本文主要是介绍HuggingFace-RL-Unit2-Part2——初探Q-Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
初探Q-Learning
文章目录
- 初探Q-Learning
- 什么是Q-Learning?
- Q-Learning 算法
- 第一步: 初始化Q-表
- 第二步: 使用epsilon贪心策略选择一个动作
- 第三步: 执行动作At, 得到奖励Rt+1和下一个状态St+1
- 第四步: 更新Q(St, At)
- 异策略 vs 同策略
- Q-Learning算法实例
- 第一步: 初始化Q-table
- 第二步:使用spsilon贪心策略选择动作
- 第三步:执行动作At,得到奖励Rt+1和新的状态St+1
- 第四步:更新Q(St, At)
- 第二步:使用spsilon贪心策略选择动作
- 第三步:执行动作At,得到奖励Rt+1和新的状态St+1
- 第四步:更新Q(St, At)
- Q-Learning算法回顾
- 术语词汇表
- **Q-learning:**
- **Q-table:**
- 寻找最优策略的方法
- 在基于价值的方法中,我们可以找到两种主要的策略
- Epsilon-greedy 策略:
- 贪婪策略 —— Greedy strategy :
- **贝尔曼方程 —— The Bellman Equation :**
- **蒙特卡罗 —— Monte Carlo :**
- **时序差分学习 —— Temporal Difference Learning :**
- **Frozen-Lake-v1(non-slippery and slippery version) :**
- **自动驾驶出租车 —— An autonomous taxi:**
- 动手实践
- Unit 2: 在FrozenLake-v1 ⛄ 和 Taxi-v3 🚕中使用 Q-Learning
- 🎮 环境:
- 📚 RL库:
- 本单元的目标 🏆
- 前置知识🏗️
- Q-Learning的简要回顾
- 让我们开始编写第一个强化学习算法 🚀
- 安装依赖并创建虚拟显示 🔽
- 导入包 📦
- Part 1: Frozen Lake ⛄ (非滑动版本)
- 创建并理解 [FrozenLake 环境⛄](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/)
- 答案
- 让我们看看环境的样子:
- 创建并初始化 Q-table 🗄️
- 参考答案
- 定义贪婪策略 🤖
- 答案
- 定义 epsilon 贪婪策略 🤖
- 参考答案
- 定义超参数 ⚙️
- 创建训练函数
- 答案
- 训练 Q-Learning 智能体 🏃
- 查看Q-table中的值 👀
- 评估函数 📝
- 评估Q-Learning智能体 📈
- 将我们的训练模型发布到Hub 🔥
- 请勿修改这段代码
- Part2:Taxi-v3 环境🚖
- 创建并理解 [Taxi-v3 环境🚕](https://www.gymlibrary.dev/environments/toy_text/taxi/)
- 定义超参数 ⚙️
- 训练 Q-Learning 智能体 🏃
- 创建一个模型字典 💾 并将训练好的模型发布到Hub 🔥
- Part3:从Hub加载模型 🔽
- *请勿修改该部分代码*
- 额外挑战 🏆
- 继续学习,保持卓越 🤗
- 学习进展测验
- 问题一:什么是Q-Learning?
- 问题二:什么是Q-table?
- 问题三:为什么有了最优Q函数 Q * 就意味着有了最优的策略?
- 问题四:解释一下什么是Epsilon贪心策略?
- 问题五:怎么更新一个状态动作对的Q值?
- 问题六:在线学习和离线学习的区别是什么?
- 总结
- 不断学习,保持卓越 🤗
- 补充阅读
- 蒙特卡洛与时序差分学习
- Q-Learning
什么是Q-Learning?
Q-Learning是一种离线策略的基于价值的方法,它使用时序差分方法来训练其动作-价值函数:
- 离线策略:我们将在本单元的最后讨论这个问题。
- 基于价值的方法:通过训练一个价值函数或动作-价值函数来间接地找到最优策略,该函数能告诉我们每个状态或每个状态-动作对的价值。
- 使用时序差分方法:在每一步更新其动作-价值函数,而不是在回合结束时进行更新。
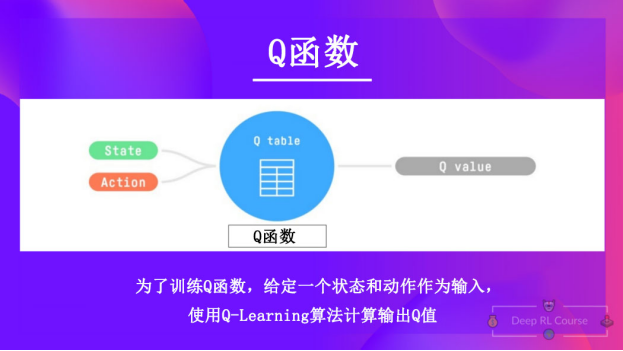
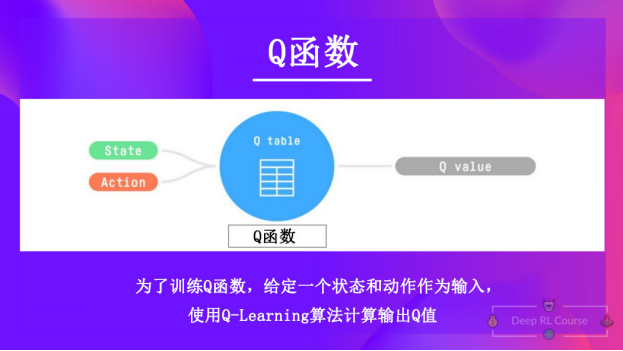
Q-Learning是我们用来训练 Q 函数的算法,Q 函数是一个动作-价值函数,用于确定在特定状态下采取特定动作的价值。
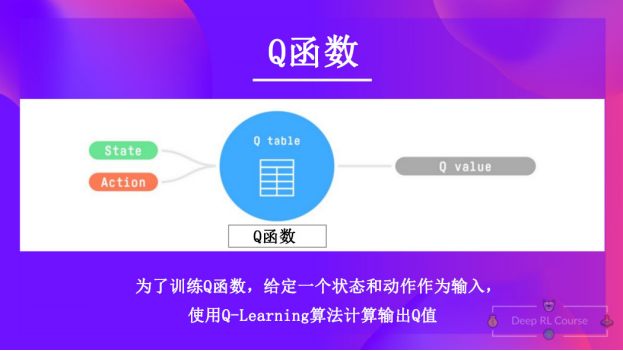
给定一个状态和动作,Q函数将输出对应的状态-动作值(也叫做Q值)
Q来源于“Quality”(价值),即该状态下的动作价值。
让我们回顾一下价值和奖励之间的区别:
- 状态的价值或状态-动作对的价值是智能体在此状态(或状态-动作对)开始行动并按照其策略行事时预期的累积奖励。
- 奖励是在状态下执行动作后从环境中获得的反馈。
在内部,Q函数有一个Q-表,这个表中的每个单元格对应一个状态-动作对的价值。可以将这个Q-表视为Q函数的记忆或速查表。
让我们通过一个迷宫的例子来解释以上内容。

我们对Q-表进行初始化,所以其中的值都为0. 这个表格包含了每个状态的四个状态-动作值。

在这里我们可以看到,初始状态向上的状态-动作值为0:

因此,Q函数包含一个Q-表,其中包含每个状态动作对的值。给定一个状态和动作,Q函数会在其Q-表中搜索并输出该值。
回顾一下,Q-Learning是一个包含以下过程的强化学习算法:
- 训练一个Q-函数(一个动作-价值函数),其内部是一个包含所有状态-动作对值的Q-表。
- 给定状态和动作,我们的Q-函数会在其Q-表中查找相应的值。
- 当训练完成后,我们有了一个最优的Q-函数,这意味着我们有了最优的Q-表。
- 如果我们拥有最优的Q-函数,我们拥有最优的策略,因为我们知道每个状态下应该采取的最佳动作。

但是,在开始时我们的Q-表是没有用的,因为它给每个状态-动作对赋予了任意的值(大多数情况下,我们把Q-表初始化为0)。随着智能体探索环境并更新Q-表,它会给我们更好的近似最优策略。

可以看到随着训练,Q 表格变得更好了,因为借助它,我们可以知道每个状态-动作对的值。
现在我们已经理解了什么是Q-Learning,Q-函数和Q-表,接下来让我们深入了解一下Q-Learning算法。
Q-Learning 算法
这是Q-Learning 的伪代码;让我们研究一下其中的每一部分,并在实现它之前**用一个简单的例子看看它是如何工作的。**不要被它的形式吓到,它比看起来简单!

第一步: 初始化Q-表

我们需要初始化Q-表中的每个状态-动作值。大多数情况下,我们用0来初始化。
第二步: 使用epsilon贪心策略选择一个动作
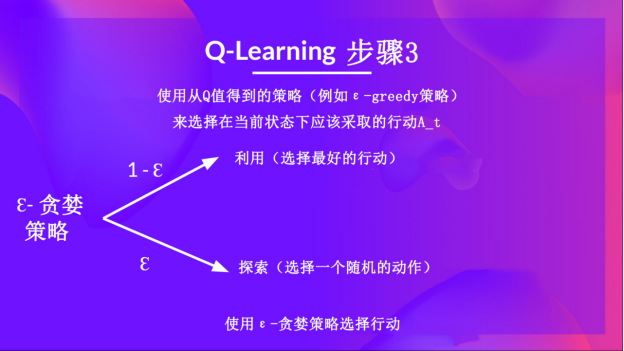
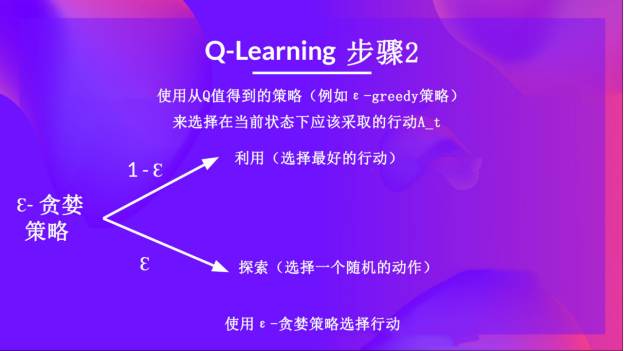
epsilon-贪婪策略是一种处理探索与利用权衡的策略。
其思想是首先定义初始 epsilon ɛ = 1.0:
- 概率 1 — ɛ:智能体进行利用(即智能体选择具有最高状态-动作对值的动作)。
- 概率 ɛ:智能体进行探索(尝试随机动作)。
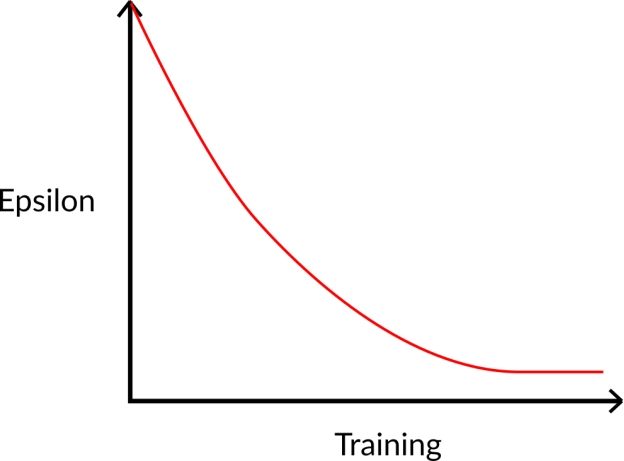
在训练开始时,由于 ɛ 值很高,进行探索的概率会很大,所以智能体大部分时间都在探索。但随着训练的进行,Q-表在估计中越来越准确,所以逐渐降低 epsilon 值,因为智能体逐渐不再需要探索,而需要更多地进行利用。
第三步: 执行动作At, 得到奖励Rt+1和下一个状态St+1

第四步: 更新Q(St, At)
需要注意的是,在时序差分学习中,我们在与环境交互之后更新策略或价值函数(取决于我们选择的强化学习方法)。
为了计算时序差分目标(TD target),我们使用立即奖励 (R_{t+1}) 加上下一个状态最佳状态-动作对的折扣价值(称之为自举)。
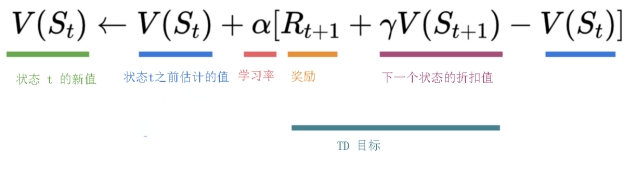
因此,(Q(S_t, A_t)) 更新公式如下:

这意味着要更新 (Q(S_t, A_t)):
- 需要 (S_t, A_t, R_{t+1}, S_{t+1})。
- 需要更新给定状态-动作对的Q值,使用TD target。
如何形成TD target?
- 在采取动作后获得奖励 (R_{t+1})。
- 为了获得最佳的下一个状态-动作对值,使用贪婪策略来选择下一个最佳动作。需要注意的是,这不是一个 ε-贪婪策略,其将始终采取具有最高状态-动作值的动作。
然后,在此Q值更新完成后,将开始一个新的状态,并再次使用 ε-贪婪策略选择动作。
这就是为什么我们说Q学习是一种离线策略算法。
异策略 vs 同策略
它们之间只有细微的区别:
- 异策略:在行动(推理)和更新(训练)部分中使用不同的策略。
例如,使用Q学习,ε-贪婪策略(行动策略),与**用于选择最佳下一状态动作值来更新Q值(更新策略)**的贪婪策略不同。

行动策略
与我们在训练部分中所使用的策略不同:
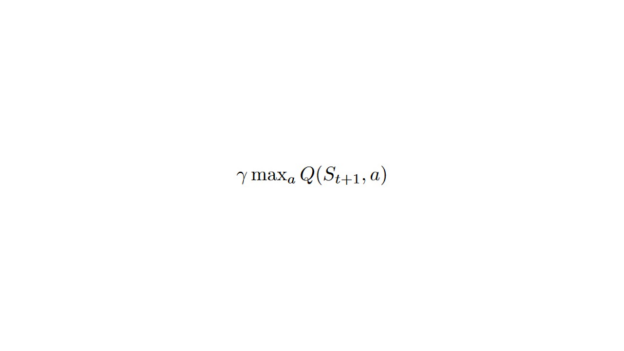
更新策略
- 同策略:在行动和更新部分中使用相同的策略。
例如,在另一种基于值的算法Sarsa中,执行ε-贪心策略时,它选择的不是最优动作,而是下一个状态和相应的动作组合。


