本文主要是介绍数据结构与算法分析(十四)--- 字符串和字符处理函数库(C11),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、字符编码与字符类型
- 1.1 数据类型
- 1.2 字符类型
- 二、常见的字符操作
- 2.1 字符类型识别与大小写转换
- 2.2 字符格式与数值格式转换
- 2.3 字符串常用操作
- 2.3.1 字符串与字符数组的比较操作
- 2.3.2 字符串与字符数组的插入操作
- 2.3.3 字符串与字符数组的修改操作
- 2.3.4 字符串与字符数组的查找操作
- 2.3.5 字符串的分割操作
- 更多文章:
计算机诞生之初主要是为了帮助科学家和工程师完成繁琐的数学计算和方程求解,伴随着Web 互联网的普及,计算机处理字符的任务越来越多,在互联网或通信系统中传输的也都是各种字符信息。目前,计算机的两大核心任务就是数值计算和字符处理,分别对应数学语言和自然语言,各种计算机编程语言也分别为数值计算和字符处理提供了丰富的库函数。
一、字符编码与字符类型
1.1 数据类型
计算机寄存器、内存、闪存等存储介质都是以高低电平信号存储数据信息的,高低电平状态分别对应二进制的0 和1,因此计算机存储和处理数据都是以二进制形式进行的。
我们更习惯使用十进制数据进行计算和记录,要表示一个十进制数据需要多个二进制位组合起来,且不同大小的十进制数据需要不同位数的二进制来表示。计算机需要清楚的知道一个数据是由几个二进制位表示的、怎么解释该数据?编程语言为此提供了不同的数据类型,比如使用char、short int、int、long long int 关键字告诉计算机该数据分别需要8、16、32、64位二进制数据来表示整数,下面给出C 语言常用的数据类型(其中bool 类型是C99 新增的,若要使用需包含头文件<stdbool.h>):

带小数的浮点数为了使用尽可能少的二进制位表示,采用科学计数法的形式编码,比如float、double、long double 分别使用32、64、128 位二进制来表示浮点数(浮点数表示方法可参考博文:IEEE754 浮点数的表示方法)。既然表示浮点数的小数位数有限,自然不能精确表示所有小数,所以两个浮点数不能直接比较大小,我们常假设两个浮点数差的绝对值小于某个精度值EPSINON,这个精度值怎么取呢?主要看表示浮点数的小数位数,比如float 小数部分fraction 能表示的最小数为2-23 = 1.1921 * 10-7(虽然加上指数部分exponent 能表示更小的数,但其小数部分的分辨率大于2-23,并不能精确表示),如果我们自己编写比较浮点数的函数,常将EPSINON 设置为1.0 * 10-6(大于2-23 即可,C语言可在头文件float.h 中查看宏FLT_EPSILON 获得)。
相同类型的数据在不同操作系统上可能会由不同位数的二进制来表示,比如long int 在windows_x64 上使用32 位二进制表示,在linux_x64 上使用64 位二进制表示,为了避免跨平台移植遇到问题,可以使用定宽整数类型(见头文件<stdint.h>),比如int8_t、int16_t、int32_t、int64_t 等。
不同位数的二进制能表示的数据范围肯定不一样,比如对于N 位二进制可表示的整数范围是[-2(N-1),2(N-1)-1],如果是使用unsigned 修饰的无符号整数,则其可表示的整数范围是[0, 2N-1]。每种数据类型可表示的数据极限值也可以在头文件<limits.h>和<float.h> 中通过查询宏常量获知,比如最小和最大的int 类型数据值分别为INT_MIN 和INT_MAX。
值得一提的是,在进行数值计算时,如果计算结果超出该类型可表示范围极限,可能会出现程序错误或计算错误,这一点需要尽量在程序中避免。在进行数据类型转换时,可能会丢失部分数据,是否可接受其对计算结果的影响,需要程序开发者自己判断。
1.2 字符类型
前面介绍的数据类型中有一个char 类型,从字面意思看属于字符类型,也可以表示整数,字符类型跟整数类型有什么区别呢?计算机怎么知道char 表示的是字符还是整数呢?
