本文主要是介绍【三维编辑】Editing Conditional Radiance Fields 编辑条件NeRF(ICCV2021),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Editing Conditional Radiance Fields(ICCV 2021)
作者单位:Steven Liu, Xiuming Zhang, Zhoutong Zhang, Richard Zhang
MIT, Adobe Research, CMU
代码地址:https://github.com/stevliu/editnerf
文章目录
- 摘要
- 前言
- 一、相关工作
- 二、方法(编辑条件辐射场)
- 2.1.具有共享分支的网络
- 2.2.编辑(通过模块化的网络的更新)
- 2.3 颜色编辑损失
- 2.4.形状编辑损失
- 三、实验
- 3.1.条件辐射场训练
- 3.2.颜色编辑
- 3.3 形状编辑
- 3.4.形状/颜色码交换(Shape/Color Code Swapping)
- 3.5.真实图像编辑
摘要
神经辐射场(NeRF)是一种支持高质量视图合成的场景模型,对每个场景进行优化。在本文中,我们探索了允许用户编辑一个类别级的NeRF-也被称为条件辐射场(在一个形状的类别上训练)。具体地说,我们介绍了一种将粗糙的二维用户涂鸦传播到三维空间的方法,以修改局部区域的颜色或形状。首先,我们提出了一个条件辐射场,它包含了新的模块化网络组件,包括一个跨实例共享的形状分支。接下来,我们提出了一种针对特定网络组件的混合网络更新策略,以平衡效率和准确性。在用户交互过程中,我们提出了一个既满足用户约束条件,又保留原始对象结构的优化问题。
前言
编辑隐式连续体素表示具有挑战性。首先,我们如何有效地传播稀疏的二维用户编辑,以填充整个相应的三维区域?其次,隐式表示的神经网络有数百万个参数。不清楚哪些参数控制渲染形状的不同方面,以及如何根据稀疏的局部用户输入改变参数。虽然之前的3D编辑工作主要集中于编辑显式表示的,但它们并不适用于神经表征。
本文研究了使用户能够编辑和控制一个三维对象的隐式连续体积表示。如图所示,我们考虑了三种类型的用户编辑: (1)局部外观变色(例如,座椅从米色变为红色);(2)修改局部形状(例如,删除轮子或从其他椅子交换新的手臂);(3)从目标对象实例转移颜色或形状。用户在期望位置上涂鸦,并选择目标颜色或局部形状来执行2D局部编辑。
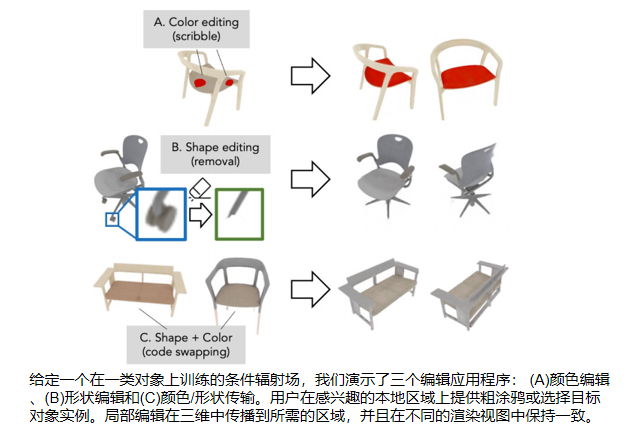
我们研究有效地更新条件辐射场(C-NeRF)以与目标本地用户编辑对齐来解决编辑隐式连续表示的挑战。首先,我们学习整个对象类上的条件辐射场,以建模可信对象的丰富先验。出乎意料的是,这种先验通常允许传播稀疏的用户涂鸦编辑来填充一个选定的区域。我们演示了复杂的编辑,而不需要施加明确的空间或边界约束。其次,为了更准确地重建形状实例,我们在条件辐射域中引入了一个形状分支,该分支跨实例共享,这隐含地影响网络对共享表示进行编码。第三,我们研究了C-NeRF的哪些部分影响不同的编辑任务。我们表明,形状和颜色的编辑可以有效地发生在网络的后期层(我们只更新这些层,显著的计算速度+有效的用户编辑)。最后,我们引入颜色和形状编辑损失,以满足用户指定的目标,同时保留原始对象结构。