Q-Learning算法实例
为了更好的理解Q-Learning算法,我们举一个简单的例子:

- 假如你是一个处在小迷宫中的小老鼠,并总是从相同的起点开始出发。
- 你的目标是吃掉右下角的大块奶酪,并且避免吃到毒药。毕竟相比于小块奶酪,谁会不喜欢大块奶酪呢?
- 在每次探索中,如果吃到毒药、吃掉大块奶酪或行动超过五个步骤,则该次探索结束。
- 学习率为0.1。
- Gamma(折扣率)为0.99。

奖励函数如下:
- +0: 去一个没有奶酪的状态。
- +1: 去一个有小奶酪的状态。
- +10: 去一个有一大堆奶酪的状态。
- -10: 去一个有毒药的状态,从而死亡。
- +0 如果我们花了超过五步。

我们将使用 Q-Learning 算法训练智能体,使其能够具有最优策略(即能够依次做出向右、向右、向下动作的策略)。
第一步: 初始化Q-table

目前,Q-table是没用的;所以我们需要使用 Q-Learning 算法来训练 Q 函数。
我们进行 2 个训练时间步长的训练:
训练时间步长 1:
第二步:使用spsilon贪心策略选择动作
因为epsilon很大,等于1.0,所以你随机选择了一个向右的行动。
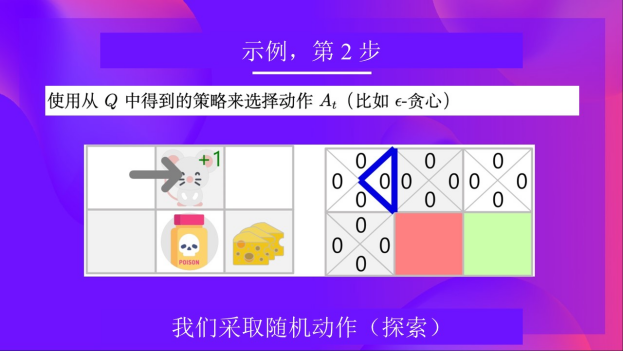
第三步:执行动作At,得到奖励Rt+1和新的状态St+1
向右走后,你得到了一块小奶酪,所以(R_{t+1} = 1),并且你进入了一个新的状态。

第四步:更新Q(St, At)
现在我们可以使用公式更新Q(St,At)。


第二次训练(不需要再对Q-table进行初始化):
第二步:使用spsilon贪心策略选择动作
由于epsilon还是很大,为0.99,所以你再次随机选择一个行动(随着训练的进行,我们希望越来越少探索,所以我们把epsilon逐渐减小)。
你选择了一个向下的动作。这是一个糟糕的行动,因为它让小老鼠吃到了毒药。
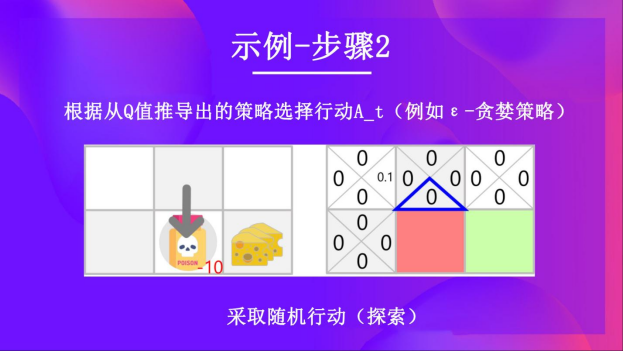
第三步:执行动作At,得到奖励Rt+1和新的状态St+1
因为不小心吃到了毒药,所以小老鼠不幸死亡,得到的奖励 Rt+1 = -10。

第四步:更新Q(St, At)
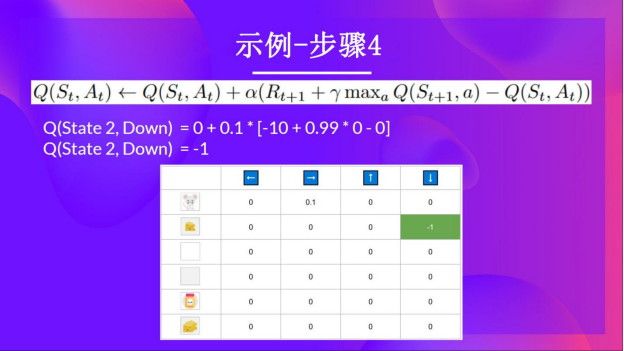
因为小老鼠牺牲了,所以我们开始了一个新的训练回合。但是我们可以看到,在两个探索步骤后,智能体变得更聪明了。
随着智能体继续探索和利用环境,并使用TD-target更新Q值,Q表中的近似值越来越好。因此,在训练结束时,我们将获得Q函数的最优估计。
Q-Learning算法回顾
Q-Learning算法是一种强化学习算法,具有以下主要特点:
- 它会训练一个Q函数,这是一种动作-价值函数,其内部有一个Q表,用于存储所有状态-动作对的值。
- 当给定一个状态和动作时,Q函数会在Q表中查找相应的值。
- 在训练完成后,我们会得到一个最优的Q函数,从而获得一个最优的Q表。
- 当我们拥有一个最优的Q函数时,我们就能得到一个最优策略,因为我们知道在每个状态下应该采取什么最佳动作。

然而,在一开始,我们的Q表是没用的,因为它为每个状态-动作对提供了任意的值(通常我们会将Q表初始化为全零值)。但随着我们不断地探索环境并更新Q表,它将为我们提供越来越好的近似值。

以下是 Q-learning 算法的伪代码:

术语词汇表
这是一个由社区创建的词汇表,欢迎投稿!
Q-learning:
- Q-learning是一种强化学习算法,它通过学习一个动作-价值函数(即Q函数),来确定在每个状态下应该采取哪个动作。在Q-learning中,智能体试图学习一个策略,使得总的奖励最大化。
Q-table:
- Q-table是一个表,它存储了强化学习智能体对每个状态-动作对的价值估计。表中的每一个条目就代表了在某一状态下采取某一动作的预期回报。
寻找最优策略的方法
- 基于策略的方法。 策略通常用神经网络来训练,以选择在给定状态下采取的动作。在这种情况下,是神经网络输出了智能体应该采取的动作,而不是使用价值函数。根据环境给出的经验,神经网络会重新调整,并提供更好的动作。
- 基于价值的方法。 在这种情况下,一个价值函数被训练来输出一个状态或一个状态-动作对的价值,这个价值将代表我们的策略。然而,这个价值并没有定义智能体应该采取什么动作。相反,我们需要指定智能体在给定价值函数的输出时的行为。例如,我们可以决定采用一个策略,其总是采取能够获得最大奖励的动作(贪婪策略)。总之,策略是一个贪婪策略(或者用户采取的任何决定),它使用价值函数的值来决定采取什么动作。
在基于价值的方法中,我们可以找到两种主要的策略
- 状态-价值函数。 对于每个状态,状态-价值函数是如果智能体从当前状态开始,遵循该策略直到结束时的期望回报。
- 动作-价值函数。 与状态-价值函数相比,动作-价值函数不仅考虑了状态,还考虑了在该状态下采取的动作,它计算了智能体在某个状态下执行某个动作后,根据策略所能获得的预期回报。之后智能体会一直遵循这个策略,以最大化回报。
Epsilon-greedy 策略:
- 常用的强化学习探索策略,涉及平衡探索和利用。
- 以 1-epsilon 的概率选择奖励最高的动作。
- 以 epsilon 的概率选择一个随机动作。
- Epsilon 通常随着时间减少,以偏向利用。
贪婪策略 —— Greedy strategy :
- 涉及总是选择预期会导致最高奖励的动作,基于当前对环境的了解。(只有利用)
- 总是选择期望奖励最高的动作。
- 不包括任何探索。
- 在有不确定性或未知最优动作的环境中可能是不利的。
贝尔曼方程 —— The Bellman Equation :
- 贝尔曼方程是描述状态值函数或动作值函数的递归关系。它表明一个状态(或状态-动作对)的值等于即时奖励加上下一状态(或下一状态-动作对)的折扣值的期望。
蒙特卡罗 —— Monte Carlo :
- 蒙特卡罗方法是一种通过平均完整经验样本的返回(即经验序列中的总奖励)来估计价值函数的方法。蒙特卡罗方法只在一个完整的序列结束之后才进行更新。
时序差分学习 —— Temporal Difference Learning :
- 时序差分学习结合了动态规划和蒙特卡罗方法的思想。在时序差分学习中,智能体不需要等待序列结束就可以更新其价值函数,只需要等待下一个时间步。
Frozen-Lake-v1(non-slippery and slippery version) :
- FrozenLake是一种常见的强化学习环境,通常用于测试强化学习算法。在这个环境中,智能体需要在一个冰冻的湖面上移动,目标是从起点移动到目标点。
- 在non-slippery版本中,智能体的每个动作都会精确地按照预期的方式执行。
- 在slippery版本中,冰面是滑的,所以智能体的动作可能会导致预期之外的结果。
自动驾驶出租车 —— An autonomous taxi:
- 在强化学习环境中,自动驾驶出租车是一个经典的问题。在这个问题中,出租车是一个智能体,需要学习如何在城市环境中导航,从一个地方(称为点A)运送乘客到另一个地方(称为点B)。
- 具体来说,智能体的目标是找到一种策略,能在最少的步骤内完成任务。
- 自动驾驶出租车的问题模型包括了一个格子世界,其中每个格子代表一个可能的位置。出租车的任务包括寻找乘客,接乘客,然后把乘客送到目的地。出租车需要在这个过程中尽可能减少行驶的步数,因为每走一步都会收到一个负奖励(代表出租车消耗的燃料或者时间成本)。如果成功地将乘客送到目的地,出租车则会得到一个正奖励。
如果你想改进这门课程,你可以提交一个 Pull Request.
本词汇表得以实现,感谢以下贡献者:
- Ramón Rueda
- Hasarindu Perera
动手实践
之前我们已经学习了Q-Learning算法,现在我们要从头实现它,并在两个环境中训练Q-Learning智能体:
- Frozen-Lake-v1(非滑动和滑动版本)☃️:智能体需要从起始状态(S)到达目标状态(G),只在冰冻的瓷砖(F)上行走,避免掉入洞穴(H)。
- 自动驾驶出租车🚖:智能体需要学会在城市中导航,以便将乘客从A点运输到B点。

在排行榜中你可以比较自己和其他同学的结果,并相互交流探讨最好的实现方法以提高智能体的分数。谁将赢得该挑战?拭目以待!
为了完成这个实践部分的认证过程,你需要将你训练过的出租车模型推送到Hub,并获得>= 4.5的成绩。
你可以在排行榜找到你的模型并查看模型评价值,评价值 = 平均回报 - 回报的标准差
有关认证过程的更多信息,请查看该部分👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
你可以在该处检查你的进度👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
如果要开始该实践,请单击“在Colab中打开”按钮👇:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sqBqfXtx-1687665847833)(null)]
我们强烈建议使用Google Colab进行动手练习,而不是在个人电脑上运行它们。
通过使用Google Colab,你可以专注于学习和实验,而不用担心设置环境的技术问题。
Unit 2: 在FrozenLake-v1 ⛄ 和 Taxi-v3 🚕中使用 Q-Learning
在这个note book中,你将从头编写你的第一个强化学习智能体,使用Q-Learning训练智能体在FrozenLake❄️中玩游戏,并将其分享给社区,可以尝试不同的配置进行训练。
⬇️ 下面是一个例子,你可以在几分钟内实现它。⬇️
🎮 环境:
- FrozenLake-v1
- Taxi-v3
📚 RL库:
- Python and NumPy
- Gym
如果你在该教程中发现了一些问题,请在GitHub Repo上提出。
本单元的目标 🏆
在单元结束时,你将:
- 能够使用Gym环境库。
- 能够从头编写一个Q-Learning智能体。
- 能够将你的训练过的智能体及其代码推送到Hub,并附上精美的视频回放和评估得分🔥。
前置知识🏗️
在深入了解note book之前,你需要:
🔲 📚 通过阅读Unit 2学习Q-Learning 🤗
Q-Learning的简要回顾
-
Q-Learning算法是一种强化学习算法,具有以下主要特点:
- 它会训练一个Q函数,这是一种动作-价值函数,其内部有一个Q表,用于存储所有状态-动作对的值。
- 当给定一个状态和动作时,Q函数会在Q表中查找相应的值。
-
在训练完成后,我们会得到一个最优的Q函数,从而获得一个最优的Q表。
-
当我们拥有一个最优的Q函数时,我们就能得到一个最优策略,因为我们知道在每个状态下应该采取什么最佳动作。

然而,在一开始,我们的Q表是没用的,因为它为每个状态-动作对提供了任意的值(通常我们会将Q表初始化为全零值)。但随着我们不断地探索环境并更新Q表,它将为我们提供越来越好的近似值。

以下是 Q-learning 算法的伪代码:

让我们开始编写第一个强化学习算法 🚀
安装依赖并创建虚拟显示 🔽
在笔记中,我们需要生成一个回放视频。所以在Colab中,我们需要一个虚拟屏幕来呈现环境(从而录制视频帧)。
因此,下面的单元格将安装库并创建并运行一个虚拟屏幕🖥
我们将安装多个库:
gym:包含FrozenLake-v1⛄和Taxi-v3🚕环境。我们使用gym==0.24,因为它包含一个漂亮的Taxi-v3 UI版本。pygame:用于FrozenLake-v1和Taxi-v3的UI。numpy:用于处理我们的Q-table。
Hugging Face Hub 🤗 作为一个中心平台,任何人都可以在此共享和探索模型和数据集。它具有版本控制、度量、可视化等功能,使你可以轻松与他人合作。
你可以在这里查看所有可用的深度强化学习模型(如果它们使用Q-Learning)👉 https://huggingface.co/models?other=q-learning
pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
sudo apt-get update
apt install python-opengl ffmpeg xvfb
pip3 install pyvirtualdisplay
为了确保能够使用新安装的库,有时我们需要重新启动笔记本的运行时环境。下一个单元格将强制运行时环境崩溃,这样你就需要重新连接并从这里开始运行代码。多亏了这个技巧,我们才能运行我们的虚拟屏幕。
import osos.kill(os.getpid(), 9)
# Virtual display
from pyvirtualdisplay import Displayvirtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
导入包 📦
除了安装的库之外,我们还使用:
random:生成随机数(对于epsilon-贪婪策略非常有用)。imageio:生成回放视频。
import numpy as np
import gym
import random
import imageio
import osimport pickle5 as pickle
from tqdm.notebook import tqdm
接下来我们正式进入Q-Learning算法的代码部分 🔥
Part 1: Frozen Lake ⛄ (非滑动版本)
创建并理解 FrozenLake 环境⛄
💡 开始使用环境时,查看其文档是个好习惯
👉 https://www.gymlibrary.dev/environments/toy_text/frozen_lake/
我们将使用Q-Learning算法来训练智能体,使其仅在冰冻砖块(F)上行走,并避开洞穴(H),从起始状态(S)导航至目标状态(G)。
我们有两种规格的环境:
map_name="4x4":一个4x4的网格版本map_name="8x8":一个8x8的网格版本
环境有两种模式:
is_slippery=False:由于冰冻湖面的非滑动性质,智能体总是沿着预期的方向移动(确定性)。is_slippery=True:由于冰冻湖面的滑动性质,智能体可能不会总是沿着预期的方向移动(随机性)。
现在我们先用4x4的地图和非滑动版本来简化问题。
# 使用正确的参数创建FrozenLake-v1环境,使用4x4地图和非滑动版本
env = gym.make() # TODO 使用正确的参数
答案
env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False)
你可以像这样创建自己的自定义网格:
desc=["SFFF", "FHFH", "FFFH", "HFFG"]
gym.make('FrozenLake-v1', desc=desc, is_slippery=True)
但我们现在将使用默认的环境。
让我们看看环境的样子:
# 我们用gym.make("<name_of_the_environment>")创建环境- is_slippery=False:由于冰冻湖面的非滑动性质,智能体总是沿着预期的方向移动(确定性)
print("_____OBSERVATION SPACE_____ \n")
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # 获得一个随机观测值
我们通过Observation Space Shape Discrete(16)可以看到,观测值是一个整数,表示智能体当前位置为current_row * nrows + current_col(其中行和列都从0开始)。
例如,4x4地图中的目标位置可以按以下方式计算:3 * 4 + 3 = 15。可能的观测值数量取决于地图的大小。例如,4x4地图有16个可能的观测值。
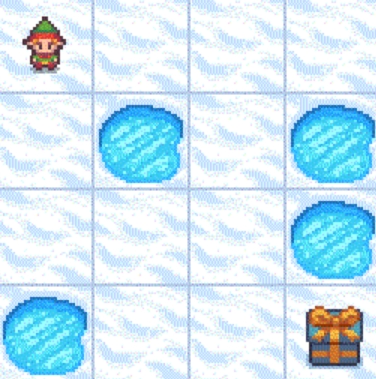
例如,这是 state = 0 的样子:
print("\n _____ACTION SPACE_____ \n")
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample()) # 采取一个随机动作
动作空间(智能体可采取的动作集合)是离散的,有4个可用动作🎮:
- 0:向左走
- 1:向下走
- 2:向右走
- 3:向上走
奖励函数💰:
- 到达目标:+1
- 到达洞穴:0
- 到达冰冻:0
创建并初始化 Q-table 🗄️
(👀 以下是Q-Learning算法的伪代码)

现在是初始化我们的Q表的时候了!
为了知道要使用多少行(状态)和列(动作),我们需要了解动作和观测空间。虽然我们之前已经知道了动作和观测空间的数值,但是为了算法能够适用于不同的环境,我们在程序中以变量的形式对它们进行存储。
state_space =
print("There are ", state_space, " possible states")action_space =
print("There are ", action_space, " possible actions")
# 创建一个大小为(state_space,action_space)的 Q-table,并使用 np.zeros 将每个值初始化为 0
def initialize_q_table(state_space, action_space):Qtable =return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)
参考答案
state_space = env.observation_space.n
print("There are ", state_space, " possible states")action_space = env.action_space.n
print("There are ", action_space, " possible actions")
# 创建一个大小为(state_space,action_space)的 Q-table,并使用 np.zeros 将每个值初始化为 0
def initialize_q_table(state_space, action_space):Qtable = np.zeros((state_space, action_space))return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)
定义贪婪策略 🤖
需要注意的是我们有两个策略,因为 Q-Learning 是一种离线策略算法,所以我们使用不同的策略来更新行动和价值函数。
- Epsilon 贪婪策略(行动策略)
- 贪婪策略(更新策略)
贪婪策略也将是使用 Q-Learning 算法训练智能体后的最终策略,贪婪策略用于从 Q-table 中选择动作。

def greedy_policy(Qtable, state):# 利用:选择具有最高状态-动作价值的动作action =return action
答案
def greedy_policy(Qtable, state):# 利用:选择具有最高状态-动作价值的动作action = np.argmax(Qtable[state][:])return action
定义 epsilon 贪婪策略 🤖
Epsilon 贪婪策略是处理探索和利用之间的权衡问题的一种训练策略。
Epsilon 贪婪策略的思想是:
- 概率 1 — ɛ:智能体进行利用(即智能体选择具有最高状态-动作对值的动作)。
- 概率 ɛ:智能体进行探索(尝试随机动作)。
随着训练的进行,我们逐渐降低 epsilon 值,因为智能体逐渐不再需要探索,而更多的需要利用。
def epsilon_greedy_policy(Qtable, state, epsilon):# 在 0 和 1 之间随机生成一个数字random_num =# 如果 random_num > epsilon --> 利用if random_num > epsilon:# 采取给定状态下最高值的动作# 这里可以用 np.argmaxaction =# 否则 --> 探索else:action = # 采取一个随机动作return action
参考答案
def epsilon_greedy_policy(Qtable, state, epsilon):# 在 0 和 1 之间随机生成一个数字random_int = random.uniform(0, 1)# 如果 random_int > epsilon --> 利用if random_int > epsilon:# 采取给定状态下最高值的动作# 这里可以用 np.argmaxaction = greedy_policy(Qtable, state)# 否则 --> 探索else:action = env.action_space.sample()return action
定义超参数 ⚙️
与智能体的探索行动相关的超参数非常重要:
- 我们需要确保智能体能够充分地探索状态空间以学习到一个较好的值近似。为了达到这个目标,我们需要逐渐减小epsilon。
- 但是如果将epsilon减小得太快(衰减率过高),就会增加智能体陷入困境的风险,因为它没有充分探索状态空间,所以无法解决问题。
# 训练参数
n_training_episodes = 10000 # 训练回合数
learning_rate = 0.7 # 学习率# 评估参数
n_eval_episodes = 100 # 测试回合数# 环境参数
env_id = "FrozenLake-v1" # 环境名称
max_steps = 99 # 每次尝试的最大步数
gamma = 0.95 # 折扣率
eval_seed = [] # 环境的评估种子# 探索参数
max_epsilon = 1.0 # 起始探索概率
min_epsilon = 0.05 # 最小探索概率
decay_rate = 0.0005 # 探索概率的指数衰减速率
创建训练函数

