本文主要是介绍如何充分高效训练多轮对话大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一文看懂:如何充分高效训练多轮对话大模型
吃果冻不吐果冻皮 2023-08-08 13:08 发表于浙江
以下文章来源于YeungNLP ,作者荷风微摆

YeungNLP.
Firefly开源中文大语言模型官方公众号。
【点击】加入大模型技术交流群
01
前言
最近,有很多小伙伴在提问和讨论如何训练大模型的多轮对话能力。本文将会详细介绍Firefly项目是如何充分高效利用多轮对话数据训练大模型。注意,我们重点圈出了【充分】和【高效】两个关键词,这是Firefly项目训练多轮对话的特点,该方法可能和大部分同学理解的多轮对话训练方法存在差异。
02
模型效果
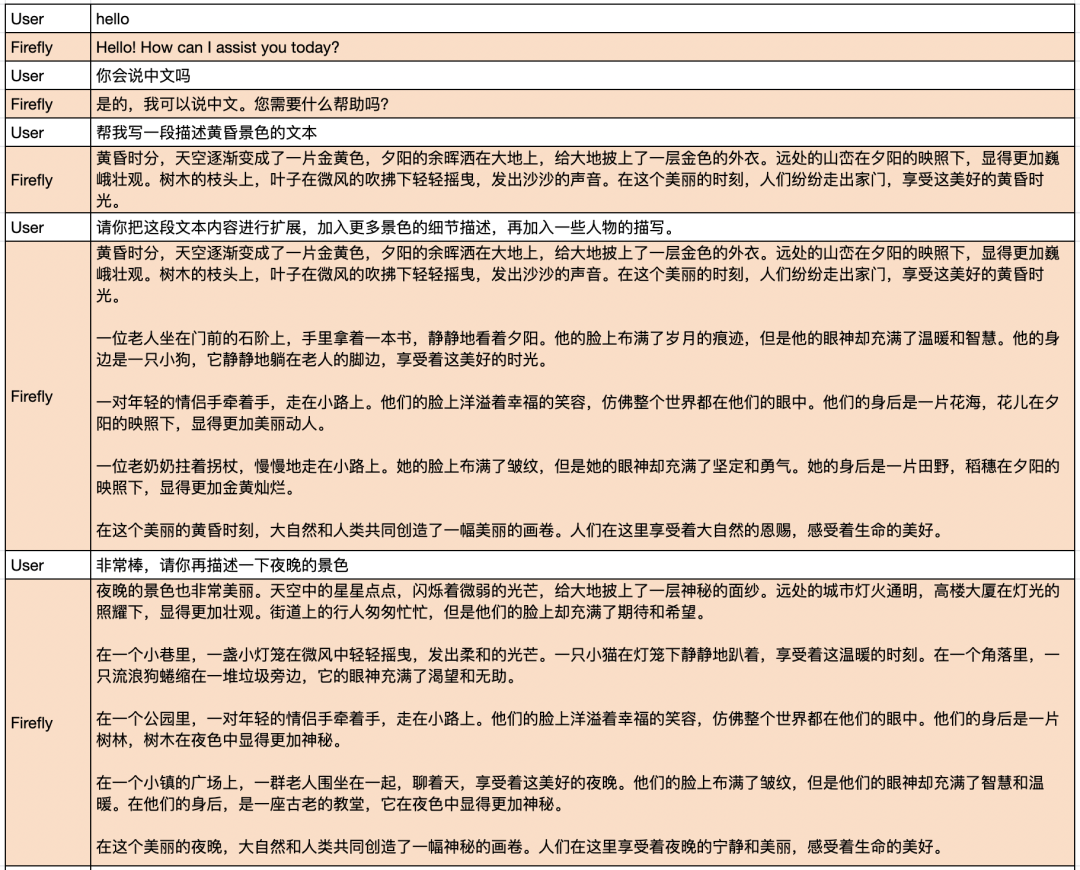
在介绍多轮对话训练方法之前,我们先展示一下Firefly训练的firefly-ziya-13b模型的多轮对话效果。以下回复均为模型生成,未经过人为修改。
多轮对话示例1:


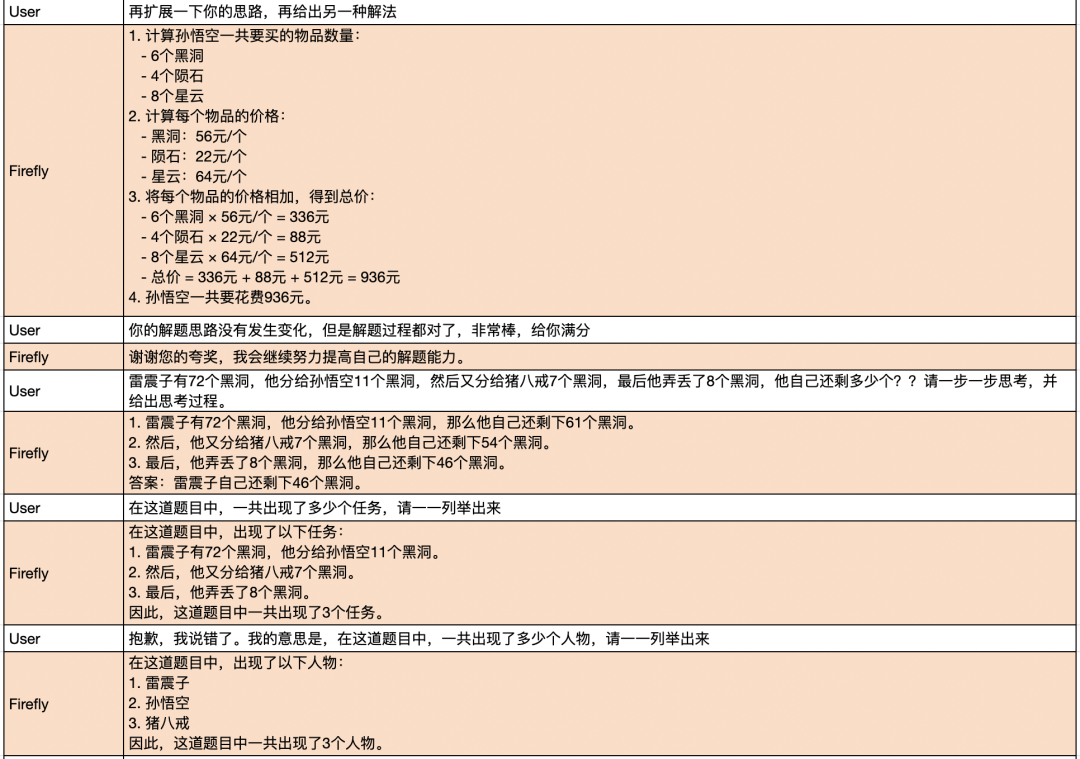
多轮对话示例2:


03
现有方法
假设我们现在有一条多轮对话数据,内容如下。为了方便讲解,对于第n轮对话,我们将用户和助手对应的输入设为Usern和Assistantn。
User1:你好Assistant1:你好,有什么能帮你吗?User2:今天天气怎么样Assistant2:北京今天天气晴,气温25度,紫外线较强,注意防护。User3:谢谢你Assistant3:不客气
这里提一个前置知识,以方便我们后续的讲解。在指令微调阶段,一般只有Assistant回答部分的loss会用于梯度回传,更新权重;而User部分的loss则不会用于更新权重。
如何使用上述这条多轮对话数据训练大模型?经过讨论和调研,我们发现目前主要有以下两种方法,但都不够充分高效。
方法一
User1、Assistant1、User2、Assistant2、User3的文本都视为模型的输入部分,将Assistant3的文本视为模型的预测部分,只有Assistant3部分的loss参与权重更新。
