本文主要是介绍走近AbstractQueuedSynchronizer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、从类结构开始
Java并发包中的同步器是很多并发组件的基础,如各种Lock,ConcurrentHashMap中的Segment,阻塞队列,CountDownLatch等。按我们一贯的风格,让我们直接走近设计者对其的诠释。
在java.util.concurrent.locks包中, AbstractQueuedSynchronizer直接继承自AbstractOwnableSynchronizer。
AbstractOwnableSynchronizer
AbstractOwnableSynchronizer是一种可由一个线程独占的同步器,同时也是创建锁的基础,它还包含了一种叫所有权的概念。AbstractOwnableSynchronizer本身不管理内部数据,但是它的子类可以用来维护一些值并用于控制或监视线程的访问。
AbstractOwnableSynchronizer内部只有一个属性:独占当前同步状态的线程和该属性的set/get方法。
代码如下:
public abstract classAbstractOwnableSynchronizer {
privatetransient Thread exclusiveOwnerThread;
}
AbstractQueuedSynchronizer
AbstractQueuedSynchronizer提供了一种框架,用于实现阻塞锁和其他基于先入先出(FIFO)等待队列的同步组件。该类用一个Int类型的原子变量来表示一种状态。子类必须实现该类的protect方法,以此来改变同步状态。在获取或释放该状态时,需要定义这个状态值。类中的其他方法实现了线程入队与阻塞功能,子类依然可以维护其他状态字段,但是只能使用getState、setState、compareAndSetState方法来跟踪同步状态。
子类应该定义为非公共的内部工具类,并需要在封装的类中实现相应的同步属性。AbstractQueuedSynchronizer本身没有实现任何接口,支持独占式与共享式的获取同步状态。如果是独占模式,那么其他线程则不能获取到,而共享式则允许多个线程同时获取。两种不同模式下的等待线程共享同一个队列,通常实现的子类只支持一种模式,但是也有两种都支持的,如ReadWriteLock。仅支持独占或共享的子类可以不用实现对应模式所定义的方法。
AbstractQueuedSynchronizer类中定义了一个嵌套类ConditionObject。ConditionObject主要提供一种条件,由子类决定是否支持独占模式,并由isHeldExclusively方法决定当前线程是否是独占的获取同步状态。
除此,类中还定义了一些方法,用于检查、监控内部队列与条件对象。
二、队列节点
正式走近AbstractQueuedSynchronizer。
在AbstractQueuedSynchronizer内部,有一个静态的Node内部类,Doug对他解释如下:
等待队列节点
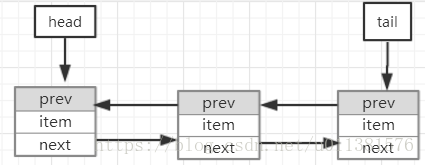
等待队列是一种“CLH(自旋锁)”锁队列。我们用自旋锁来实现阻塞同步器,但用的是同样的策略来控制一个线程的前驱节点的信息。每个节点中的status字段记录了一个线程是否已阻塞。当一个节点的前驱节点释放锁后会以信号的形式通知该节点,队列的每个结点作为一个特定通知风格(specific-notification-style)的监视器服务,会持有一个单独的等待线程,但是status字段不会控制是否线程能被赋予锁。如果一个线程是第一个进入队列的节点,他就可以尝试获取锁,但是也不能保证获取成功,只是有了竞争的权利。所以当前释放锁的竞争者线程可能需要再次等待。
为了进入CLH锁队列,你只需要原子的拼接成一个尾节点。要出队列的话,你仅需要设置head字段即可。
+------+ prev +-----+ +-----+
head | | <---- | |<---- | | tail
+------+ +-----+ +-----+
插入节点到CLH队列要求在tail节点上是原子性的操作,未到队列的节点与入队的节点之间的界定就是是否有一个简单的原子指向操作执行该节点。类似的,节点出队牵涉到操作的就是更新head节点。然而,对于节点来说却需要花很多功夫来决定他们的后继结点是什么,处理一部分因超时或中断而导致的取消。
prev链向符主要是用于处理取消,如果一个节点被取消后,他的后继节点可以重新链向一个有效的前驱节点。(想要了解自旋锁的更多说明可参考Scott and Scherer的论文:http://www.cs.rochester.edu/u/scott/synchronization/)
我们还使用了next链向符,用于实现阻塞的原理。每个节点里保留了一个线程的Id,因此一个前驱节点可以通过遍历next节点来找到具体的线程然后唤醒next节点。决定后继节点时需要避免与新入队的节点竞争去设置他们前驱节点的next字段。
取消节点采用一些保守的算法。由于我们必需要根据某节点来轮询取消,因此可能会错过在之前或之后的节点。在执行取消时,会唤醒他的后继节点,并允许他们稳定在一个新的前驱节点上。
CLH队列需要一个虚拟的head节点来开始,但不会在构造方法中创建他,因为如果没有竞争那么会很浪费。相反,在创建节点时遇到第一次竞争时才会设置head和tail节点。
等待线程使用的也是同样的节点,只不过用的是额外的链向符。条件是用来链接队列的,线程在等待时,就会新增一个节点到条件队列中,再被得到通知时,该节点就转入到主队列中。节点用一个特殊的状态值来表示在哪个队列中。三、节点状态
类上的注释说完了,开始说说类本身吧。从Node开始。
static final class Node { //静态内部Final类
//标记符,表示在共享模式下的等待节点
static final Node SHARED = new Node();//标记符,表示在独占模式下的等待节点
static final Node EXCLUSIVE = null;//等待状态值,表示一个线程已经被取消了
static final int CANCELLED = 1;//等待状态值,表示一个后继节点的线程需要唤醒
static final int SIGNAL = -1;//等待状态值,表示线程等待在某种条件下
static final int CONDITION = -2;//等待状态值,表示下一次共享式获取状态的操作应该无条件的传播
static final int PROPAGATE = -3;
/***
状态字段,取值如下:
SIGNAL: 当前结点的后继节点将会是阻塞的(通过park方法),因此当前结点需要唤醒他的后继节点,当他释放或取消后。为了避免竞争,获取同步状态的方法必须抢先表示自己需要信号,然后重新原子的获取。最后可能是获取失败,或者再次被阻塞。
CANCELLED: 由于超时、中断等原因,当前结点会被取消。取消后,节点不会释放状态。特殊情景下,被取消的节点中的线程将不会再被阻塞
CONDITION: 当前结点在一个条件队列中,再被转移之前将不会被作为同步节点。被转移时该值会被设置为0。
PROPAGATE: 共享式方式释放同步状态后应该被传播到其他节点。这种设置(仅对head节点)在do这篇关于走近AbstractQueuedSynchronizer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!