训练的过程以如下方式进行:
在所有训练次数的每个循环中:减少 epsilon(因为智能体逐渐不再需要探索)
重置环境对于每个最大尝试步数:使用 epsilon 贪婪策略选择动作 At执行动作(a)并观察结果状态(s')和奖励(r)使用贝尔曼方程更新 Q 值 Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]如果完成,结束本回合下一个状态是新状态
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):for episode in range(n_training_episodes):# 减小 epsilon(因为智能体逐渐不再需要探索)epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)# 重置环境state = env.reset()step = 0done = False# 重复for step in range(max_steps):# 使用 epsilon 贪婪策略选择动作 Ataction =# 采取动作 At 并观察 Rt+1 和 St+1# 采取动作(a)并观察结果状态(s')和奖励(r)new_state, reward, done, info =# 更新 Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]Qtable[state][action] =# 如果完成,结束本次尝试if done:break# 下一个状态是新状态state = new_statereturn Qtable
答案
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):for episode in tqdm(range(n_training_episodes)):# 减小 epsilon(因为智能体逐渐不再需要探索)epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)# 重置环境state = env.reset()step = 0done = False# 重复for step in range(max_steps):# 使用 epsilon 贪婪策略选择动作 Ataction = epsilon_greedy_policy(Qtable, state, epsilon)# 采取动作 At 并观察 Rt+1 和 St+1# 采取动作(a)并观察结果状态(s')和奖励(r)new_state, reward, done, info = env.step(action)# 更新 Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])# 如果完成,结束本次尝试if done:break# 下一个状态是新状态state = new_statereturn Qtable
训练 Q-Learning 智能体 🏃
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
查看Q-table中的值 👀
Qtable_frozenlake
评估函数 📝
- 定义我们要用来测试 Q-Learning 智能体的评估函数
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):"""对智能体进行 n_eval_episodes 轮评估,返回平均奖励和奖励的标准差。:param env: 评估环境:param n_eval_episodes: 评估智能体的轮数:param Q: Q-table:param seed: 评估种子数组(用于taxi-v3)"""episode_rewards = []for episode in tqdm(range(n_eval_episodes)):if seed:state = env.reset(seed=seed[episode])else:state = env.reset()step = 0done = Falsetotal_rewards_ep = 0for step in range(max_steps):# 在给定状态下选择具有最大预期未来奖励的动作(索引)action = greedy_policy(Q, state)new_state, reward, done, info = env.step(action)total_rewards_ep += rewardif done:breakstate = new_stateepisode_rewards.append(total_rewards_ep)mean_reward = np.mean(episode_rewards)std_reward = np.std(episode_rewards)return mean_reward, std_reward
评估Q-Learning智能体 📈
-
通常应该得到平均奖励为1.0
-
因为状态空间非常小(16),所以该环境相对简单,你可以尝试用有滑动版本替换它,这会引入随机性,使环境更加复杂。
# 评估智能体
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")
将我们的训练模型发布到Hub 🔥
如果在训练后看到了好的结果,我们可以用一行代码将训练模型发布到Hugging Face Hub🤗。
这里有一个模型概述卡的例子:
在底层,Hub使用基于git的存储库(如果你不知道git是什么,不用担心),这意味着你可以在实验和改进你的智能体时,用新版本更新模型。
请勿修改这段代码
from huggingface_hub import HfApi, snapshot_download
from huggingface_hub.repocard import metadata_eval_result, metadata_savefrom pathlib import Path
import datetime
import json
def record_video(env, Qtable, out_directory, fps=1):"""生成智能体表现的回放视频:param env:param Qtable: 我们智能体的Q表:param out_directory:param fps: 每秒帧数(对于taxi-v3和frozenlake-v1,我们使用1)"""images = []done = Falsestate = env.reset(seed=random.randint(0, 500))img = env.render(mode="rgb_array")images.append(img)while not done:# 在给定状态下选择具有最大预期未来奖励的动作(索引)action = np.argmax(Qtable[state][:])state, reward, done, info = env.step(action) # 直接将next_state = state用于记录逻辑img = env.render(mode="rgb_array")images.append(img)imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):"""评估、生成视频并将模型上传到Hugging Face Hub。该方法完成整个流程:- 它评估模型- 它生成模型概述卡- 它生成智能体的回放视频- 它将所有内容推送到Hub:param repo_id: Hugging Face Hub中的模型存储库ID:param env:param video_fps: 以多少帧每秒录制我们的视频回放(对于taxi-v3和frozenlake-v1,我们使用1):param local_repo_path: 本地存储库的位置"""_, repo_name = repo_id.split("/")eval_env = envapi = HfApi()# 第一步:创建仓库repo_url = api.create_repo(repo_id=repo_id,exist_ok=True,)# 第二步:下载文件repo_local_path = Path(snapshot_download(repo_id=repo_id))#第三步:保存模型if env.spec.kwargs.get("map_name"):model["map_name"] = env.spec.kwargs.get("map_name")if env.spec.kwargs.get("is_slippery", "") == False:model["slippery"] = False# 将模型存储为Pickle文件with open((repo_local_path) / "q-learning.pkl", "wb") as f:pickle.dump(model, f)# 第四步:评估模型并构建包含评估指标的JSON文件mean_reward, std_reward = evaluate_agent(eval_env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])evaluate_data = {"env_id": model["env_id"],"mean_reward": mean_reward,"n_eval_episodes": model["n_eval_episodes"],"eval_datetime": datetime.datetime.now().isoformat(),}# 编写一个名为 "results.json" 的JSON文件,其中将包含评估结果with open(repo_local_path / "results.json", "w") as outfile:json.dump(evaluate_data, outfile)# 第五步:创建模型概述概述卡env_name = model["env_id"]if env.spec.kwargs.get("map_name"):env_name += "-" + env.spec.kwargs.get("map_name")if env.spec.kwargs.get("is_slippery", "") == False:env_name += "-" + "no_slippery"metadata = {}metadata["tags"] = [env_name, "q-learning", "reinforcement-learning", "custom-implementation"]# 添加指标eval = metadata_eval_result(model_pretty_name=repo_name,task_pretty_name="reinforcement-learning",task_id="reinforcement-learning",metrics_pretty_name="mean_reward",metrics_id="mean_reward",metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",dataset_pretty_name=env_name,dataset_id=env_name,)# 合并两个字典metadata = {**metadata, **eval}model_card = f"这是一个受过训练的Q-Learning智能体玩 {env_id} 的模型。"## 用法model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")# 不要忘记检查是否需要添加额外的属性 (is_slippery=False等)env = gym.make(model["env_id"])evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])readme_path = repo_local_path / "README.md"readme = ""print(readme_path.exists())if readme_path.exists():with readme_path.open("r", encoding="utf8") as f:readme = f.read()else:readme = model_cardwith readme_path.open("w", encoding="utf-8") as f:f.write(readme)# 将指标保存到Readme元数据metadata_save(readme_path, metadata)# 第六步:录制视频video_path = repo_local_path / "replay.mp4"record_video(env, model["qtable"], video_path, video_fps)# 第七步. 将所有内容推送到Hubapi.upload_folder(repo_id=repo_id,folder_path=repo_local_path,path_in_repo=".",)print("Your model is pushed to the Hub. You can view your model here: ", repo_url)
通过使用 push_to_hub,你可以评估、录制回放、生成智能体的模型卡片并将其推送到Hub。
这样:
- 可以展示你的作品 ���
- 可以查看智能体的游戏过程 ���
- 可以与社区分享其他人可以使用的智能体 ���
- 可以访问排行榜���,查看你的智能体与同学相比表现如何 ��� https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
要与社区共享你的模型,还需遵循以下三个步骤:
1️⃣(如果还没有完成)创建HF帐户 ➡ https://huggingface.co/join
2️⃣ 登录后,你需要从Hugging Face网站存储你的认证令牌。
创建一个新令牌(https://huggingface.co/settings/tokens)具有写权限