计算机本身是不识别字符的,要想让计算机可以识别并处理各种字符信息,也需要像二进制表示十进制整数和浮点数那样,按照某个规则表示各种字符。但各种字符不像整数和浮点数那样有规律,对于毫无规律的各种字符,不能单靠某几个规则确定各字符与二进制之间的转换关系,最简单的就是为每个字符赋予一个独一无二的编号(字符码),使用该字符编号来表示该字符,如果要显示该字符,通过该字符编号查询对应的字符表(字符集),就可以获取该字符的显示点阵信息。
字符码跟字符集是配合使用的,二者共同构成一套字符编码方案,同一个字符在不同字符集中的字符码可能是不同的。最常用的字符集是ASCII (American Standard Code for Information Interchange),其中包含了最常用的英文字母、数字、特殊符号、控制字符等共128 个字符,这些字符码可以使用7 个二进制位来表示,早期通讯不是很可靠,字符码加了一个二进制位用于奇偶校验,因此使用8 个二进制位来表示一个ASCII 字符。
八个二进制位正好可以由两个十六进制位来表示,且正好可用来表示一个ASCII 字符,因此常将8 个二进制位组合起来使用,称为八位组Octet 或者字节Byte,前面介绍的各种数据类型使用的二进制位数也都是Octet 或Byte 的整数倍。
我们已经知道计算机通过字符码来存储和处理字符信息(计算机中应存储对应的字符集),字符码实际上是无符号整数,自然也可以使用多位二进制来表示。计算机怎么知道char 表示的是整数还是字符码呢?对一个char 类型变量可以从赋值和输出两个角度看:如果是以单引号括起来的形式赋值(比如char c = ‘1’;),则char 变量存储的是字符1的编码值;如果以%c 格式解释char 变量值,计算机将char 变量值当作字符码,查询ASCII 字符集获得对应的字符点阵信息再输出显示,如果以%d 格式解释char 变量值,则计算机将char 变量值当作整数输出显示。
ASCII 字符集只能表示128 个字符,肯定无法满足我们的使用需求,因此有各种扩展字符集,使用多个字节来表示一个字符(可参考博文:字符编码的设计与演进)。目前国际上使用最广泛的是UTF-8 编码,国内使用比较多的是GB18030 编码:
- UTF-8 编码:目前在国际上使用最广泛,UTF-8 使用1 字节表示ASCII 字符,使用2 字节表示欧洲语言字符(比如拉丁文、希腊文等字符),使用3 字节表示亚洲语言字符(比如中日韩文、东南亚文等字符),使用4 字节表示其它不常用字符;
- GB18030 编码:目前在国内使用比较多,GB18030 使用1 字节表示ASCII 字符,使用2 字节表示亚洲语言字符(比如中日韩文、东南亚文等字符),使用4 字节表示其它不常用字符(比如一些古文字、生僻字等);
- UTF-16 编码:至少使用16 个二进制位来表示一个字符,也即对常用的Unicode BMP 字符使用2 字节表示,对于不常用的Unicode BMP 以外的字符使用4 字节表示,UTF-16 对于英文字符也需要2 字节表示,因此不兼容ASCII 字符集,且存储和传输英文字符将占用更多资源。UTF-16 分大端和小端两种字节序,也即UTF-16LE 和UTF-16BE,windows 系统默认使用UTF-16LE 编码(Linux 系统默认使用UTF-8 编码)。
在欧美地区,使用UTF-8 编码可以用更少的二进制位来表示常用字符,也就可以节省不少存储资源和传输带宽。在亚洲地区,使用UTF-8 编码表示一个汉字需要 3 Bytes,使用GB18030 编码表示一个汉字只需要2 Bytes,如果汉字比较多,使用GB18030 字符集存储和传输中文字符更高效。
UTF-8 和GB18030 使用多个字节来表示一个字符,属于变长多字节字符编码,在存储和传输字符信息时比较节省资源,因此在磁盘存储和网络传输中应用比较广泛。但变长字节编码不利于计算机处理,计算机每遇到一个字符还要判断该字符由多少个二进制位表示会影响处理效率,因此操作系统在内存中处理字符时,通常先将其转换为定长编码字符(比如UCS-2 或UTF-32)再处理,编程语言也为多于1 字节编码的字符提供了宽字符类型wchar_t,告诉计算机该字符需要多少个二进制位表示。
宽字符类型wchar_t 在不同的操作系统中长度也不同,在windows 系统中使用16 个二进制位表示一个宽字符,在linux 系统中使用32 个二进制位表示一个宽字符。为了避免跨平台移植遇到问题,C11 新提供了char16_t 和char32_t 两种定宽字符类型(见头文件 <uchar.h>),下面给出C 语言支持的字符类型:
| 类型 | 描述 |
|---|---|
| char | 单字节字符,使用8 个二进制位表示一个字符,比如ASCII 字符集。 |
| wchar_t | 宽字节字符,使用16 位(比如windows 系统)或32 位(比如linux 系统)二进制表示一个字符。 |
| char16_t | 双字节字符,使用16 个二进制位表示一个字符,比如UTF-16 / UCS-2 字符集。 |
| char32_t | 四字节字符,使用32 个二进制位表示一个字符,比如UTF-32 / UCS-4 字符集。 |
由于这些字符类型变量存储的都是字符编码,字符编码也是整数,这些字符类型实际上是特定宽度的整数类型别名,在windows 和linux 系统中字符类型的定义如下:
//windows系统
typedef unsigned short wchar_t;
typedef uint_least16_t char16_t;
typedef uint_least32_t char32_t;
//linux系统
typedef int wchar_t;
typedef unsigned short char16_t;
typedef unsigned int char32_t;
计算机一般都是按字节寻址和读写的,对于宽度超过一个字节的数据类型,高字节是存储在高地址还是低地址呢?不同的计算机对此的处理并不一致,这就引出了大端字节序和小端字节序的问题:
- 大端字节序(BE: Big Endian):高位字节在前,低位字节在后,比较符合人类读写数据的习惯,IETF 规定网络传输都使用大端字节序(网络字节序);
- 小端字节序(LE: Little Endian):低位字节在前,高位字节在后,计算机进行数值计算先处理低位字节效率更高,常见的x86、ARM 等处理器都默认小端字节序(主机字节序);
前面介绍的宽度超过1 字节的数据类型都存在字节序的问题,对于UTF-16 和UTF-32 这类宽字符编码,如果存储和解析的字节序不一致就会解析出不同的字符导致信息传达错误,因此常在文件开头添加一个BOM(Byte Order Mark),让计算机能正确识别字符编码字节序并正确解释字符信息(比如UTF-16LE BOM为FF FE,UTF-16BE BOM 为FE FF)。不同的计算机通过互联网传输信息时,也需要统一字节序,IETF 规定网络传输统一使用大端字节序,主机借助互联网收发信息都需要进行主机字节序与网络字节序的转换。
二、常见的字符操作
对于整数和浮点数类型,最常用的是各种数学计算,比较基本的是直接通过算术、关系等运算符直接处理,稍微复杂点的是指数函数、幂函数、三角函数、双曲函数等常用数学函数计算,C 标准库在头文件<math.h> 和<complex.h> 中提供了常用的整数、浮点数、复数的数学计算函数,我们可以直接调用库函数完成常见的数值计算。对于字符类型,并不适合各种数学计算,我们常对其执行哪些处理或操作呢?