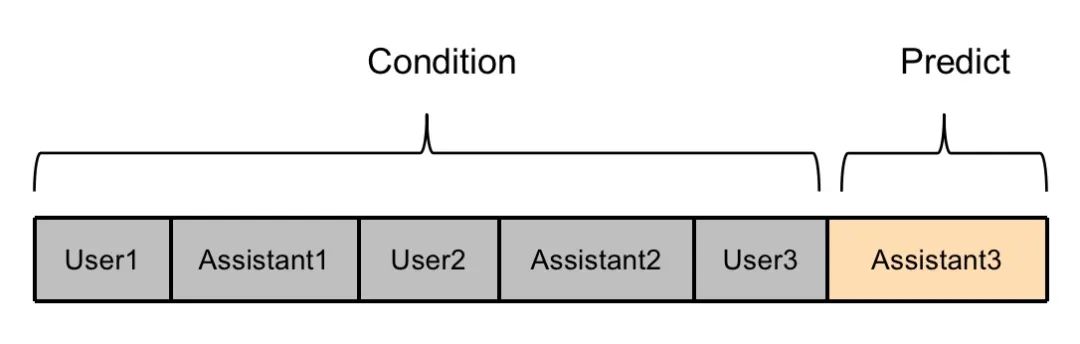
这种方法的弊端在于,没有充分利用多轮对话的训练数据,Assistant1和Assistant2的内容没有参与模型训练,这部分数据在训练时被浪费了。并且对于很多多轮对话数据而言,中间的Assitant回复部分的信息量更丰富详细,最后一个Assitant回复部分往往是”谢谢“、”不客气“等诸如此类的较为简短的文本。如果只使用这部分文本训练模型,会严重影响模型的训练效果。
方法二
将一条多轮对话数据,拆分成多条数据。例如将以上示例拆分成如下三条数据。
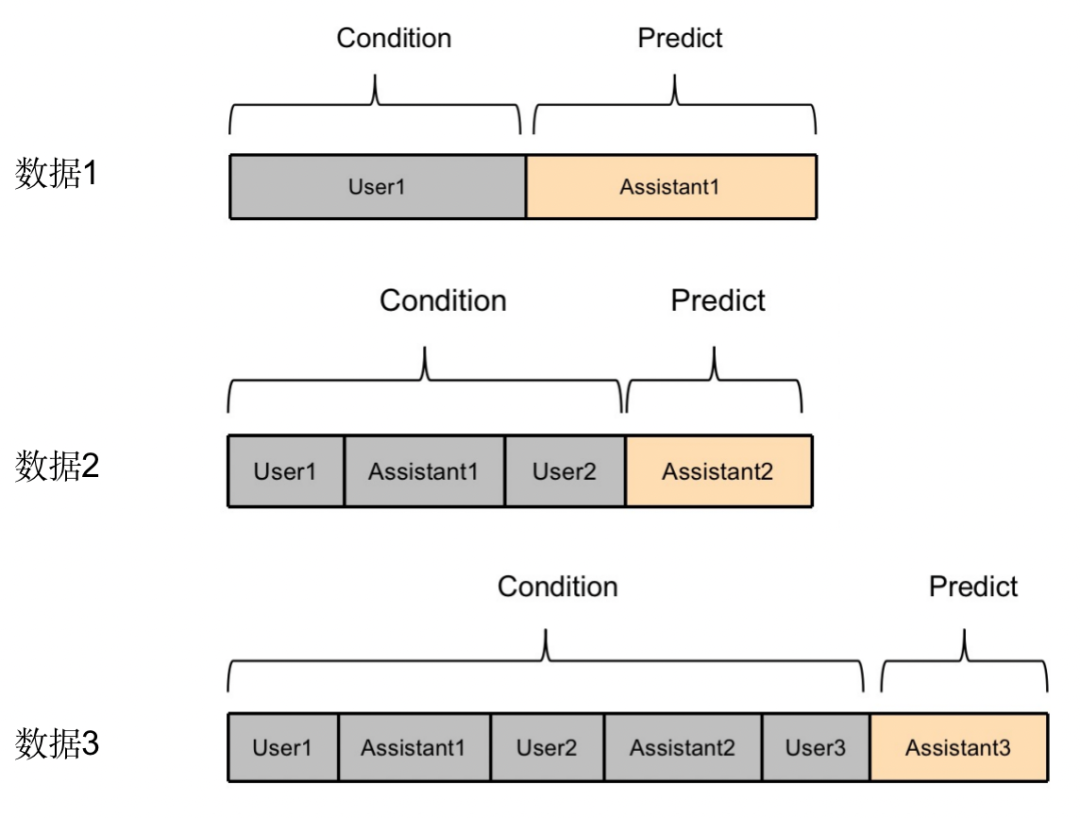
相比方法一,方法二能够更加充分利用多轮对话中每一个Assistant的回复内容。但是弊端在于,需要将一个包含n轮对话的数据,拆分成n条数据,训练效率降低了n倍,训练方法不高效。
04
Firefly方法
方法介绍
Firefly项目训练多轮对话模型时,采取了一种更加充分高效的方法。如下图所示,我们将一条多轮对话数据拼接之后,输入模型,并行计算每个位置的loss,只有Assistant部分的loss参与权重更新。
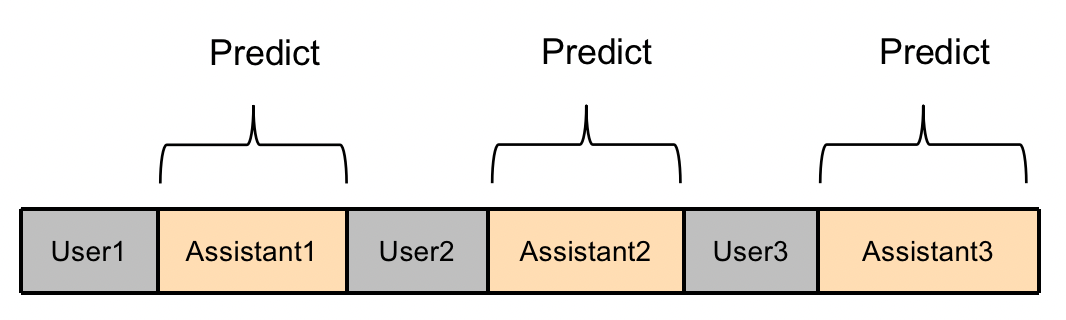
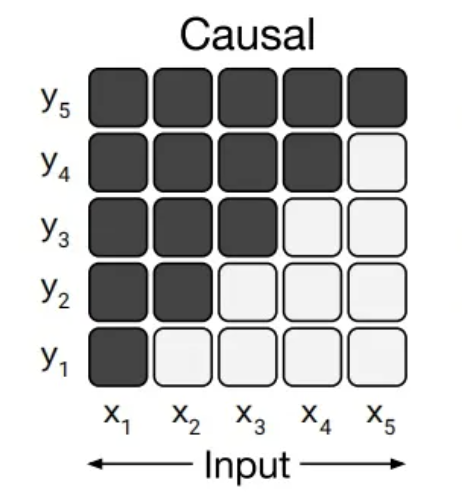
为什么这种做法是可行的?答案在于因果语言模型的attention mask。以GPT为代表的Causal Language Model(因果语言模型),这种模型的attention mask是一个对角掩码矩阵,每个token在编码的时候,只能看到它之前的token,看不到它之后的token。
所以User1部分的编码输出,只能感知到User1的内容,无法感知到它之后的文本,可以用来预测Assistant1的内容。而User2部分的编码输出,只能看到User1、Assistant1、User2的内容,可以用来预测Assistant2的内容,依此类推。对于整个序列,只需要输入模型一次,便可并行获得每个位置的logits,从而用来计算loss。