实验演示了三个不同外观、形状和训练视图复杂性的形状数据集上的结果。我们还表明,可以编辑一张真实照片的外观和形状,并且该编辑可以传播到外推的新视图。
一、相关工作
我们的工作:新的观点合成和交互外观和形状编辑
- 新视图合成
目标是通过给定一组输入视图来推断场景结构和与视图相关的外观。先前的工作原因是在一个显式的或离散的体素表示的基础几何。然而,两者都有基本的局限性——显式表示通常需要修复结构的拓扑结构,并且有较差的局部最优性,而离散体积方法则不具有更高的分辨率
最近的一些方法在神经网络的权值中隐式地编码了形状的连续体素表示,或与形状和视图相关的外观。最与我们的方法接近的是Schwarz等人的**[GRAF, pi-gan],在一个对象类上建立一个生成辐射场,并包括一个实例的形状和外观的潜在向量**。与他们的方法不同,我们的神经网络中包含了一个实例不可知的分支,它会使网络产生归纳性的偏差,捕获整个形状类的共同特征。这种归纳偏差更准确地捕捉了类的形状和外观。此外,我们不需要一个对抗性的损失来训练我们的网络,而是优化一个 photometric 损失,这允许我们的方法直接对齐到一个新实例的单个视图。
- 交互式外观和形状编辑
在选择和克隆区域和编辑单静止图像的交互工具上已经有很多工作。最近的工作主要集中在通过优化或带有用户引导输入的前馈网络,将用户交互集成到深度网络中。在这里,我们关注的是编辑3D场景,示例界面包括使用膨胀启发式[27]的3D图形绘制和形状编辑,笔画对齐到一个描绘的形状[13],以及从多视图用户笔画[16]学习体素预测。也有编辑3D场景的外观的工作,例如,通过将多通道编辑转移到其他视图[24],基于涂鸦的材料传输[4],在体素表示中编辑3D形状[37],以及使用油漆刷界面[53]重新设置场景。最后,还有编辑光场的工作[25,29,30]。这些工作是在光场或显式/离散体积几何上运行的,而我们试图在学习到的隐式连续体积表示中纳入用户编辑。
一个密切相关的概念是编辑传播,它将单个图像上的稀疏用户编辑传播到整个照片集合或视频中。在我们的工作中,我们的目标是传播用户编辑到体素数据,以便在不同的视点下进行渲染。同样相关的是最近应用局部“基于规则”编辑的图像[ Rewriting a deep generative model]训练的生成模型。我们受到了上述方法的启发,并将其适应于我们新的3D神经编辑设置
二、方法(编辑条件辐射场)
虽然NeRF表示可以渲染一个特定场景的新视图,但我们寻求启用对整个形状类(shape class)的编辑,例如,“椅子”。为此,我们学习了一个条件辐射场模型,它扩展了在形状和外观上的潜在向量的NeRF表示。该表示法是在属于一个类的一组形状上进行训练的,每个形状实例都由潜在的形状和外观向量表示。形状和外观的分离使我们可以在编辑过程中修改网络的某些部分。