2.1 字符类型识别与大小写转换
在跟人交互的文件中存储的信息一般都是字符形式,文件中的数值也需要转换为字符才可以显示出来,计算机如果要处理文件中的数值,需要识别并将其转换为整数或浮点数类型才方便后续计算。因此,识别字符类别、字符格式与数值格式之间的转换,是两种基本的字符操作。
计算机怎么识别字符类别呢?字符型变量内保存的都是字符编码,同一类别的字符编码通常都在一个编码区间范围,我们只需要判断该字符编码在哪个区间范围,就可以识别出该字符类型,C 语言提供的识别字符类型的库函数如下(见头文件<ctype.h>):
| 识别字符类型库函数 <ctype.h> | 功能描述 |
|---|---|
| int isalnum(int c) | 若传入字符为字母或数字字符,则返回非零,否则返回 0。 |
| int isalpha(int c) | 若传入字符为字母,则返回非零,否则返回 0。 |
| int islower( int ch ) | 若传入字符为小写字母,则返回非零,否则返回 0。 |
| int isupper( int ch ) | 若传入字符为大写字母,则返回非零,否则返回 0。 |
| int isdigit( int ch ) | 若传入字符为十进制数字字符,则返回非零,否则返回 0。 |
| int isxdigit( int ch ) | 若传入字符为十六进制数字字符,则返回非零,否则返回 0。 |
| int iscntrl( int ch ) | 若传入字符为控制字符,则返回非零,否则返回 0。 |
| int isgraph( int ch ) | 若传入字符为可显示字符,则返回非零,否则返回 0。 |
| int isspace( int ch ) | 若传入字符为空白字符,则返回非零,否则返回 0。 空白字符指的是空格、换行、回车、水平/垂直制表符等。 |
| int isblank( int ch ) | 若传入字符为空格符,则返回非零,否则返回 0。 |
| int isprint( int ch ) | 若传入字符为可打印字符,则返回非零,否则返回 0。 |
| int ispunct( int ch ) | 若传入字符为标点字符,则返回非零,否则返回 0。 |
| int tolower( int ch ) | 若传入字符为大写字母,则返回其对应的小写字母,否则不修改传入字符。 |
| int toupper( int ch ) | 若传入字符为小写字母,则返回其对应的大写字母,否则不修改传入字符。 |
宽字符类型只是字符编码占用了更多字节,对宽字符的操作处理跟单字节字符(也称窄字符)类似,重点就是每个字符占用的二进制位数不同了。C 语言也为宽字符操作提供了一系列库函数,详见头文件<wchar.h>、<wctype.h> 和<uchar.h>,本文就不赘述了。
2.2 字符格式与数值格式转换
一般文件中存储的整数或浮点数都是十进制的,且不止一个十进制位,如果将一个十进制整数或浮点数转换为字符格式,通常每一个十进制位都需要一个字符表示,一个完整的十进制数通常需要多个字符或一个字符数组共同表示。如果用字符数组表示一个完整的整数或浮点数,在传参时通常需要数组指针和数组长度两个参数,如果在字符数组尾部添加一个结束标记,程序就可以自动计算字符数组的长度,使用 ‘\0’ 空字符终止的一维字符数组称为字符串。
单字节字符串转换为数值格式的库函数如下(见头文件<stdlib.h>):
/** 将传入的空终止字符串转换为一个十进制整数值(只转换'+'、'-'、'0'~'9'),* 若转换成功则返回转换后的整数值,若无法转换则返回0,* 若转换后的整数值超出返回类型范围极限则返回未定义的值。*/
int atoi( const char *str );
long atol( const char *str );
long long atoll( const char *str );/** 将传入的空终止字符串转换为一个十进制浮点值(只转换'+'、'-'、'.'、'e'、'E'、'0'~'9'),* 若转换成功则返回转换后的浮点值,若无法转换则返回0,* 若转换后的浮点值超出返回类型范围极限则返回未定义的值。 */
double atof( const char* str );/** 将传入的空终止字符串转换为一个整数值,转译哪些字符跟设置的进制有关* @param str: 指向要被转译的空终止字符串的指针,restrict 用于限定和约束指针,并表明指针是访问一个数据对象的唯一且初始的方式。* @param str_end: 指向的指针指向最后被转译字符的后一个字符,若未发生转换则指向str,若传入空指针则忽略该参数。* @param base: 期望转换为整数值的底或进制数,合法范围{0,2,3,...,36},若设为0 则自动检测数值进制,36 进制包含10个数字和26个字母(不区分大小写)。* @return : 若转换成功则返回转移后的整数值,若无法转换则返回0 并将 *str_end 设为 str ;* 若转换后的整数值超出返回类型范围极限则返回类型极限值,并设 errno 为 ERANGE。 */
long strtol( const char *restrict str, char **restrict str_end, int base );
long long strtoll( const char *restrict str, char **restrict str_end, int base );
unsigned long strtoul( const char *restrict str, char **restrict str_end, int base );
unsigned long long strtoull( const char *restrict str, char **restrict str_end, int base );/** 将传入的空终止字符串转换为一个浮点值* @param str: 指向要被转译的空终止字符串的指针,restrict 用于限定和约束指针,并表明指针是访问一个数据对象的唯一且初始的方式。* @param str_end: 指向的指针指向最后被转译字符的后一个字符,若未发生转换则指向str,若传入空指针则忽略该参数。* @return : 若转换成功则返回转移后的浮点值,若无法转换则返回0 并将 *str_end 设为 str ;* 若转换后的浮点值超出返回类型范围极限则返回类型极限值,并设 errno 为 ERANGE。 */
float strtof( const char *restrict str, char **restrict str_end );
double strtod( const char *restrict str, char **restrict str_end );
