本文主要是介绍走近大数据之Hive入门(二、Hive的体系结构),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、Hive的体系结构之元数据
二、Hive的体系结构之HQL的执行过程
三、Hive的体系结构
一、Hive的体系结构之元数据
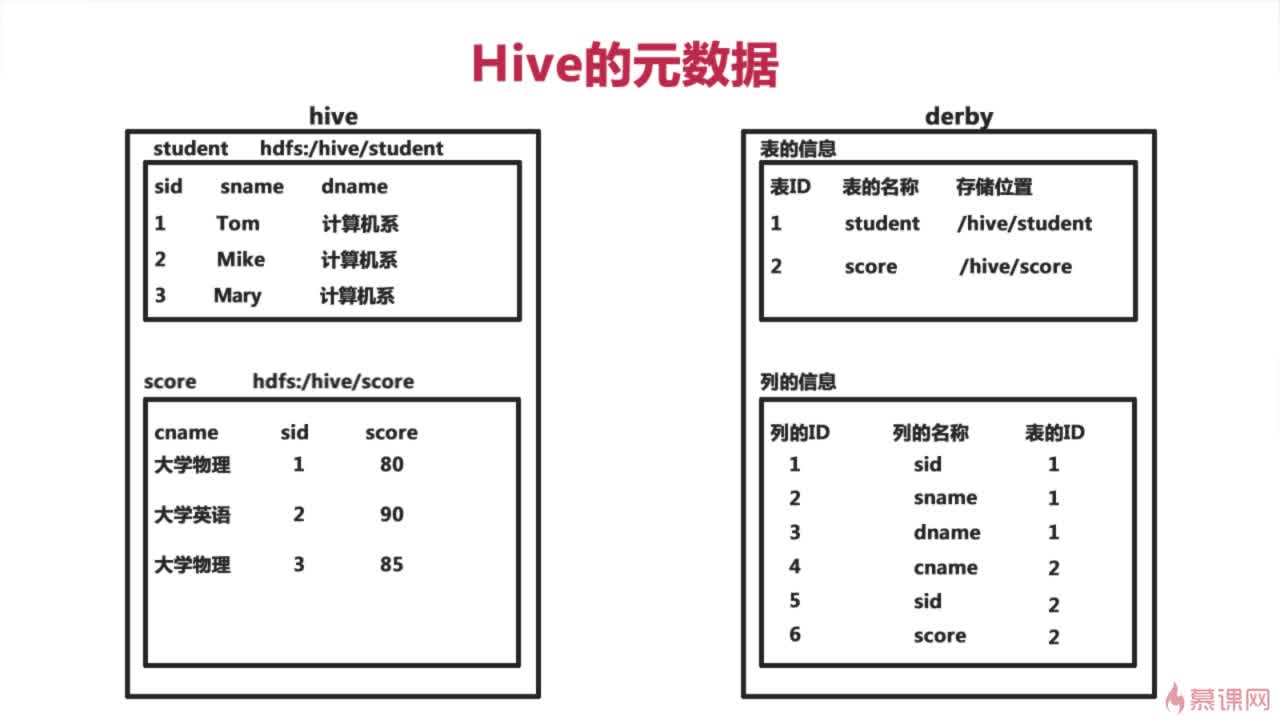
Hive将元数据存储在(metastore),支持mysql,derby等数据库 (默认存放在derby数据库中)
Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表),表的数据所在目录。
二、Hive的体系结构之HQL的执行过程
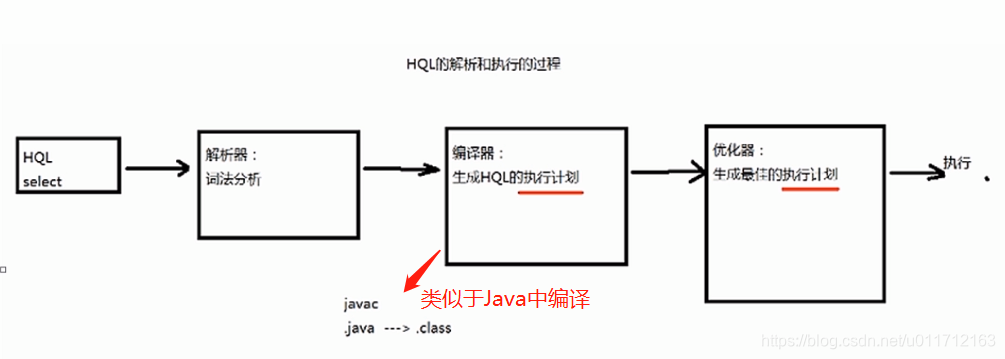
HQL 执行过程
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划(Plan)的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
执行计划(这里是查询计划!)
explain plan for select * from emp where deptno10
查询执行计划(oracle中) select * from table(dbms_xplan.display) ==> dbms_xplan.display 固定写法!
全表扫描
全表扫描的效率会很低
基于员工表的部门号,创建索引
create index myindex on emp(deptno) 在查询的列上创建索引,效率会高些(全表扫描与索引扫描的区别)
然后再重新生成执行计划: explain plan for select * from emp where deptno10
再重新查看执行计划: select * from table(dbms_xplan.display)
三、Hive的体系结构


这篇关于走近大数据之Hive入门(二、Hive的体系结构)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



