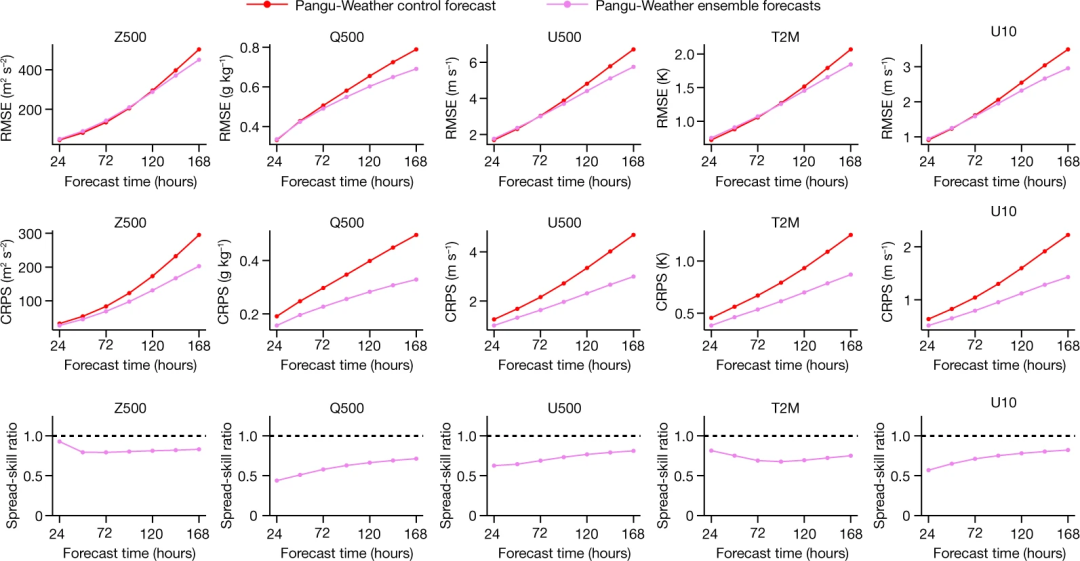
下图为三种方法在 2018 年关于不同天气变量的整体预测结果。对于每个测试变量,包括高空变量和地面变量,盘古气象大模型报告的结果比 operational IFS 和 FourCastNet 更准确。就 RMSE 而言(越低越好),盘古气象大模型报告的值通常比 operational IFS 低 10%,比 FourCastNet 低 30%。这种优势在所有前导时间(从 1 小时到 168 小时,即 7 天)中持续存在,并且对于一些变量(如 Z500),随着前导时间的增加,这种优势变得更加显著。
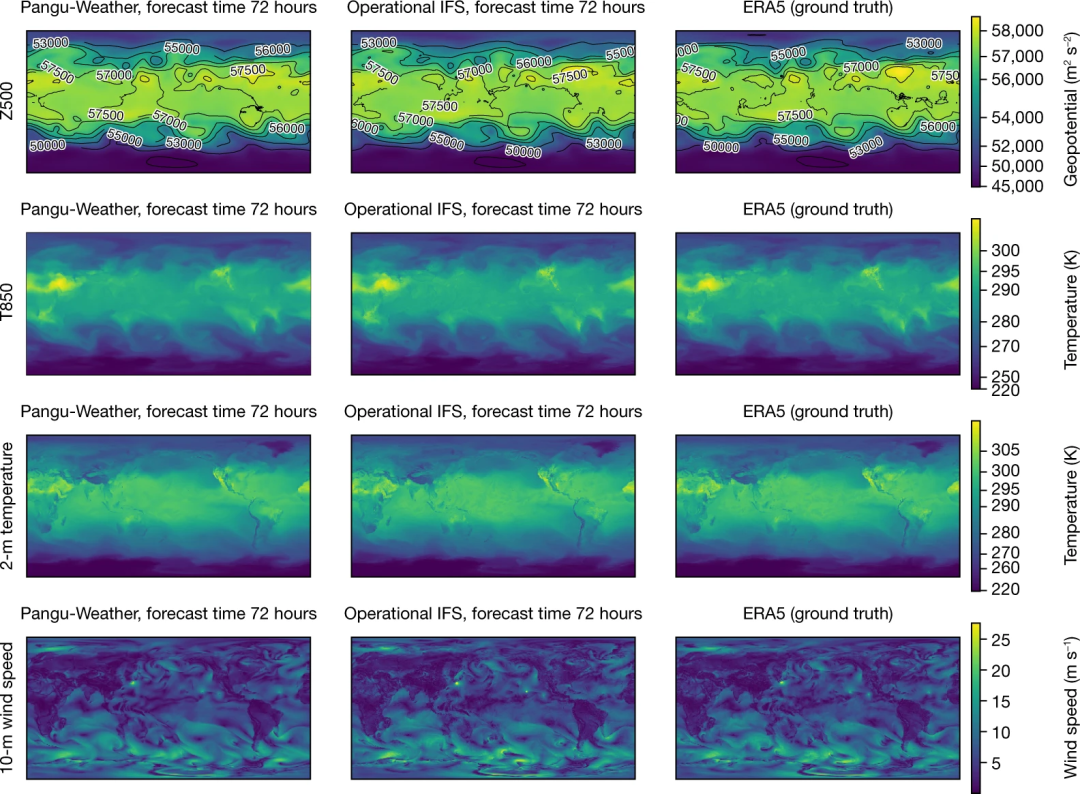
下图可视化了盘古气象大模型 3 天里的预报结果。他们研究了两个高空变量,Z500 和 T850(850 hPa 温度),以及两个地表变量,2 米温度和 10 米风速,并将结果与 operational IFS 和 ERA5 真实数据进行了比较。
结果显示,盘古气象大模型和 operational IFS 的结果与真实数据非常接近,但它们之间仍然存在可见的差异。盘古气象大模型产生了更平滑的等值线,这意味着模型倾向于为相邻区域预测类似的值。相比之下,operational IFS 的预测结果不太平滑,因为它通过解决带有初始条件的 PDE 系统来计算每个网格单元的单个估计值,而天气的混沌性质和不可避免的初始条件以及子网格扩展过程中的不准确性都可能导致每个预报中的统计不准确。
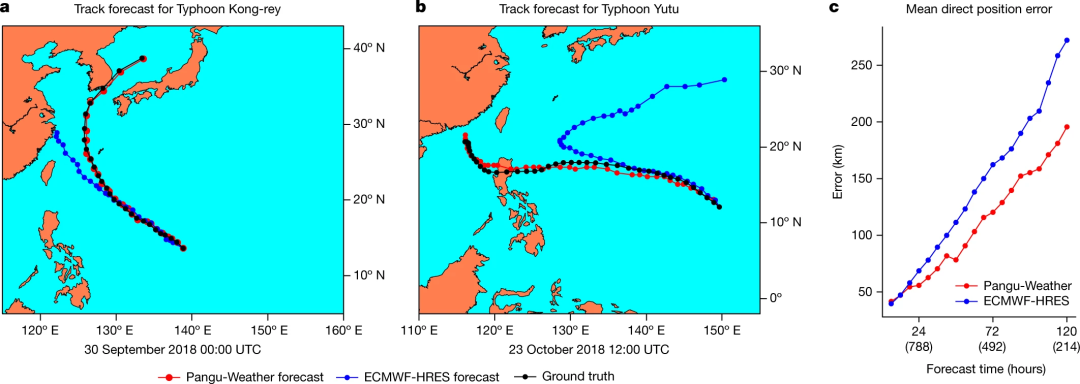
追踪热带气旋
接下来,研究者使用盘古气象大模型追踪热带气旋。