long double strtold( const char *restrict str, char **restrict str_end );
数值格式转换为单字节字符串的扩展库函数如下(非标准库函数,可参阅博文:windows 提供的 itoa 实现源码):
/** 将传入的整数值转换为字符串(windows 系统提供了,linux 系统并未提供)* @param value: 要被转换的整数值。* @param buf: 指向一段内存空间,用于存放转换后的字符串,该内存空间应是已分配且长度足够的。* @param base: 期望转换为底或进制数,合法范围{2,3,...,36},36 进制包含10个数字和26个字母(不区分大小写)。* @return : 返回转换后的字符串首地址,也即buf 指向的内存空间首地址。 */
char *itoa(int value, char *buf, int base);
char *ltoa(long value, char *buf, int base);
char *ultoa(unsigned long value, char *buf, int base);/** 将传入的浮点值转换为字符串(windows 系统和linux 系统均提供了)* @param value: 要被转换的浮点值。* @param buf: 指向一段内存空间,用于存放转换后的字符串,该内存空间应是已分配且长度足够的。* @param ndigits: 将浮点值转换为字符串的有效位数,超出部分舍去,gcvt 包含符号位和小数点,ecvt 不包含符号位和小数点。* @param ndec: 保留浮点值小数点的位数,也即转换精度。* @param decpt: 存储转换结果中小数点的位置。* @param sign: 存储转换结果中的符号位,0为正数,1为负数。* @return : 返回转换后的字符串指针,gcvt 返回字符串包含符号位和小数点,* ecvt 与 fcvt 返回字符串不包含符号位和小数点,需配合返回的decpt 与sign 值共同组成完整浮点数字符串。 */
char *gcvt(double value, int ndigits, char *buf);
char *ecvt(double value, int ndigits, int *decpt, int *sign);
char *fcvt(double value, int ndec, int *decpt, int *sign);
C 标准库默认并没有提供上述数值格式转换为单字节字符串的库函数,主要是因为该功能可以由函数sprintf 实现(见头文件<stdio.h>),示例如下:
#include<stdio.h>
#include<stdlib.h>int main(void)
{// 整数值转换为单字节字符串char buf1[32];long int a = -684565764;sprintf(buf1, "%ld", a);printf("The integer numeric string format: %s\n", buf1);// 浮点值转换为单字节字符串char buf2[32];double b = -5365.567246674;sprintf(buf2, "%f", b);printf("Floating-point value string format: %s\n", buf2);// 字符串转换为整数值或浮点值long int aa = strtol(buf1, NULL, 10);double bb = strtod(buf2, NULL);printf("The integer value = %ld, Floating point value = %f\n", aa, bb);return 0;
}
程序输出:

2.3 字符串常用操作
在 C 语言中,字符串实际上是使用空终止符 ‘\0’ 的一维字符数组,对线性数组的操作主要有增、删、改、查、排序等五种操作,下面依次介绍。
2.3.1 字符串与字符数组的比较操作
首先说字符串的排序,字符类型保存的是字符编码信息,字符码实际是无符号整型数据,自然可以对其进行排序(也即不同字符可通过编码值比较大小,最常用的是字典序)。
一般一个字符串表示的是一段有意义的信息,打乱原有的字符顺序,原有信息也就改变了,因此对一个字符串内的字符进行排序并不常用,更多的是多个字符串之间排序(比如词典中包含的单词都是按字典序排列的)。不管是多个字符串之间排序,还是单个字符串内的字符间排序,除了字符比较规则跟整数略有不同外,算法思想跟整数一致,排序算法在博文:排序算法分析与优化中已经介绍的很详细了,这里就不介绍字符串的排序操作了,只介绍字符串的比较操作:
/** 计算字符串 str 的长度,直到空结束字符,但不包括空结束字符。* @param str: 指向要检测的空终止字符串的指针。* @param strsz: 要检测的最大字符数量,提供边界检查功能,常设为 sizeof(str)。* @return : 返回空终止字节字符串 str 的长度,若 str 是空指针则返回零,若找不到空终止符则返回 strsz 。 */
size_t strlen( const char *str );
size_t strnlen_s( const char *str, size_t strsz ); //(C11 起)/** 按字典序自左向右逐个字符比较两个字符串的大小(strcoll 按照 LC_COLLATE 定义的当前本地环境限定的字符顺序进行比较)。* @param lhs: 指向要比较的第一个空终止字节字符串的指针(memcmp 只比较内存数据,不要求空终止符)。* @param rhs: 指向要比较的第二个空终止字节字符串的指针(memcmp 只比较内存数据,不要求空终止符)。* @param count: 要比较的最大字符数,strcmp 和strcoll 比较的最大字符数为min(strlen(lhs), strlen(rhs)),* strncmp 比较的最大字符数为min{count, strlen(lhs), strlen(rhs)},* memcmp 主要用于比较两个内存区间的数据不检查空终止符,count 指的是要比较的最大字节数。* @return : 若字典序(或本地限定字符序)中lhs 字符排在rhs 字符前则返回负值,排在之后则返回正值,位置相同或count 为0 则返回0。 */
int strcmp( const char *lhs, const char *rhs );
int strncmp( const char *lhs, const char *rhs, size_t count );
int strcoll( const char *lhs, const char *rhs );