设x =(x,y,z)是一个三维位置,d =(φ, θ)是一个观看方向,z(s) 和z©分别是潜在的形状和颜色向量。设 (c, σ)= F (x, d, z(s), z© ) 是一个条件辐射场神经网络,该条件辐射场返回一个辐射c =(r, g, b)和一个标量密度σ。网络F被参数化为一个多层感知器(MLP),这样密度输出σ独立于观看方向,而辐射c取决于位置和观看方向。
为了获得期望相机位置的像素位置的颜色,首先,沿着从像素位置(从近到远排序)的射线r采样Nc 个3D点 ti。然后,用网络 F 计算每个采样点的辐射度和密度值,最后,通过“over” 合成操作[58]计算颜色。设 αi= 1−exp(−σiδi)为采样点 ti 的阿尔法合成值,而 δi = ti+1−ti 为相邻采样点之间的距离。输出像素颜色Cˆ的合成运算为加权和:
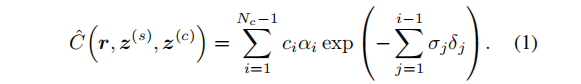
2.1.具有共享分支的网络
NeRF 发现由位置编码和阶段性网络设计所提供的归纳偏差至关重要。类似地,我们发现网络框架设计选择很重要,目标是模块化模型,为形状和颜色分离提供归纳偏差。这些设计选择允许在用户编辑过程中对选定的子模块进行细化(下一节讨论),从而实现更高效的下游编辑。
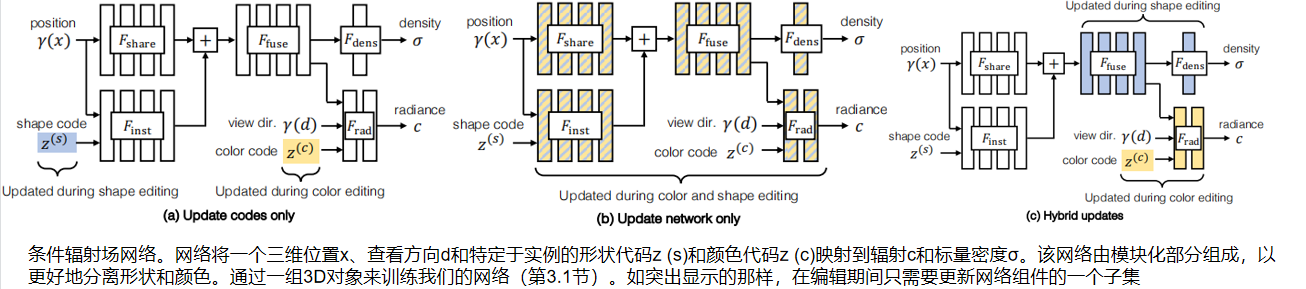
首先,我们学习了一个特定类别的几何表示(利用共享形状网络 Fshare),它只输入位置编码γ(x) 。为了修改特定形状的表示,一个特定于实例的形状网络Finst 以形状代码z(s) 和输入位置编码γ(x)为条件。通过融合形状网络Ffuse 添加和修改表示。为了获得密度预测σ,将Ffuse 的输出传递到一个线性层,即输出密度网络Fdens 。为了获得辐射预测c,将Ffuse的输出与颜色编码z(c) 和编码的观察方向γ(d)连接,并通过两层MLP,即输出辐射网络Frad 。按照原始 NeRF 训练,通过网络的反向传播联合优化潜在编码( latent codes)。
2.2.编辑(通过模块化的网络的更新)
编辑一个由条件辐射场编码的实例。给定具有形状码 zk(s)和颜色码 zk(c)的网络F的渲染,我们希望修改给定一组用户编辑光线的实例。我们希望在网络参数和学习到的 latent code上优化一个损失的 Ledit(F, zk(s), zk(c))
我们的第一个目标是准确地进行编辑——编辑后的辐射场渲染的实例视图,应该能反映用户期望的更改。我们的第二个目标是有效地进行编辑。编辑一个辐射场是很耗时的,因为修改权重需要几十个前向和向后调用。相反,用户应该收到关于他们的编辑的交互式反馈。为实现这两个目标,考虑了以下策略来选择在编辑过程中要更新的参数。
1.更新形状和颜色代码。解决这个问题的一种方法是只更新实例的 latent code,如图2(a)。所示虽然优化这样少的参数可以导致相对有效的编辑,但正如我们将展示的,这种方法会导致低质量的编辑。
2.更新整个网络。另一种方法是更新网络的所有权值,如图2(b).所示正如我们将展示的,这种方法很慢,可能导致实例的未编辑区域发生不必要的更改。
