本文主要是介绍走近大数据之Hive入门(三、Hive的安装),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、Hive的安装模式
二、Hive安装之嵌入模式
三、Hive安装之远程模式和本地模式
一、Hive的安装模式
下载地址:
http://archive.apache.org/dist/
找到Hive,选择要安装的版本


Hive是基于Hadoop之上的一个数据仓库工具,所以按照Hive之前需先安装Hadoop环境
Hadoop安装:(进行中。。。)

安装模式
1 嵌入模式
- 本地durby :元数据信息被存储在Hive自带的Derby数据库中
- 只允许创建一个链接:同一时间只能一个人操作
- 多用于Demo:演示环境
2 本地模式
- 元数据信息被存储在MySQL数据库中
- MySQL数据库与Hive运行在同一台物理机器上
- 多用于开发和测试环境
3 远程模式
- 元数据信息被存储在MySQL数据库中
- MySQL数据库与Hive运行在不同的物理机器上
- 多用于生产环境
二、Hive安装之嵌入模式
1、将下载的安装包上传到Linux操作系 统上
2、在Linux系统中运行以下命令查看

3、解压
tar -zxvf apach-hive-0.13.0-bin.tar.gz
4、运行hive创建自带的derby数据库

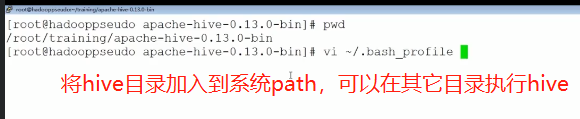
5、建hive添加系统path:可以在任意目录执行hive,在当前目录创建derby数据库


三、Hive安装之远程模式和本地模式

1、将mysql驱动上传到hive目录的lib目录下
2、修改配置文件:创建一个hive-site.xml文件
vi hive-site.xml

3、运行hive:Linux命令hive;查看mysql数据库会多创建很多表
本地模式只需将ip改成localhost即可
这篇关于走近大数据之Hive入门(三、Hive的安装)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