int memcmp( const void* lhs, const void* rhs, size_t count );
字符串通常自带空终止符,因此可以通过检测空终止符来计算该字符串的长度,获取字符串长度可通过库函数strlen 或strnlen_s 完成。
需要注意的是,使用字符串操作函数处理没有空终止符的字节数组可能会因找不到空终止符导致缓冲溢出或访问越界。字符串会在遇到的第一个空终止符处结束,使用字符串操作函数处理包含多个空字符的字节数组时只能处理第一个空字符(’\0’)前的字符。对于上述两种情况,可以使用内存操作函数比如memcmp 来处理这类字符数组。
2.3.2 字符串与字符数组的插入操作
字符串和字符数组都属于线性数组的顺序存储结构,该结构决定了字符串或字符数组从中间插入元素比较低效,需要将后面的元素全部后移,直接在尾部插入数据相对高效些。字符串拼接操作使用也更加频繁,因此C 语言标准库提供了字符串拼接函数如下:
/** 把 src 所指向的空终止字符串追加到 dest 所指向的空终止字符串的结尾。* @param dest: 指向要拼接或后附到的目标空终止字节字符串的指针,dest指向的内存空间应足够容纳追加的字符数量。* @param src: 指向作为复制来源的空终止字节字符串的指针,若src与dest指向的内存空间重叠结果可能是非预期的。* @param count: 要追加的最大字符数,实际追加字符数为min(count, strlen(src))。* @param destsz: 目标缓冲区的大小sizeof(dest),防止dest 指向的内存空间发生缓冲区溢出错误。* @return : 前两个函数返回dest的副本,后两个函数返回错误码(如果执行成功返回0,若发生错误则返回非零,并写入'\0'到 dest[0])。 */
char *strcat( char *restrict dest, const char *restrict src );
char *strncat( char *restrict dest, const char *restrict src, size_t count );
errno_t strcat_s(char *restrict dest, rsize_t destsz, const char *restrict src); //(C11 起)
errno_t strncat_s(char *restrict dest, rsize_t destsz, const char *restrict src, rsize_t count); //(C11 起)
上述字符串拼接函数都要求dest 和src 为空终止字符串,要追加字符的目标字符串dest 是从末尾的空终止符开始追加的(也即dest[strlen(dest)] = src[0]),而且dest 指向的内存区间应足够容纳要追加的字符数量。
为防止dest 指向的缓冲区发生溢出,C11 新增了两个函数strcat_s 和strncat_s,通过增加一个参数destsz 限定目标缓冲区长度解决该问题,若(destsz - strlen(dest) - 1) < min(count, strlen(src)) 则会返回非零错误码并写入’\0’到 dest[0]。
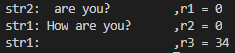
如果想往目标字符串中间插入一段字符怎么实现呢?可以先将待插入的字符串和目标字符串插入点后面的字符串拼接起来组成新的待追加源字符串,然后再将新的源字符串追加到目标字符串后面即可,目标字符串插入点处需要设置为空终止符,以便上述函数能正确找到字符追加位置,下面给出一段示例代码:
#include<stdio.h>
#include<string.h>int main(void)
{// 在str 中间插入子串str2char str1[20] = "How you?";char str2[20] = " are ";int r1 = strcat_s(str2, sizeof(str2), str1 + 4);printf("str2: %s\t\t,r1 = %d\n", str2, r1); //这里使用制表符\t是为了对齐str1[3] = '\0';int r2 = strcat_s(str1, sizeof(str1), str2);printf("str1: %s\t,r2 = %d\n", str1, r2);// 若追加字符数量超出str 缓冲区则返回非零错误码并写入'\0'到str[0]char str3[] = "GoodBye!";int r3 = strncat_s(str1, sizeof(str1), str3, strlen(str3));printf("str1: %s\t\t\t,r3 = %d\n", str1, r3);return 0;
}
程序输出:
上面的示例程序中r3 返回的是错误码errno,我们知道errno == 0 表示没有错误,非零值有错误,但每个错误码是什么意思呢?C 库函数为我们提供了一个函数char* strerror( int errnum ) 来获得错误码对应的描述信息,使用该函数修改上面的示例程序如下:
#include<stdio.h>
#include<string.h>
#include<errno.h>int main(void)
{// 在str 中间插入子串str2char str1[20] = "How you?";char str2[20] = " are ";int r1 = strcat_s(str2, sizeof(str2), str1 + 4);printf("str2: %s\t\t,r1 = %s\n", str2, strerror(r1)); //这里使用制表符\t是为了对齐str1[3] = '\0';int r2 = strcat_s(str1, sizeof(str1), str2);printf("str1: %s\t,r2 = %s\n", str1, strerror(r2));// 若追加字符数量超出str 缓冲区则返回非零错误码并写入'\0'到str[0]char str3[] = "GoodBye!";int r3 = strncat_s(str1, sizeof(str1), str3, strlen(str3));printf("str1: %s\t\t\t,r3 = %s\n", str1, strerror(r3)); //使用strerror函数获取errno对应的描述信息return 0;
}
程序输出:

2.3.3 字符串与字符数组的修改操作