3.混合更新。我们提出的解决方案,如图2©所示,通过更新网络的特定层,实现了准确性和效率。为了减少计算量,我们只微调了网络的后几层。这些选择通过只计算后期层的梯度而不是整个网络来加快优化。在编辑颜色时,我们只更新网络中的 Frad 和z(c),这比优化整个网络的优化时间减少了3.7×(从972秒减少到260秒)。在编辑形状时,我们只更新 Ffuse 和 Fdens,这将优化时间减少了3.2×(从1081秒减少到342秒)
为了进一步减少计算,我们在编辑过程中采取了两个步骤:
1.下采样用户约束。
在训练过程中,我们采样了用户指定的光线的一个小子集。我们发现,随着问题的规模变小,这种选择允许优化收敛得更快。为了编辑颜色,我们随机抽取64条射线,为了编辑形状,我们随机抽取8,192条射线的子集。通过这种方法,我们获得了24×的颜色编辑加速和2.9×的形状编辑加速。此外,我们发现下采样用户约束保持了编辑质量。
2.特征缓存(caching)。
NeRF渲染可能会很慢,特别是当渲染的视图是高分辨率时。为了在颜色编辑期间优化视图渲染,我们缓存在编辑期间不变的网络输出。因为我们只在颜色编辑期间优化Frad,所以在编辑期间Frad 的输入不变。因此,我们缓存 (显示给用户的每个视图的) 输入特性,以避免不必要的计算。这种优化将256×256图像的渲染时间减少了7.8×(从6.2秒减少到0.8秒以下)。
由于在优化过程中训练射线集很小,因此这种缓存在计算上是可行的。我们加速颜色编辑3.2×,形状编辑1.9×
2.3 颜色编辑损失
要编辑实例部件的颜色,用户将选择所需的颜色,并在渲染视图上草绘前景 mask,以指示应该应用该颜色的位置。用户也可以选择一个颜色应该保持不变的背景掩模。mask 不需要详细;相反,每个mask 有一些粗糙的涂鸦。用户通过界面提供这些输入。给定所需的目标颜色和前景/背景 mask,我们试图更新对象实例的神经网络 F 和潜在的颜色向量z(c),以尊守用户的约束。
cf 为用户涂鸦提供的前景 mask 内的像素位置上的射线 r 所期望的颜色,让yf = { (r,cf) } 为整个用户涂鸦提供的一组射线颜色对。此外,对于在背景掩模中的像素位置上的射线r,cb 为在射线位置上的原始渲染颜色。yb = {(r,cb)} 是由背景用户涂鸦提供的一组射线和颜色。给定用户编辑输入(yf,yb),我们将重建损失定义为从合成操作Cˆ到目标前景和背景颜色之间的欧氏距离的平方和:
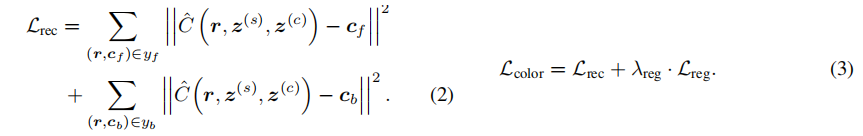
此外,我们定义了一个正则化术语Lreg,通过惩罚原始模型和更新模型权重之间的平方差来防止与原始模型的大偏差。我们将颜色编辑损失定义为重建损失和正则化损失的总和,如公式3.式样中 λreg = 10
2.4.形状编辑损失
对于编辑形状,我们描述了两种操作:形状部分(part)去除和形状部分添加:
1. Shape part removal
为了去除形状部分,用户通过用户界面在渲染视图中涂鸦所需的删除区域。将其作为前景 mask,并将视图的非潦草区域作为背景 mask。为了构建编辑示例,我们白色化了前景 mask 区域。根据编辑示例,我们优化了一个基于密度的损失,以鼓励推测的密度是稀疏的。设 σr 是沿着像素位置的射线r采样点的推断密度值的向量,设 yf 是整个用户涂鸦的前景光线集。我们将密度损失Ldens 定义为预测的密度向量σr 在前景射线位置r处的熵之和:
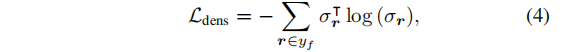
我们将所有的密度向量标准化为单位长度。惩罚沿每条射线的熵会鼓励推断的密度稀疏,使模型预测需要移除区域的密度为0。(上述获得编辑示例的方法假定要删除的期望对象部分不遮挡任何其他对象部分)
我们将形状去除损失定义为重建、密度和正则化损失的总和:
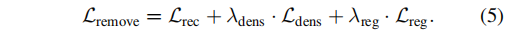
我们使用 λdens = 0.01和 λreg = 10优化Fdens 和Ffuss 的损失。
2. 形状部分添加
为了将局部部分添加到形状实例中,我们将网络匹配到一个复合图像中,该图像包含粘贴到原始对象中的新对象的区域。为了实现这一点,用户首先选择一个原始的渲染视图来进行编辑。我们的界面在相同的视点下显示不同的实例,用户可以选择一个新的复制实例(通过在选定的视图上涂鸦来复制新实例中的一个局部区域)。随后,用户在原始视图中涂鸦,以选择所需的粘贴位置。对于修改的视图中粘贴位置的射线,我们使用新实例的形状代码和原始实例的颜色代码来渲染其颜色,将复合视图的修改区域表示为前景区域,将未修改区域表示为背景区域。我们将形状添加损失 定义为重建损失和正则化损失的总和(λreg = 10):
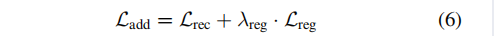
由于大量的训练迭代,这种形状加法方法可能会很慢。在附录中,我们描述了一种更快但效果较差的方法,它鼓励推断的密度来匹配复制的密度。
三、实验
数据集。我们在三个不同复杂性的公开数据集上展示了我们的方法:来自 PhotoShape 数据集的椅子(大外观变化),来自 Dosovitskiy chairs数据集的椅子(大的形状变化),以及来自GRAF CARLA数据集的汽车(每个实例的单一视图)。PhotoShape 数据集使用100个实例,每个实例有40个训练视图;Dosovitskiy chairs数据集使用了500个实例,每个实例有36个训练视图;CARLA数据集使用了1,000个实例,并且每个实例只能访问一个训练视图。对于这个数据集,为了鼓励不同视图之间的颜色一致性,我们规范了辐射的视图方向依赖性。由于每个实例只能访问一个视图,我们放弃了对 CARLA 数据集的定量评估,而是提供了定性评估。
实施细节。我们共享的形状网络、与实例相关的形状网络和融合形状网络Fshare、Finst、Ffuse 都是4层深,256个通道宽的MLPs,具有ReLU激活和输出256维特征。形状和颜色编码都是32维的,并与条件辐射场模型联合优化,使用Adam优化,学习速率为10−4。对于每个编辑,我们使用Adam来优化参数,学习速率为10−2。
3.1.条件辐射场训练
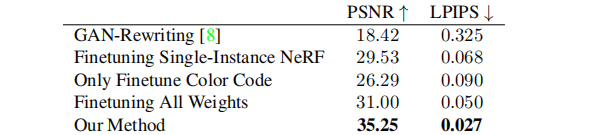