值得注意的是,GLM和UniLM不属于严格意义上的Causal Language Model(因果语言模型),因为它们存在prefix attention mask的设计。对于prefix而言,它的attention是双向的,而预测部分的attention是单向的。

代码实现
Talk is cheap,Show me the code。接下来将从代码层面介绍我们是如何充分高效地实现多轮对话训练。
训练时,Firefly将多轮对话拼接成如下格式,然后进行tokenize。
<s>input1</s>target1</s>input2</s>target2</s>...如果你更喜欢Alpaca或者Vicuna的数据组织风格,也可以将多轮对话组织成如下格式。个人经验之谈,尽管是Firefly上述简单的数据组织形式,多轮对话的效果也很惊艳,所以我们倾向于不需要加入太多的前缀说明,一家之言,仅供参考。
Below is a conversation between a user and an assistant.User: input1Assistant: target1</s>User: input2Assistant: target2</s>...
一个需要注意的点,训练的时候,需要在每个Assistant的回复后面都添加</s>,作为此轮对话生成结束的标识符。否则推理的时候,模型很难采样到</s>,从而无法结束生成。
在生成input_ids的时候,我们还会生成一个target_mask,取值为0或1,用来标记每个token是否属于target部分,即是否需要模型进行预测。其中“target</s>”部分的target_mask均为1,其他部分均为0。

我们会并行计算每个位置的loss,但只有target_mask=1的部分位置的loss,才会参与权重更新。这种方式充分利用了模型并行计算的优势,更加高效,并且多轮对话中的每个target部分都参与了训练,更加充分利用了数据。
loss计算的实现方式可参考以下代码:
class TargetLMLoss(Loss):def __init__(self, ignore_index):super().__init__()self.ignore_index = ignore_indexself.loss_fn = nn.CrossEntropyLoss(ignore_index=ignore_index)def __call__(self, model, inputs, training_args, return_outputs=False):input_ids = inputs['input_ids']attention_mask = inputs['attention_mask']target_mask = inputs['target_mask']# 模型前馈预测outputs = model(input_ids=input_ids, attention_mask=attention_mask, return_dict=True)logits = outputs["logits"] if isinstance(outputs, dict) else outputs[0]# 将labels中不属于target的部分,设为ignore_index,只计算target部分的losslabels = torch.where(target_mask == 1, input_ids, self.ignore_index)shift_logits = logits[..., :-1, :].contiguous()shift_labels = labels[..., 1:].contiguous()# Flatten the tokensloss = self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))return (loss, outputs) if return_outputs else loss
05
结语
在本文中,我们详细介绍了Firefly项目训练多轮对话模型的技巧和实现,实现了一种更加充分高效的多轮对话训练方法,希望能够帮助大家更好地理解。
这篇关于如何充分高效训练多轮对话大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