from huggingface_hub import notebook_loginnotebook_login()
如果你不想使用Google Colab或Jupyter Notebook,可以使用此命令代替:huggingface-cli login(或login)
3️⃣ 现在我们准备使用push_to_hub()函数将训练好的智能体推送到🤗Hub🔥
- 首先创建包含超参数和Q_table的模型字典。
model = {"env_id": env_id,"max_steps": max_steps,"n_training_episodes": n_training_episodes,"n_eval_episodes": n_eval_episodes,"eval_seed": eval_seed,"learning_rate": learning_rate,"gamma": gamma,"max_epsilon": max_epsilon,"min_epsilon": min_epsilon,"decay_rate": decay_rate,"qtable": Qtable_frozenlake,
}
填写push_to_hub函数:
-
repo_id:将创建/更新的Hugging Face Hub存储库的名称(repo_id = {username}/{repo_name})💡 一个好的
repo_id是{username}/q-{env_id} -
model:模型字典,包含超参数和Qtable -
env:环境 -
commit_message:提交信息
model
username = "" # 填写你的用户名
repo_name = "q-FrozenLake-v1-4x4-noSlippery"
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
恭喜🥳你刚刚从零开始实现、训练并上传了你的第一个强化学习智能体。
FrozenLake-v1 无滑动版 是一个非常简单的环境,让我们尝试一个更难的环境🔥。
Part2:Taxi-v3 环境🚖
创建并理解 Taxi-v3 环境🚕
💡 开始使用环境时,查看其文档是个好习惯
👉 https://www.gymlibrary.dev/environments/toy_text/taxi/
在Taxi-v3🚕中,网格环境中有四个指定位置,分别为R(ed)、G(reen)、Y(ellow)和B(lue)。
当回合开始时,出租车随机出现在一个方格中,乘客位于一个随机位置。出租车驶向乘客所在位置,接载乘客,驶向乘客的目的地(另外四个指定位置中的一个),然后放下乘客。一旦乘客被放下,回合结束。

env = gym.make("Taxi-v3")
There are 500 discrete states since there are 25 taxi positions, 5 possible locations of the passenger (including the case when the passenger is in the taxi), and 4 destination locations.
该环境有500个离散状态,因为有25个出租车位置,5个可能的乘客位置(包括乘客在出租车内的情况),以及4个目的地位置。
**
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")
动作空间(智能体可以采取的可能动作集合)是离散的,有6个可用动作🎮:
- 0:向南移动
- 1:向北移动
- 2:向东移动
- 3:向西移动
- 4:接载乘客
- 5:放下乘客
奖励函数💰:
- 每步-1,除非触发其他奖励。
- 送达乘客+20。
- 非法执行“接载”和“放下”动作-10。
# 创建具有state_size行和action_size列(500x6)的Q表
Qtable_taxi = initialize_q_table(state_space, action_space)
print(Qtable_taxi)
print("Q-table shape: ", Qtable_taxi.shape)
定义超参数 ⚙️
⚠ 请勿修改EVAL_SEED:eval_seed数组允许我们使用相同的出租车起始位置评估每个同学的智能体
# 训练超参数
n_training_episodes = 25000 # 训练回合数
learning_rate = 0.7 # 学习率# 评估参数
n_eval_episodes = 100 # 评估回合数# 请勿修改EVAL_SEED
eval_seed = [16,54,165,177,191,191,120,80,149,178,48,38,6,125,174,73,50,172,100,148,146,6,25,40,68,148,49,167,9,97,164,176,61,7,54,55,161,131,184,51,170,12,120,113,95,126,51,98,36,135,54,82,45,95,89,59,95,124,9,113,58,85,51,134,121,169,105,21,30,11,50,65,12,43,82,145,152,97,106,55,31,85,38,112,102,168,123,97,21,83,158,26,80,63,5,81,32,11,28,148,
] # 评估种子,这确保了所有同学的智能体都在相同的出租车起始位置上进行训练
# 每个种子都有一个特定的起始状态# 环境参数
env_id = "Taxi-v3" # 环境名称
max_steps = 99 # 每个回合的最大步数
gamma = 0.95 # 折扣率# 探索参数
max_epsilon = 1.0 # 起始探索概率
min_epsilon = 0.05 # 最小探索概率
decay_rate = 0.005 # 探索概率的指数衰减率
训练 Q-Learning 智能体 🏃
Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)
Qtable_taxi
创建一个模型字典 💾 并将训练好的模型发布到Hub 🔥
- 我们创建一个模型字典,其中将包含所有可复现的训练超参数和Q-Table。
model = {"env_id": env_id,"max_steps": max_steps,"n_training_episodes": n_training_episodes,"n_eval_episodes": n_eval_episodes,"eval_seed": eval_seed,"learning_rate": learning_rate,"gamma": gamma,"max_epsilon": max_epsilon,"min_epsilon": min_epsilon,"decay_rate": decay_rate,"qtable": Qtable_taxi,
}
username = "" # 填写你的用户名
repo_name = ""
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
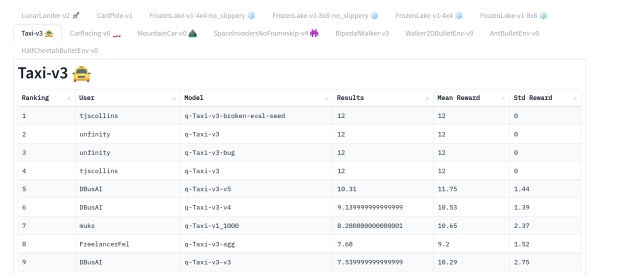
现在已经发布到Hub上,你可以查看排行榜 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard 与同学们比较Taxi-v3的结果。
⚠ 若要查看你的排名,你需要在排行榜页面底部点击刷新 ⚠
Part3:从Hub加载模型 🔽
通过Hugging Face Hub 🤗你可以轻松地加载社区的强大模型。
从Hub加载保存的模型非常简单:
- 前往 https://huggingface.co/models?other=q-learning 查看所有q-learning已保存模型的列表。
- 选择一个并复制其repo_id