我们的方法准确地模拟了不同实例之间的形状和外观差异。为了量化这一点,我们在PhotoShapes 和 Dosovitskiy chairs数据集 上训练我们的条件辐射场,并评估每个实例的保留视图的渲染精度。在表1中,我们用两个指标来衡量渲染质量: PSNR和LPIPS 。在附录中,我们使用表4中的SSIM度量提供了额外的评估,并在图16-20中可视化了重建结果。我们的模型呈现了每个实例的真实视图,并且在PhotoShapes 数据集上,匹配了为每个实例训练独立的NeRF模型的性能。
我们在表1中报告了对我们的方法的架构选择的消融研究。首先,我们在每个数据集(第1行)上训练一个标准的NeRF。然后,我们为每个实例将一个64维的学习代码添加到标准的NeRF中,并联合训练代码和NeRF(第2行)。在原始NeRF模型中注入位置或方向嵌入时,将注入学习到的代码。虽然这种选择可以为不同实例之间的形状和外观差异进行建模,但我们发现,为每个实例(第3行)添加单独的形状和颜色代码,并进一步使用共享的形状分支(第4行)可以提高性能。最后,我们报告了在每个实例上分别训练独立的NeRF模型时的性能(第5行)。在这些实验中,我们增加了消融层的宽度,以保持在整个实验中参数的数量近似相等。
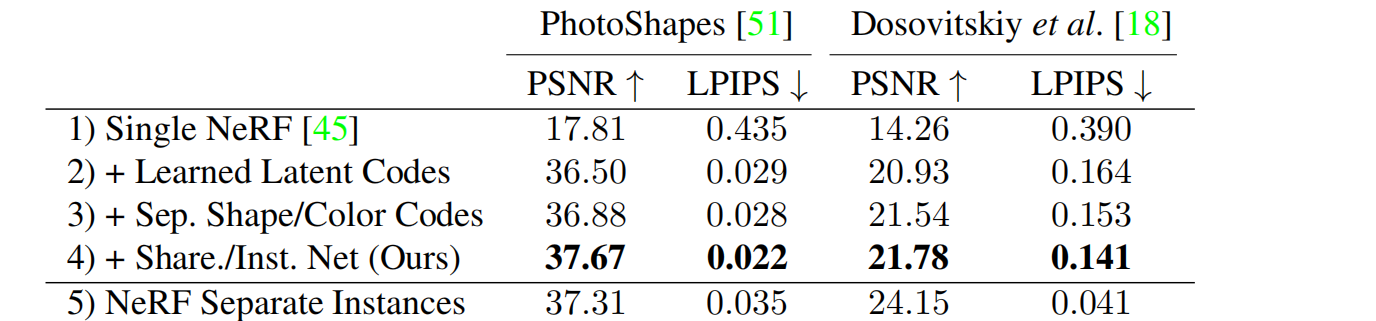
此外,我们发现我们的方法可以很好地适应更多的训练实例。当对所有626个实例进行训练时,我们的方法实现了重建PSNR 35.79。我们发现,共享的形状分支有助于我们的模型扩展到更多的实例。相比之下,没有共享形状分支训练的模型的PSNR值为33.91
3.2.颜色编辑
我们的方法既将编辑传播到实例的所需区域,又将其推广到实例的看不见的视图。我们在下图3中展示了几个颜色编辑的示例。为了评估优化参数,我们用消融研究量化编辑的质量。(© Editing a Single-Instance NeRF导致视觉假象,而(d)Rewriting a GAN 无法将编辑传播到看不见的视图,并生成不现实的输出)

我们发现,只微调颜色代码是无法适应所需的编辑。另一方面,改变整个网络会导致实例的形状发生很大的变化,因为微调网络的早期层会影响下游的密度输出。接下来,我们将与两种基线方法进行比较:Editing a Single-Instance NeRF 和 editing a GAN。
Single-instance NeRF baseline。我们训练一个NeRF来建模我们想要编辑的源实例,然后将我们的编辑方法应用到单个实例NeRF上。单个实例NeRF与我们的模型共享相同的架构。
GAN editing baselines.与基于2DGAN的Rewriting a GAN的编辑方法进行了比较。我们首先在PhotoShape 数据集上训练一个StyleGAN2模型。然后,我们使用StyleGAN2投影方法,将源实例的未经编辑的测试视图投影到潜在的向量和噪声向量中。接下来,我们将源视图和目标视图转换为它的潜在向量和噪声向量。利用这些图像/潜在对,我们遵循Bau等人的方法,优化网络,将目标视图的区域粘贴到源视图上。优化完成后,我们将测试集潜在向量和噪声向量输入编辑后的模型,以获得我们实例的编辑视图。
这些结果在上图3和下表2中可视化。Single-instance NeRF无法在模型中找到可推广到其他视图的变化,因为缺乏特定于类别的外观优先级。对模型进行微调可能会导致模型的其他视图中的工件,并可能导致不同视图之间的颜色不一致。此外,由于缺乏三维表示法,基于2dgan的编辑方法无法正确地修改对象的颜色或保持不同视图之间的形状一致性。