该研究将盘古气象大模型与 ECMWF-HRES 进行了比较,后者是一种强大的气旋追踪方法。该研究选择了 2018 年在 IBTrACS 和 ECMWF-HRES 中都出现的 88 个热带气旋进行比较。如图 4 所示,对于这些气旋,盘古气象大模型在统计上产生了比 ECMWF-HRES 更准确的追踪结果。对于气旋眼的 3 天和 5 天平均直接位置误差,盘古气象大模型报告的数值分别为 120.29 km 和 195.65 km,小于 ECMWF-HRES 的 162.28 km 和 272.10 km。图 4 还展示了西太平洋最强的两个气旋康妮和玉兔的追踪结果。
集合天气预报
盘古气象大模型作为一种基于 AI 的方法,比 operational IFS 快了 10000 倍多。这为以较小的计算成本执行大型成员集合预报提供了机会。
此外,本文还探索了 FourCastNet,以研究一种初步的集合方法,研究生成了 99 个随机扰动,并将它们添加到未扰动的初始状态中。因此,通过简单地对预报结果进行平均,得到了一个具有 100 成员的集合预报。
如下图所示,对于每个变量,在短期(例如 1 天)天气预报中,集合均值略低于单成员方法,但在前导时间为 5-7 天时显著更好。这与 FourCastNet 的结果一致,表明大型成员集合预报在单模型准确性较低时特别有用,但它们可能会为短期预报引入意外的噪音。
最后,想说一下:一直以来业内对华为大模型的动态都比较关注。而无论基础模型还是行业大模型,华为透露的消息都有限。明天,华为HDC大会就正式开幕了,从日程上来看,华为云将会发布一系列大模型内容。不知是否会有一些令人惊艳的新东西?

分享
收藏
点赞
在看
这篇关于华为云盘古大模型登Nature:秒级完成气象预测,速度快10000多倍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