对字符串和字符数组的修改主要是通过字符替换完成的,单个字符的替换比较简单,直接修改字符数组对应的元素值即可,比如上面示例中的str[3] = ‘\0’,但不能修改字符串常量,比如char *str = “hello” 指针str指向的就是一个不可修改的字符串常量。
对目标字符串或字符数组中多个字符的替换主要分两种情况:一种是将多个字符替换为一个相同的字符或数值(比如memset);另一种是使用另外一个字符串替换原字符串或其子串,表现为字符串的复制(比如strcpy/memcpy)。C 语言提供的字符串修改函数如下:
/** 把 src 所指向的空终止字符串复制到 dest 所指向的内存区间。* @param dest: 指向要写入的字符数组的指针,dest指向的内存空间应足够容纳复制的字符数量。* @param src: 指向要复制的空终止字节字符串的指针,若src 和dest 内存重叠则结果可能是非预期的。* @param count: 要复制的最大字符数,若strlen(src) < min(count, destsz) 则其后写入空字符直到复制min(count, destsz)个字符。* @param destsz: 目标缓冲区的大小sizeof(dest),防止dest 指向的内存空间发生缓冲区溢出错误。* @return : 前两个函数返回dest的副本,后两个函数返回错误码(如果执行成功返回0,若发生错误则返回非零,并写入'\0'到 dest[0])。 */
char *strcpy( char *restrict dest, const char *restrict src );
char *strncpy( char *restrict dest, const char *restrict src, size_t count );
errno_t strcpy_s(char *restrict dest, rsize_t destsz, const char *restrict src); //(C11 起)
errno_t strncpy_s(char *restrict dest, rsize_t destsz, const char *restrict src, rsize_t count); //(C11 起)/** 将src 指向的count 个字节或count 个ch 值复制或填充到dest 所指向的内存空间。* @param dest: 指向要复制或填充的目标对象或内存区间的指针,dest指向的内存空间应不小于count 个字节。* @param src: 指向作为复制来源对象或内存空间的指针,memcpy(_s)若src 和dest 内存重叠则结果可能是非预期的。* memmove(_s)考虑了内存重叠的情况,先将src复制到临时数组,再从该数组复制到dest,两次复制降低了效率增加了额外的内存开销。* @param count: 要复制的字节数,若count 大于src 或dest 指向的内存空间长度都可能带来非预期的结果。* @param destsz: 目标缓冲区的大小sizeof(dest),防止dest 指向的内存空间发生缓冲区溢出错误。* @return : 非C11版本返回dest的副本,C11版本返回错误码(如果执行成功返回0,若发生错误则返回非零,并写入destsz个'\0'到 dest 内存区间)。 */
void *memset( void *dest, int ch, size_t count );
errno_t memset_s( void *dest, rsize_t destsz, int ch, rsize_t count ); //(C11 起)
void* memcpy( void *restrict dest, const void *restrict src, size_t count );
errno_t memcpy_s( void *restrict dest, rsize_t destsz, const void *restrict src, rsize_t count ); //(C11 起)
void* memmove( void* dest, const void* src, size_t count );
errno_t memmove_s(void *dest, rsize_t destsz, const void *src, rsize_t count); //(C11 起)
函数strcpy(_s)要求src 指向空终止字符串的指针,并以此作为复制结束的判断标识。函数strncpy复制count 个字符,若未复制到空终止符,该函数不会自动添加’\0’,此时dest 可能是一个没有空终止符的字符数组,用户可在dest 结尾手动添加’\0’ 使其称为字符串。函数strncpy_s 复制min(count, destsz) 个字符,即便未复制到空终止符,也会在其后自动添加’\0’(空字符不计入count),用户若以字符串操作dest,其后未被覆盖的数据将丢失。
函数memcpy(_s) 若出现dest 与src 重叠的情况(比如src < dest < src + strlen(src)),可能会带来非预期的结果,memmove(_s) 借助临时数组二次拷贝的方式避免内存重叠问题,但也降低了效率并增加了内存空间占用。读者可以自己实现一个函数,当src < dest < src + strlen(src)时从末尾往前反向复制,其余情况从首部往后正向复制,可以在不降低效率的情况下避免内存重叠问题。
上述函数虽然是从dest 指向的内存空间首地址开始修改的,也可以通过将dest 指向要修改的字符串或字符数组中间修改点(比如dest = str + pos)只修改字符串或字符数组的后半部分或中间一段,下面给出一段示例代码:
#include<stdio.h>
#include<string.h>int main(void)
{// 使用strncpy修改str中间部分字符不自动添加'\0',使用strncpy_s修改str2中间部分字符会自动添加'\0'char str[20] = "www.google.com";char str2[20] = "www.bing.com";strncpy(str + 4, str2 + 4, 4);printf("str: %s\t,str2: %s\n", str, str2);int r1 = strncpy_s(str2 + 4, sizeof(str2) - 4, str + 4, 5);printf("str: %s\t,str2: %s\t,r1 = %d\n", str, str2, r1);// memmove可处理内存重叠的情况,使用memset将str2中间的'\0'替换为' '则会与后面未被覆盖的字符连起来int r2 = memmove_s(str + 8, sizeof(str2) - 8, str + 10, 6);memset(str2 + 9, ' ', 1);printf("str: %s\t,str2: %s\t,r2 = %d\n", str, str2, r2);return 0;