3.3 形状编辑
我们的方法能够学习编辑实例的形状,并将编辑传播到看不见的视图,如下图4。类似于我们对颜色编辑的分析,我们评估我们的权重选择来优化。对于一个Dosovitskiy chair 数据集训练实例,我们找到了一个看不见的具有相似形状的目标实例。然后,我们进行编辑,将源实例的形状更改为目标实例,并量化渲染的真实视图和地面真实视图之间的差异。表3总结了三次编辑的平均结果,图4的顶部可视化了一次编辑的结果。
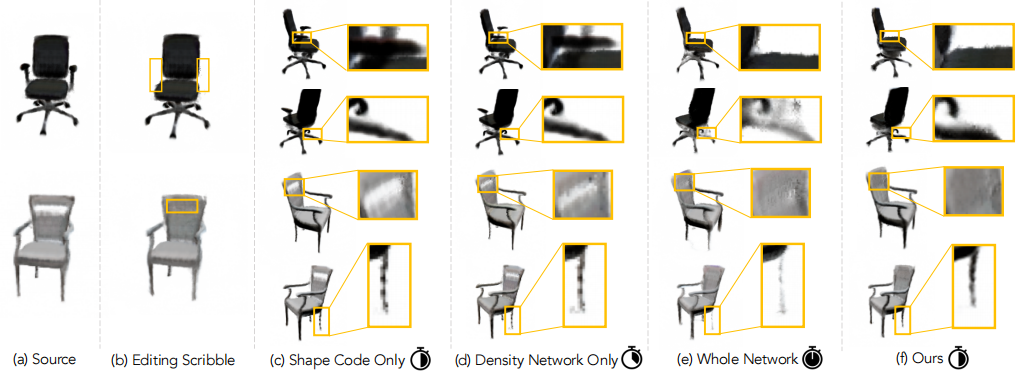
我们的方法成功地切除了手臂,填补了椅子的洞。请注意,只有优化形状代码或形状分支无法适应这两种编辑。优化整个网络是缓慢的,并且会在实例中发生不必要的更改。
我们发现,只优化形状代码和只优化Fdens的方法不能适合于需求,而是让椅子基本保持不变。优化整个网络会导致对象部分的删除,但会在对象的其余部分中导致不必要的工件。相反,我们的方法正确地删除了手臂,填充了椅子的洞,并将此编辑推广到每个实例的看不见视图。
3.4.形状/颜色码交换(Shape/Color Code Swapping)
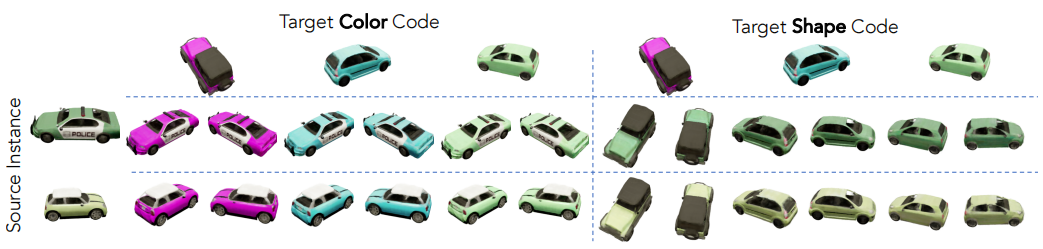
当我们将颜色代码输入条件辐射场,同时保持形状代码不变时,生成的渲染视图在形状上保持一致。我们的模型体系结构加强了这种一致性,因为控制实例形状的密度输出独立于颜色代码。当更改条件辐射场的形状代码输入,同时保持颜色代码不变时,渲染视图的颜色保持一致。这是令人惊讶的,因为在我们的架构中,一个点的亮度是形状代码和颜色代码的函数。相反,该模型已经学会了在预测辐射时将颜色与形状分离出来。这些属性可以让我们可以自由地交换形状和颜色代码,允许在不同实例之间传递形状和外观;我们在图5中可视化了这一点。
3.5.真实图像编辑
我们演示了在给定一个训练的条件辐射场的条件下,如何编辑和推断单个真实图像的新视图。我们假设单个图像具有与条件辐射场的训练数据相似的属性(例如,对象类、背景)。首先,我们通过手动选择具有相似对象姿态的训练集图像来估计图像的视点。在实践中,我们发现并不需要一个完美的位姿估计。利用假设的输入图像,我们通过优化相对于图像的标准NeRF光度损失来微调条件辐射场。在进行优化时,我们首先优化模型的形状和颜色代码,同时保持MLP权重固定,然后联合优化所有参数。这种优化比从一开始就联合优化所有参数的选择更稳定。给定精细的辐射场,我们继续使用编辑方法来编辑实例的形状和颜色。我们在图6中演示了我们编辑真实照片的结果。

真实的图像编辑结果。我们的方法首先确定一个条件辐射场来匹配一个真实的静止图像输入。编辑产生的辐射场成功地将座椅颜色变为红色,并去除椅子的两条腿。
这篇关于【三维编辑】Editing Conditional Radiance Fields 编辑条件NeRF(ICCV2021)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