- 然后我们只需使用
load_from_hub,参数为:
-
repo_id
-
filename:存储在repo中的已保存模型文件名。 从Hugging Face Hub下载模型。
:param repo_id: 来自Hugging Face Hub的模型存储库的ID
:param filename: 存储库中的模型zip文件的名称
请勿修改该部分代码
from urllib.error import HTTPErrorfrom huggingface_hub import hf_hub_downloaddef load_from_hub(repo_id: str, filename: str) -> str:"""从Hugging Face Hub下载模型:param repo_id: 来自Hugging Face Hub的模型存储库的ID:param filename: 存储库中的模型zip文件的名称"""# 从Hub中获取模型,下载并将模型缓存到本地磁盘中pickle_model = hf_hub_download(repo_id=repo_id, filename=filename)with open(pickle_model, "rb") as f:downloaded_model_file = pickle.load(f)return downloaded_model_file
model = load_from_hub(repo_id="ThomasSimonini/q-Taxi-v3", filename="q-learning.pkl") # 尝试使用另一个模型print(model)
env = gym.make(model["env_id"])evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
model = load_from_hub(repo_id="ThomasSimonini/q-FrozenLake-v1-no-slippery", filename="q-learning.pkl"
) # 尝试使用另一个模型env = gym.make(model["env_id"], is_slippery=False)evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
额外挑战 🏆
最好的学习方法就是自己去尝试!目前的智能体表现并不理想,你可以尝试让它训练更多步。我们发现,在1,000,000步的训练中,智能体能取得很好的成果!
在排行榜上,你可以看到你的智能体排名,你能登上榜首吗?
以下是一些建议:
- 训练更多步骤
- 观察其他同学的模型,尝试不同的超参数
- 在Hub上发布你新训练的模型 🔥
如果觉得在冰面上行走和驾驶出租车太无聊了,可以尝试更换环境,如使用FrozenLake-v1滑动版,通过查阅gym文档了解它们是如何使用的,并享受其带来的效果吧🎉。
恭喜🥳,你刚刚实现、训练并上传了你的第一个强化学习智能体。
理解Q-Learning对于领会基于价值的方法非常重要。
在接下来的单元中,我们将学习深度Q学习。我们会发现,创建和更新Q表的确是个好策略,但这种方法并不具备扩展性。
例如,假设你创建了一个能玩《毁灭战士》的智能体。

毁灭战士是一个庞大的环境,拥有大量的状态空间(数百万个不同状态)。为这样的环境创建和更新Q表并不高效。
正因如此,我们将在下一单元学习深度Q学习。这是一种算法,它利用神经网络在给定状态时近似计算每个动作的不同Q值。

期待在第三单元与你相见!🔥
继续学习,保持卓越 🤗
学习进展测验
想要获得最佳的学习效果并避免产生自以为是的幻觉,对自己进行测试是非常重要的。这会帮助你找到需要加强知识的领域。
问题一:什么是Q-Learning?
| 文本 | 说明 | 是否正确 |
|---|---|---|
| 一个用来训练Q函数的算法 | ✓ | |
| 一个价值函数 | 一个动作价值函数,因为它决定了在特定状态下采取特定动作的价值 | |
| 一个用于确定在特定状态下采取特定动作的价值的算法 | ✓ | |
| 一个表格 | Q函数不是Q-table,它是一个用于填充Q-table的算法 |
问题二:什么是Q-table?
| 文本 | 说明 | 是否正确 |
|---|---|---|
| Q-table是一个在Q-Learning中使用的算法 | ||
| Q-table是智能体的内部记忆 | ✓ | |
| Q-table中每一个单元都对应一个状态价值 | 每一个单元都对应一个状态价值对的价值,而非一个状态价值 |
问题三:为什么有了最优Q函数 Q * 就意味着有了最优的策略?
答案 因为有了最优的Q函数, 我们就知道了在每个状态下应该采取的最优动作,所以这意味着我们有了最优的策略。
问题四:解释一下什么是Epsilon贪心策略?
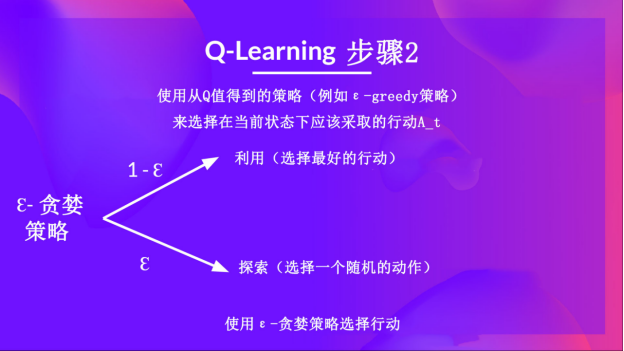
答案 Epsilon贪心策略是一种处理探索和利用平衡问题的方法。该方法思想为我们定义epsilon ε = 1.0:
-
当概率为1 — ɛ时:让智能体进行利用(即智能体选择一个具有最高状态动作对价值的动作)
-
当概率为ɛ时:让智能体进行探索(尝试随机动作)
问题五:怎么更新一个状态动作对的Q值?
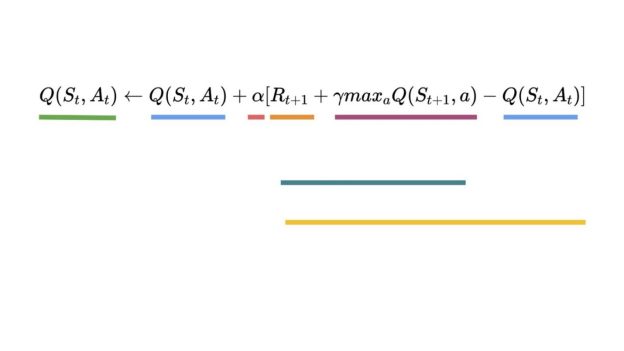

问题六:在线学习和离线学习的区别是什么?
答案
恭喜完成了以上的测验🥳,如果你对以上的内容还没有完全掌握,可以进行回顾以加强你的知识掌握程度(😏) 。
总结
恭喜你完成了本章!这里包含了大量的信息,同时恭喜你完成了整个教程,你刚刚从零开始实现了你的第一个强化学习智能体,并在 Hub 上分享了它🥳。
当学习一种新的架构知识时,从零开始实现对理解其工作原理非常重要。
如果你对之前的某些部分仍然感到不解,这很正常,因为对于所有学习强化学习的人都是这样。
在继续学习之前,请确保你真的掌握了之前所学的知识。
在下一章中,我们将深入研究基于 Q-学习的第一个深度强化学习算法:深度 Q-学习。你将使用 RL-Baselines3 Zoo 训练一个 DQN 智能体来玩Atari游戏。
不断学习,保持卓越 🤗
补充阅读
如果你想更深入地学习,这些是可供选择的阅读材料。
蒙特卡洛与时序差分学习
深入了解蒙特卡洛和时序差分学习的资料:
- 《为什么时序差分法(TD)的方差比蒙特卡罗(MC)方法低?》
- 《何时更倾向于使用蒙特卡罗方法而非时序差分法?》
Q-Learning
- 《强化学习导论,Richard Sutton和Andrew G. Barto 第5、6、7章》
- 《深度强化学习基础系列,Pieter Abbeel的L2深度Q学习》
这篇关于HuggingFace-RL-Unit2-Part2——初探Q-Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