}
程序输出:

2.3.4 字符串与字符数组的查找操作
在一个字符数组或字符串内查找一个字符比较简单,一般需要遍历该字符数组或字符串,若字符编码匹配就算找到了。C 语言提供的查找单个字符的库函数如下:
/** 在 str 所指向的空终止字符串或ptr 所指向的内存空间中查找字符ch 首次(strchr/memchr)或最后一次(strrchr反向查找)出现的位置。* @param str: 指向待查找的空终止字节字符串的指针。* @param ch: 要查找的字符(unsigned char类型),也可以是'\0'。* @param ptr: 指向要查找的对象或内存空间的指针。* @param count: 要检验的最大字节数,若count 大于ptr 指向内存空间的长度可能会带来非预期的结果。* @return : 若找到目标字符ch 则返回指向该字符的指针,否则返回空指针。 */
char *strchr( const char *str, int ch );
char *strrchr( const char *str, int ch );
void* memchr( const void* ptr, int ch, size_t count );
如果待查找字符不止一个,而是一个集合(比如char target[]),也即在要查找的目标空终止字符串(比如char dest[])中查找第一个包含或未包含在目标字符集合target 中的字符,比上面查找单个字符更复杂些。可以反向思考,拿dest 字符串中的字符逐个在target 字符串中查找,若未到达期望结果在dest 字符串中取下一个字符继续查找,直到达成预期结果或dest 字符串中的字符查找完毕为止,该算法的时间复杂度为O(n * m)(n和m分别是dest 和target 的字符数量)。C 语言提供的查找字符集合的库函数如下:
/** 在 dest 所指向的空终止字符串中查找第一个不在(strspn)或在(strcspn/strpbrk)空终止字符串src 中出现的字符。* @param dest: 指向待查找的空终止字节字符串的指针。* @param src: 指向包含要查找字符集合的空终止字节字符串的指针。* @param breakset: 指向包含要查找字符集合的空终止字节字符串的指针。* @return : 前两个函数返回dest中第一个不在(strspn)或在(strcspn)src中出现的字符下标,若未找到则返回空终止符的下标(也即strlen(dest));* 函数strpbrk返回指向dest中第一个包含在breakset中的字符指针(不匹配breakset中的空终止符),若未找到则返回空指针。 */
size_t strspn( const char *dest, const char *src );
size_t strcspn( const char *dest, const char *src );
char* strpbrk( const char* dest, const char* breakset );
在一个字符串中查找包含在另一个字符串中的字符属于字符串匹配问题,函数strspn(string span)是在dest 字符串中查找第一个不能匹配字符串src 中任一字符的字符下标(也可以理解为dest 中连续能匹配src 中任一字符的字符数量),函数strcspn(string complementary span)是在dest 字符串中查找第一个能匹配字符串src 中任一字符的字符下标(也可以理解为dest 中连续能匹配src 补集中任一字符的字符数量),函数strpbrk(string pointer break)是在dest 字符串中查找第一个能匹配字符串breakset 中任一字符(不包括空终止符)的字符位置。
上述在一个字符串dest 中查找另一个字符集合src 中字符的问题,使用上述思路查找的时间复杂度是O(n * m),如果想进一步提高查找效率,可以借助Hash Table 优化,将要查找的字符集合src 插入Hash Table 中(比如将字符编码作为数组元素下标,该字符是否存在的布尔值作为该下标对应的元素值,类似技巧可参阅:计数排序算法),后续只需要查询dest 中的每个字符是否包含在该哈希表中,哈希表的查找时间复杂度为O(1),加上构建哈希表的时间,借助哈希表实现的查找算法时间复杂度为O(n + m),C 标准库提供的上述函数也正是采用了该实现思路。
字符串匹配问题中,除了上述提到的匹配任一字符,还有一种字符串全匹配问题,比如在一个字符串中查找是否包含某个单词,实际上就是在目标字符串中查找能完全匹配子字符串的字符区间,C 语言提供的字符串全匹配函数如下:
/** 在 str 所指向的空终止字符串中查找第一次能全匹配字符串substr(不包含空终止符)的位置。* @param str: 指向待查找的空终止字节字符串的指针。* @param substr: 指向要匹配的空终止字节字符串的指针。* @return : 指向str中能全匹配子串substr的首字符的指针,若未找到则返回空指针。 */
char *strstr( const char* str, const char* substr );
函数strstr 的早期实现版本采用的是Brute Force 匹配算法,先在str 中匹配substr 的第一个字符,如果找到了看后续字符是否能匹配,若遇到不能匹配的字符再重头开始匹配substr 的第一个字符,不过str 中与substr 首字母对应的字符及其之前的字符已经匹配过了,从其下一个字符开始匹配,Brute Force 字符串匹配算法原理图示如下:

字符串Brute Force匹配算法比较低效,时间复杂度为O(n * m),其中n、m 分别为字符串str 和子串substr 的字符数量,原理和代码实现都比较简单。在实际软件开发中,大部分情况下字符串及其子串都不会太长(特别是模式串长度m 较小时,BF 算法时间复杂度接近线性),因此这个字符串匹配算法也是够用的。
如果要匹配的字符串及其子串都比较长,且对执行效率要求比较高,可以考虑使用KMP (Knuth Morris Pratt) 匹配算法或BM (Boyer-Moore) 匹配算法,其时间复杂度为O(n + m)。C 标准库函数strstr 后来的实现版本采用了 two-way 字符串匹配算法以提高效率,双向字符串匹配算法可以看作是向前的KMP 算法和向后的BM 算法的组合,虽然时间复杂度仍为O(n + m),但在工程上有更高的效率。
下面给出一段字符串查找匹配函数应用的示例代码:
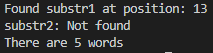
#include<stdio.h>
#include<string.h>int main(void)
{const char* str = "hello world, friend of mine!";const char* sep = " ,!";// 在str 中全匹配子字符串char* pos1 = strstr(str, "friend");(pos1 == NULL) ? puts("substr1: Not found") : printf("Found substr1 at position: %ld\n", pos1 - str);char* pos2 = strstr(str, "friendly");(pos2 == NULL) ? puts("substr2: Not found") : printf("Found substr2 at position: %ld\n", pos2 - str);// 统计str 中的单词数量unsigned int cnt = 0;do {str = strpbrk(str, sep); // 寻找分隔符if(str) str += strspn(str, sep); // 跳过分隔符++cnt; // 增加单词计数} while(str != NULL && *str != '\0');printf("There are %d words\n", cnt);return 0;
}
程序输出:
2.3.5 字符串的分割操作
字符串除了上述介绍的增、删、改、查、排序五种操作外,还有一种比较常见的分割操作,比如我们将一个句子分割为一个个单词。在数据处理中,比如excel 通过特定分隔符(比如’;‘或’,’)将一行数据分割成多列等。字符串分割操作通过前面介绍的strpbrk 函数也能实现,上述示例程序中统计单词数量的代码就实现了字符串分割操作,只不过我们没有输出每个单词,只是统计了单词个数。C 语言还提供了一个分割效率更高的函数如下:
/** 将 str 所指向的空终止字符串分割为一组子字符串(也即token),该函数被设计为调用多次以便从同一字符串获得相继的token。* @param str: 指向要分割的空终止字节字符串的指针(该函数会修改str字符串,因此不能传入字符串常量);* 在首次调用时传入str,后继调用传入空指针(函数会自动记录剩余待处理字符串的位置)。* @param delim: 指向包含分隔符的空终止字节字符串的指针,若在str中找到delim中的任一分隔符,则将其替换为'\0'(用于将token分割为子字符串)。* @param ptr: 指向 char* 类型对象的指针,在后继调用中用来传递指向剩余待处理字符串的指针。* 函数strtok在内部使用一个静态指针变量存储该信息,因静态变量线程不安全strtok_s新增该参数改进。* @return : 返回指向token(被分隔符分割出来的字符数组)起始的指针,若无更多token则返回空指针。 */
char *strtok( char *restrict str, const char *restrict delim );
char *strtok_s(char *restrict str, const char *restrict delim, char **restrict ptr); //(C11 起)
函数strtok(_s)被设计为调用多次以便从同一字符串获得相继的token,token 实际上是被分隔符分割而成的一个个字符数组。这两个函数的后继调用都是在str 参数位置传入空指针,只在首次调用传入字符串指针str,主要是因为函数会自动保存前一次的调用状态(也即指向剩余待处理字符串的指针),函数strtok 是在内部使用一个静态指针变量来存储前一次的调用状态信息,但静态变量是线程不安全的,C11 新增函数strtok_s 使用额外的参数ptr 来存储前一次的调用状态信息,使用用户传入的指针变量避免线程不安全风险。
下面给出一段字符串分割函数应用的示例代码:
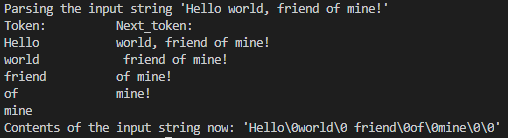
#include<stdio.h>
#include<string.h>int main(void)
{ char str[] = "Hello world, friend of mine!";const char delim[] = " ,!"; // 分隔符集合char* next_token = NULL;printf("Parsing the input string '%s'\n", str);char* token = strtok_s(str, delim, &next_token); // 首次调用printf("Token:\t\tNext_token:\n");while(token != NULL) {printf("%s\t\t%s\n", token, next_token); // 分别输出token 和next_token 字符串,更方便理解nect_token 参数作用token = strtok_s(NULL, delim, &next_token); // 后继调用首参数传入空指针}// 输出字符串全部字符,可看到原字符串中的分隔符均被替换为了'\0'printf("Contents of the input string now: '");for(size_t n = 0; n < sizeof(str); ++n)(str[n] != '\0') ? putchar(str[n]) : fputs("\\0", stdout);puts("'");return 0;
}
程序输出:
本文示例代码下载地址:https://github.com/StreamAI/ADT-and-Algorithm-in-C/tree/master/string
更多文章:
- 《Data Structures and Algorithm analysis Sample Source Code》
- 《数据结构与算法分析(十六)— 字符串匹配算法 + 效率优化(BF + RK + KMP + BMH)》
- 《字符编码的设计与演进(ASCII,Unicode,UTF-8,GB18030…)》
- 《数据结构与算法分析(十五)— String 和Regex 支持的字符处理操作(C++11)》
- 《数据结构与算法分析(十二)— 怎么实现并用好一个堆或优先队列?》
- 《数据结构与算法分析(一)— 数据结构的本质 + 线性表的实现》
这篇关于数据结构与算法分析(十四)--- 字符串和字符处理函数库(C11)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





